
ホームページ >データベース >mysql チュートリアル >MySQL のクエリ オプティマイザーの詳細な分析 (動作原理の詳細な説明)
MySQL のクエリ オプティマイザーの詳細な分析 (動作原理の詳細な説明)

- 青灯夜游転載
- 2022-07-04 20:35:073696ブラウズ
この記事では、MySQL のクエリ オプティマイザーの詳細な分析を提供し、mysql クエリ オプティマイザーの動作原理を理解するのに役立ちます。

SQL ステートメントの場合、クエリ オプティマイザーはまず JOIN に変換できるかどうかを確認し、次に JOIN を最適化します。 : 1. 条件の最適化、2. フルテーブルスキャンのコストを計算、3. 使用できるすべてのインデックスを検索、4. 各インデックスのさまざまなアクセス方法のコストを計算、5. コストが最小のインデックスを選択し、アクセス方法
1. クエリ オプティマイザーのログをオンにする#-- 开启
set optimizer_trace="enabled=on";
-- 执行sql
-- 查看日志信息
select * from information_schema.OPTIMIZER_TRACE;
-- 关闭
set optimizer_trace="enabled=off";
##2. オプティマイザーの原則
#1. 定数転送 (constant_propagation) a = 1 AND b > a
上記の SQL は次のように変換できます:- a = 1 AND b > 1
-
a = 5 および b = 5 および c = 5
# #2、等しい値の転送 (equality_propagation)
a = b および b = c および c = 5
上記の SQL は次のように変換できます: -
a = 1
3. 不要な条件を削除する (trivial_condition_removal)
a = 1 および 1 = 1
上記の SQL は次のように変換できます: -
InnoDB ストレージ エンジンはデータとインデックスの両方をディスクに保存します。テーブル内のレコードをクエリする場合は、まずデータまたはインデックスをメモリにロードしてから操作する必要があります。ディスクからメモリへの読み込みプロセスで失われる時間を I/O コスト
4. コストに基づく
クエリにはさまざまな実行プランを含めることができます。クエリするインデックスを選択することも、テーブル全体のスキャンを選択することもできます。クエリ オプティマイザーは、最もコストの低いプランを選択します。クエリを実行します。
1) I/O コスト 2) CPU コスト - レコードを読み取って、対応する検索条件を満たしているかどうかを確認したり、結果セットをソートしたりするコスト。時間は CPU コストと呼ばれます。
InnoDB ストレージ エンジンでは、ページの読み取りコストはデフォルトで 1.0、レコードが検索条件を満たしているかどうかの読み取りとチェックのコストはデフォルトで 0.2 と規定されています。
以下では、例を使用してこれらの手順を分析します。単一のテーブル クエリ ステートメントは次のとおりです:
3. コストベースの最適化手順
単一テーブルのクエリ ステートメントが実際に実行される前に、MySQL のクエリ オプティマイザーはステートメントの実行に使用されるすべての可能なオプションを見つけます。ソリューションを比較した後、最もコストの低いソリューションを見つけます。この最もコストの低いソリューションは、いわゆる実行プランです。その後、ストレージ エンジンによって提供されるインターフェイスが呼び出され、実際にクエリが実行されます。
select * from employees.titles where emp_no > '10101' and emp_no < '20000' and to_date = '1991-10-10';1. 検索条件に基づいて、可能なすべてのインデックスを検索します
• emp_no > '10101'、この検索条件では主キー インデックス PRIMARY を使用できます。 • to_date = ‘1991-10-10’、この検索条件ではセカンダリ インデックス idx_titles_to_date を使用できます。 要約すると、上記のクエリ ステートメントで使用できるインデックス、つまり使用可能なキーは PRIMARY と idx_titles_to_date だけです。
2. フル テーブル スキャンのコストを計算する
InnoDB ストレージ エンジンの場合、フル テーブル スキャンとは、レコードが比較されることを意味します。指定された検索条件で順番に検索し、検索条件を満たすレコードが結果セットに追加されるため、クラスター化インデックスに対応するページをメモリにロードし、レコードが条件を満たすかどうかを確認する必要があります。検索条件。クエリ コスト = I/O コストおよび CPU コストであるため、テーブル全体のスキャンのコストを計算するには 2 つの情報が必要です: 1) クラスター化インデックスが占有するページ数 2) テーブルのページ数 レコード数
MySQL はテーブルごとに一連の統計情報を保持しているため、テーブルの統計情報を表示するには SHOW TABLE STATUS ステートメントを使用します。
SHOW TABLE STATUS LIKE 'titles';Rows テーブル内のレコードの数を示します。この値は、MyISAM ストレージ エンジンを使用するテーブルでは正確であり、InnoDB ストレージ エンジンを使用するテーブルの推定値です。
