



この記事では、python に関する関連知識を提供します。主に、動的視覚化アイコンの描画に関する関連問題を紹介します。Python の Plotly グラフィック ライブラリを使用すると、アニメーション チャートやインタラクティブ チャートを簡単に生成できます。皆様のお役に立てれば幸いです。

推奨学習: Python ビデオ チュートリアル
ストーリーテリングはデータ サイエンティストにとって重要なスキルです。自分の考えを表現し、他の人を説得するには、効果的にコミュニケーションする必要があります。そして、美しいビジュアライゼーションは、このタスクに最適なツールです。
この記事では、データ ストーリーをより美しく効果的にする、従来とは異なる 5 つの視覚化テクニックを紹介します。ここでは Python の Plotly グラフィックス ライブラリが使用され、アニメーション チャートやインタラクティブなチャートを簡単に生成できます。
モジュールのインストール
Plotly をまだインストールしていない場合は、ターミナルで次のコマンドを実行するだけでインストールを完了できます:
pip install plotly
視覚化された動的グラフ
特定の指標の推移を研究するとき、多くの場合、時間データが関係します。以下の図に示すように、Plotly アニメーション ツールに必要なコードは 1 行だけで、時間の経過に伴うデータの変化を観察できます。
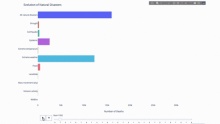
コードは次のとおりです。
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
フィルターに適用する時間変数がある限り、ほぼすべてのチャートをアニメーション化できます。以下は、散布図アニメーションの作成例です。

import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
太陽グラフ
サンバースト グラフは、 group by ステートメントを視覚化します。特定の数量を 1 つ以上のカテゴリ変数で分類する場合は、太陽グラフを使用します。
平均チップ データを性別と時間帯に応じて分類したいとします。この 2 つの group by ステートメントは、表と比較して視覚化することでより効果的に表示できます。
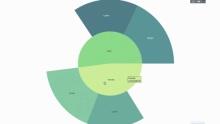
このグラフはインタラクティブなので、クリックして自分でカテゴリを探索できます。すべてのカテゴリを定義し、カテゴリ間の階層を宣言し (以下のコードのparents パラメータを参照)、対応する値を割り当てるだけです。この場合、これは group by ステートメントの出力です。
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
ここで、この階層にもう 1 つのレイヤーを追加します。
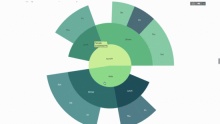
これを行うには、3 つのカテゴリ変数値を含む別の group by ステートメントを追加します。
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
ポインタ図
ポインタ図は見た目だけのものです。 KPI などの成功指標をレポートし、それらが目標にどれだけ近づいているかを示す場合は、このタイプのグラフを使用します。

import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
サンキー プロット
カテゴリ変数間の関係を調べるもう 1 つの方法は、次のような平行座標プロットです。いつでも値をドラッグ、ドロップ、ハイライト表示、参照できるので、プレゼンテーションに最適です。
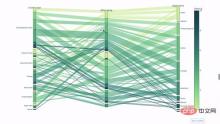
コードは次のとおりです。
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
平行座標チャート
平行座標チャートは導関数です。上の表の 。ここで、各文字列は 1 つの観測値を表します。これは、外れ値 (データの残りの部分から遠く離れた単一の線)、クラスター、傾向、および冗長変数 (たとえば、2 つの変数がすべての観測で同様の値を持つ場合、それらはは同じ水平線上にあり、冗長性の存在を示す便利なツールです)。

コードは次のとおりです:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
推奨学習: Python ビデオ チュートリアル
以上がPython を使用して動的視覚化チャートを描画する方法の詳細な図解説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AMPythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

