
ホームページ >データベース >mysql チュートリアル >mysqlで遅いSQL文をクエリする方法
mysqlで遅いSQL文をクエリする方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBオリジナル
- 2022-05-26 15:41:0213316ブラウズ
方法: 1. スロー クエリが有効になっていない場合は、「set global throw_query_log='ON';」を使用してスロー クエリを有効にします。 2. 「set global throw_query_log_file=path」を使用して、スロー クエリのファイル ストレージを設定します。 location; 3. 「subl path」のみを使用してファイルをクエリします。

このチュートリアルの動作環境: centos 7 システム、mysql8.0.22 バージョン、Dell G3 コンピューター。
mysql はどのように遅い SQL ステートメントをクエリしますか?
Mysql での遅い SQL ステートメントのレコード検索
遅いクエリ ログ throw_query_log は、遅い SQL ステートメントを記録するために使用されます。ログを記録してどの SQL ステートメントが遅いかを特定し、遅い SQL を最適化できます。
mysql データベースにログインします:
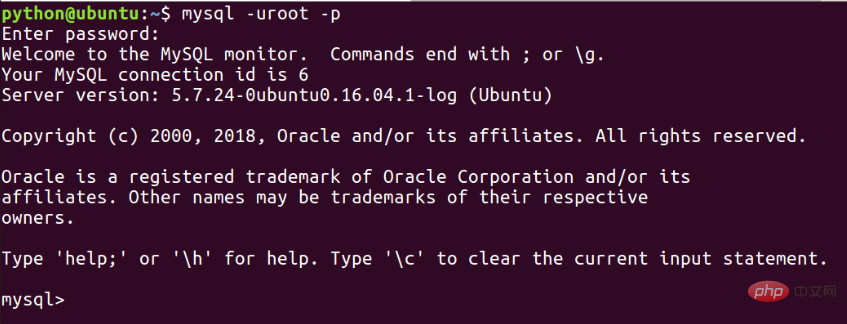
1. 現在の低速クエリが有効になっているかどうかを確認します。有効になっていない場合は、有効にします
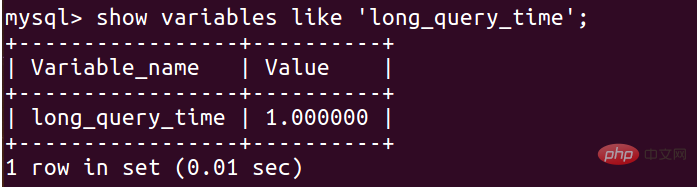
スロークエリで指定された時間:
show variables like 'slow_query_log'; show variableslike 'long_query_time';
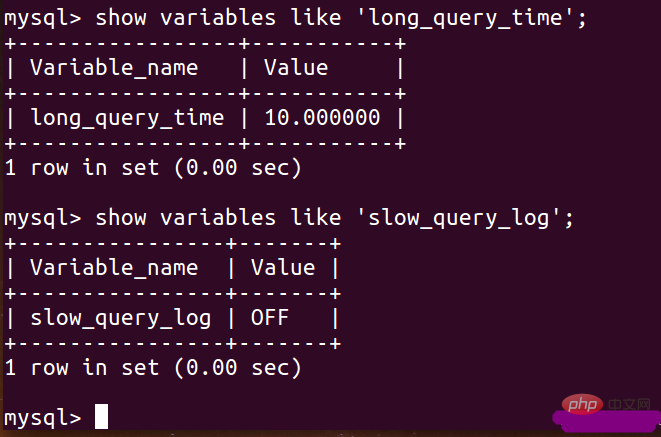
クエリの結果がオフの場合は、関連する設定を通じてオンに変更する必要があります。
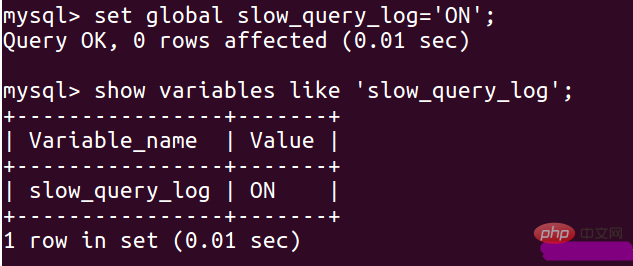
set global slow_query_log='ON';
遅いクエリの追跡時間を 1 秒に設定します:
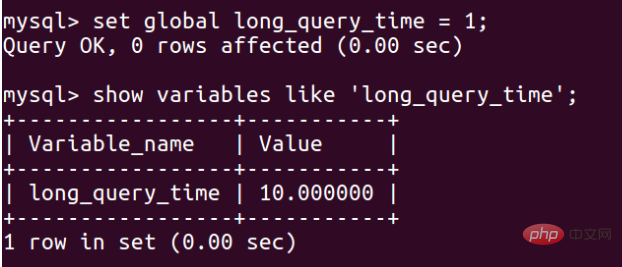
ここで設定します。この世界はそうはなりません。すぐに 1 秒になります。データベースの再起動後に有効になります:
#2. スロー クエリ ログ ファイルが保存される場所を設定します:
set global slow_query_log_file='/var/lib/mysql/test_1116.log';
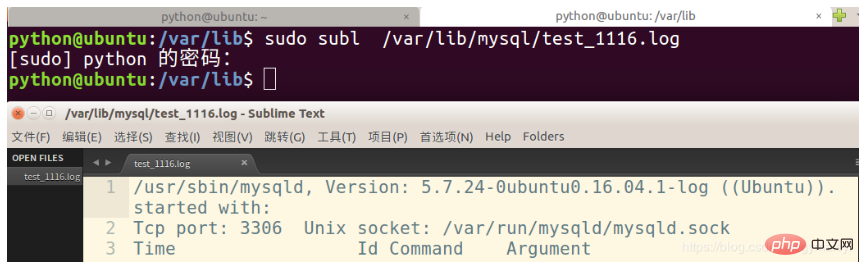
3. 次の構成済みファイルを表示します:
sudo subl /var/lib/mysql/test_1116.log
拡張知識:
MySQL データベースのクエリが遅い問題の解決方法
最近、データベースの応答が遅い問題に何度か遭遇し、処理手順と分析の考え方を整理してスクリプトを実行しました。これが他の人にも役立つことを願っています。
MySQL のクエリのパフォーマンスの低下
ほとんどのアプリケーション機能が遅くなっているのは明らかですが、完全に動作しなくなるわけではなく、長時間待っても応答はあります。しかし、システム全体が非常に行き詰まっているように見えます。
低速クエリの数をクエリする
一般に、正常に動作している MySQL サーバーの場合、1 分あたりの低速クエリが 1 桁になるのは正常です。 100 に近づくとシステムに問題が発生する可能性がありますが、まだ使用できます。ここ数回で失敗した遅いクエリの数は 1,000 件以上に達しました。
スロークエリの数は、mysql ライブラリのslow_logテーブルに保存されます。
SELECT * FROM `slow_log` where start_time > '2019/05/19 00:00:00';
このようにして、1 日の遅いクエリを見つけることができます。