Data_length テーブルが占有する記憶領域のバイト数を示します。 MyISAM ストレージ エンジンを使用するテーブルの場合、この値はデータ ファイルのサイズです。InnoDB ストレージ エンジンを使用するテーブルの場合、この値はクラスター化インデックスが占有するストレージ スペースに相当します。つまり、値は次のように計算できます。サイズ:
Data_length = 聚簇索引的页面数量 x 每个页面的大小タイトルではデフォルトのページ サイズ 16KB が使用されており、上記のクエリ結果では Data_length の値が 20512768 であることが示されているため、クラスター化インデックスのページ数を逆に推定できます。
聚簇索引的页面数量 = Data_length ÷ 16 ÷ 1024 = 20512768 ÷ 16 ÷ 1024 = 1252
クラスタ化インデックスが占有するページ数とテーブル内のレコード数の推定値が得られたので、テーブル全体のスキャンのコストを計算できます。ただし、MySQL は実際にコストを計算する際にいくつかの微調整を行います。 I/O コスト: 1252
1 = 1252。1252 はクラスター化インデックスが占有するページ数を指し、1.0 はページをロードするコスト定数を指します。
CPU コスト: 442070
0.2=88414。442070 は統計データのテーブル内のレコード数を指します。これは InnoDB ストレージ エンジンの推定値です。0.2 はそれを指しますto レコードにアクセスするために必要なコスト定数合計コスト: 1252 88414 = 89666。
要約すると、タイトルの完全なテーブル スキャンに必要な総コストは 89666 です。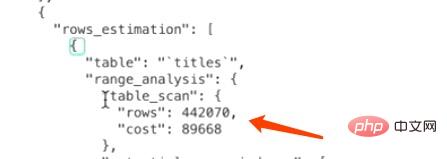
我们前边说过表中的记录其实都存储在聚簇索引对应B+树的叶子节点中,所以只要我们通过根节点获得了最左边的叶子节点,就可以沿着叶子节点组成的双向链表把所有记录都查看一遍。也就是说全表扫描这个过程其实有的B+树内节点是不需要访问的,但是MySQL在计算全表扫描成本时直接使用聚簇索引占用的页面数作为计算I/O成本的依据,是不区分内节点和叶子节点的。
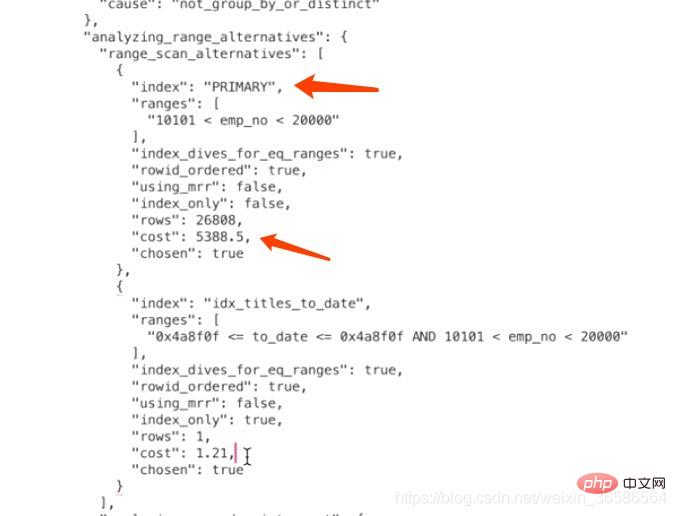
3、计算PRIMARY需要成本
计算PRIMARY需要多少成本的关键问题是:需要预估出根据对应的where条件在主键索引B+树中存在多少条符合条件的记录。
范围区间数
当我们从索引中查询记录时,不管是=、in、>、 本例中使用PRIMARY的范围区间只有一个:(10101, 20000),所以相当于访问这个范围区间的索引付出的I/O成本就是:1 x 1.0 = 1.0
预估范围内的记录数
优化器需要计算索引的某个范围区间到底包含多少条记录,对于本例来说就是要计算PRIMARY在(10101, 20000)这个范围区间中包含多少条数据记录,计算过程是这样的:
步骤1:先根据emp_no > 10101这个条件访问一下PRIMARY对应的B+树索引,找到满足emp_no > 10101这个条件的第一条记录,我们把这条记录称之为区间最左记录。
步骤2:然后再根据emp_no
步骤3:如果区间最左记录和区间最右记录相隔不太远(只要相隔不大于10个页面即可),那就可以精确统计出满足emp_no > '10101' and emp_no
根据上面的步骤可以算出来PRIMARY索引的记录条数,所以读取记录的CPU成本为:26808*0.2=5361.6,其中26808是预估的需要读取的数据记录条数,0.2是读取一条记录成本常数。
PRIMARY的总成本
确定访问的IO成本+过滤数据的CPU成本=1+5361.6=5362.6
4、计算idx_titles_to_date需要成本
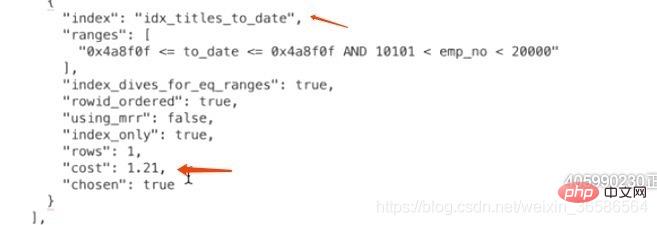
因为通过二级索引查询需要回表,所以在计算二级索引需要成本时还要加上回表的成本,而回表的成本就相当于下面这个SQL执行:
select * from employees.titles where 主键字段 in (主键值1,主键值2,。。。,主键值3);
所以idx_titles_to_date的成本 = 辅助索引的查询成本 + 回表查询的成本
5、比较各成本选出最优者
选择成本最小的索引
四、基于索引统计数据的成本计算
有时候使用索引执行查询时会有许多单点区间,比如使用IN语句就很容易产生非常多的单点区间,比如下边这个查询:
select * from employees.titles where to_date in ('a','b','c','d', ..., 'e');
很显然,这个查询可能使用到的索引就是idx_titles_to_date,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式我们上边已经介绍过了,就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。这种通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index pe。