現在のクエリ ステータスの表示
システムで現在実行中のクエリを表示するには、一般に show processlist を使用する必要があります。実際、これらのデータは、information_schema ライブラリの processlist テーブルにも保存されますしたがって、条件付きクエリを実行するには、このテーブルを直接クエリする方が便利です。
たとえば、現在のプロセスをすべて表示します
select * from information_schema.processlist
現在進行中のクエリを表示し、実行時間に応じて逆順に並べ替えます
select * from information_schema.processlist where info is not null order by time desc
通常実行中のデータベース。クエリの実行速度 間もなく、select で取得した情報が null でないクエリの数は非常に少なくなるでしょう。私たちのような重い負荷のある図書館では、通常、いくつかのアイテムしか見つかりません。空ではない情報を含むクエリが一度に数十件見つかった場合は、システムに問題があると考えられる場合もあります。
システムの問題と位置付け
システムの速度が低下していることに気づいたとき、すぐにスロー クエリの使用とプロセスリストの確認を行ったところ、1 分あたりのスロー クエリの数が急増していることがわかりました。同時に、多数のクエリが実行されています。
システムの通常の動作をできるだけ早く復元することが最優先事項であるため、システムに影響を与える最も直接的な方法は、プロセス リスト内のクエリのうちロック状態になっているクエリの数を確認することです。長時間実行されているプロセスを削除するには、kill コマンドを使用します。システム輻輳の原因となるこれらのプロセスを継続的に強制終了することで、最終的にはシステムを一時的に正常な状態に戻すことができます。
さらに、最も重要なことは、もちろん、どのクエリがシステムのブロックを引き起こしているかを分析することですが、分析には依然として遅いクエリを使用しています。
スロー クエリ テーブルのクエリ結果には、いくつかの重要な指標があります:
start_time 開始時刻このパラメータは、システムの問題の発生時間を照合して、原因となっているクエリを特定するために使用する必要があります。
query_time クエリ時間
rows_sent と rows_examined 送信された結果の数とクエリによってスキャンされた行の数 これら 2 つの値、特に rows_examined は特に重要です。基本的に、どのクエリが注意を払うべき「大きな」クエリであるかを示します。
実際の運用では、行数が多いクエリを一つ一つ解析し、インデックスを追加したり、クエリ文の記述を修正したりして問題を完全に解決します。
処理結果と反省
すべての遅いクエリを確認して修正した後、現在の MySQL の 1 分あたりの遅いクエリの数は 1 から 2 の間で推移しており、CPU 負荷も非常に低くなります。問題は基本的に解決されています。
問題の理由を考えると、注意する必要がある点がいくつかあります:
1. データベースの問題は、多くの場合、オンラインになった直後には問題を引き起こしませんが、累積的に問題が発生します。プロセスが進行し、問題が蓄積し続けます。クエリ ステートメントによってシステムの負荷が徐々に増加し、ラクダの背中を折る最後の藁が不可解に思えることがよくあります。
2. 最後の藁は、まったく存在しない可能性もあります。リリースやオンライン機能ではなく、ユーザーの使用量が増加し、データが蓄積されると爆発的に発生します。
3. 問題の顕在化は累積的なプロセスであるため、事前にレビューを行う必要があります。各コードリリース
4. インデックスの追加は非常に重要です
5. 遅いクエリの監視もZabbixの監視範囲に含める必要があります
推奨学習: mysql ビデオ チュートリアル
以上がmysqlで遅いSQL文をクエリする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。