如果只有几个单点区间的话,使用index pe的方式去计算这些单点区间对应的记录数也不是什么问题,可是如果很多呢,比如有20000次,MySQL的查询优化器为了计算这些单点区间对应的索引记录条数,要进行20000次index pe操作,那么这种情况下是很耗性能的,所以MySQL提供了一个系统变量eq_range_index_pe_limit,我们看一下这个系统变量的默认值:SHOW VARIABLES LIKE ‘%pe%’;为200。
也就是说如果我们的IN语句中的参数个数小于200个的话,将使用index pe的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用index pe了,要使用所谓的索引统计数据来进行估算。像会为每个表维护一份统计数据一样,MySQL也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用SHOW INDEX FROM 表名的语法。
Cardinality属性表示索引列中不重复值的个数。比如对于一个一万行记录的表来说,某个索引列的Cardinality属性是10000,那意味着该列中没有重复的值,如果Cardinality属性是1的话,就意味着该列的值全部是重复的。不过需要注意的是,对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。可以根据这个属性来估算IN语句中的参数所对应的记录数:
1)使用SHOW TABLE STATUS展示出的Rows值,也就是一个表中有多少条记录。
2)使用SHOW INDEX语句展示出的Cardinality属性。
3)根据上面两个值可以算出idx_key1索引对于的key1列平均单个值的重复次数:Rows/Cardinality
4)所以总共需要回表的记录数就是:IN语句中的参数个数*Rows/Cardinality。
NULL值处理
上面知道在统计列不重复值的时候,会影响到查询优化器。
对于NULL,有三种理解方式:
NULL值代表一个未确定的值,每一个NULL值都是独一无二的,在统计列不重复值的时候应该都当作独立的。
NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以所有的NULL值都一样,在统计列不重复值的时候应该只算一个。
NULL完全没有意义,在统计列不重复值的时候应该忽略NULL。
innodb提供了一个系统变量:
show global variables like '%innodb_stats_method%';
这个变量有三个值:
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
nulls_unequal:认为所有NULL值都是不相等的。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。
nulls_ignored:直接把NULL值忽略掉。
最好不在索引列中存放NULL值才是正解
五、统计数据
InnoDB提供了两种存储统计数据的方式:
• 统计数据存储在磁盘上。
• 统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了。
MySQL给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式。
- 1、基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
• innodb_table_stats存储了关于表的统计数据,每一条记录对应着一个表的统计数据
• innodb_index_stats存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据 - 2、定期更新统计数据
• 系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON,也就是该功能默认是开启的。每个表都维护了一个变量,该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新innodb_table_stats和innodb_index_stats表。不过自动重新计算统计数据的过程是异步发生的,也就是即使表中变动的记录数超过了10%,自动重新计算统计数据也不会立即发生,可能会延迟几秒才会进行计算。
•如果innodb_stats_auto_recalc系统变量的值为OFF的话,我们也可以手动调用ANALYZE TABLE语句来重新计算统计数据。ANALYZE TABLE single_table; - 3、控制执行计划
Index Hints
•USE INDEX:限制索引的使用范围,在数据表里建立了很多索引,当MySQL对索引进行选择时,这些索引都在考虑的范围内。但有时我们希望MySQL只考虑几个索引,而不是全部的索引,这就需要用到USE INDEX对查询语句进行设置。
•IGNORE INDEX :限制不使用索引的范围
•FORCE INDEX:我们希望MySQL必须要使用某一个索引(由于 MySQL在查询时只能使用一个索引,因此只能强迫MySQL使用一个索引)。这就需要使用FORCE INDEX来完成这个功能。
基本语法格式:
SELECT * FROM table1 USE|IGNORE|FORCE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3
【相关推荐:mysql视频教程】
以上がMySQL のクエリ オプティマイザーの詳細な分析 (動作原理の詳細な説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。