
Redis のホットデータ問題の解決策を一緒に分析しましょう

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-04-20 13:12:175260ブラウズ
この記事では、Redis に関する関連知識を提供します。主に Redis ホット キーのラージ バリュー ソリューションに関する関連問題を紹介します。一緒に見てみましょう。皆様のお役に立てれば幸いです。 。

推奨される学習: Redis ビデオ チュートリアル
Redis のホット データと重要な重要な価値のある質問も簡単に尋ねることができます。レベルの質問 すぐに問題を理解し、面接官を言葉を失う方が良いです。私の個人的な仕事の経験では、雪崩よりもホットなデータの問題が職場で遭遇する可能性が高くなります。しかし、ほとんどの場合、ホット スポットはホットではありません。しかし、この問題を制御できなくなると、オンライン上で発生した問題によって、今年のパフォーマンスが最下位に陥るだけで十分です。
通常の状況では、Redis クラスター内のデータは各ノードに均等に分散され、リクエストは各シャードに均等に分散されます。ただし、外部クローラー、攻撃、注目の製品などの特殊なシナリオでは、最も典型的な例は、有名人が Weibo で離婚を発表し、メッセージを残そうと人々が殺到し、Weibo のコメント機能がクラッシュする場合です。この短期間で特定のキーへのアクセス数が多すぎて、リクエストが送信されます。同じデータシャードに対して同じキーに対して作成されるため、シャードの負荷が高くなりボトルネックとなり、雪崩などの一連の問題が発生します。
1. インタビュアー: プロジェクト内で Redis のホット データの問題に遭遇したことがありますか? 一般的な原因は何ですか?
問題分析: 前回、グループ面接で偉い上司である Ali p7 の話を聞いたときに、この質問をされました。難易度の指標は 5 つ星です . 待ってください。初心者であることは本当にプラスです。
回答: ホット データ について言いたいことがあります。私は Redis の使用を初めて学んだときからこの問題を認識していました。ホットスポット データに関する最大の問題は、Redis クラスター内の負荷の不均衡 (データ スキュー) によって障害が発生することであり、これらの問題は Redis クラスターにとって致命的な打撃となります。
まず、Reids クラスターの負荷不均衡障害の主な理由について説明します。
- 過去のメンテナンスによると、アクセス数の多いキー 、つまりホット キーキーによってアクセスされる QPS が 1,000 を超える場合は、人気のある製品、話題の製品などに注意する必要があります。
- 大きな値、一部のキーのアクセス QPS は高くありませんが、値が大きいため、ネットワーク カードの負荷が大きく、ネットワーク カードのトラフィックがいっぱいで、単一マシンギガビット/秒、IO エラーが発生する可能性があります。
- ホットキーの大きな価値は同時に存在します、サーバーキラー。
ホット キーまたは大きな値によってどのような障害が発生するか:
- データ スキューの問題: 大きな値により、クラスター内のさまざまなノードでデータの分散が不均一になります。データ スキューの問題が発生すると、読み取り/書き込み比率が非常に高い多数のリクエストが同じ Redis サーバーに落ち、Redis の負荷が大幅に増加し、クラッシュしやすくなります。
- QPS スキュー: QPS はシャード間で不均一です。
- 値が大きいと、Redis サーバーのバッファーが不足し、取得タイムアウトが発生します。
- 値が大きすぎるため、コンピュータ ルームのネットワーク カードのトラフィックが不足しています。
- Redis キャッシュの障害は、データベース層の破壊の連鎖反応を引き起こします。
2. インタビュアー: 実際のプロジェクトでは、ホットなデータの問題をどのように正確に特定しますか?
回答: この問題の解決策は比較的広範囲にわたります。さまざまなビジネス シナリオによって異なります。たとえば、企業がプロモーション活動を組織する場合、次のような方法が必要です。プロモーションに参加する製品を事前にカウントするため、このシナリオは推定メソッドを通過できます。緊急時や不確実性のために、Redis はホットスポット データを独自に監視します。要約:
-
事前に知る方法:
企業によっては、人体統計やシステム統計が販促品などのホット データになる可能性があります。トピックス、ホリデートピックス、周年活動など。 -
Redis クライアント収集メソッド:
呼び出し元はカウントによってキー要求の数を数えますが、キーの数は予測できず、コードは非常に侵入的です。public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore } -
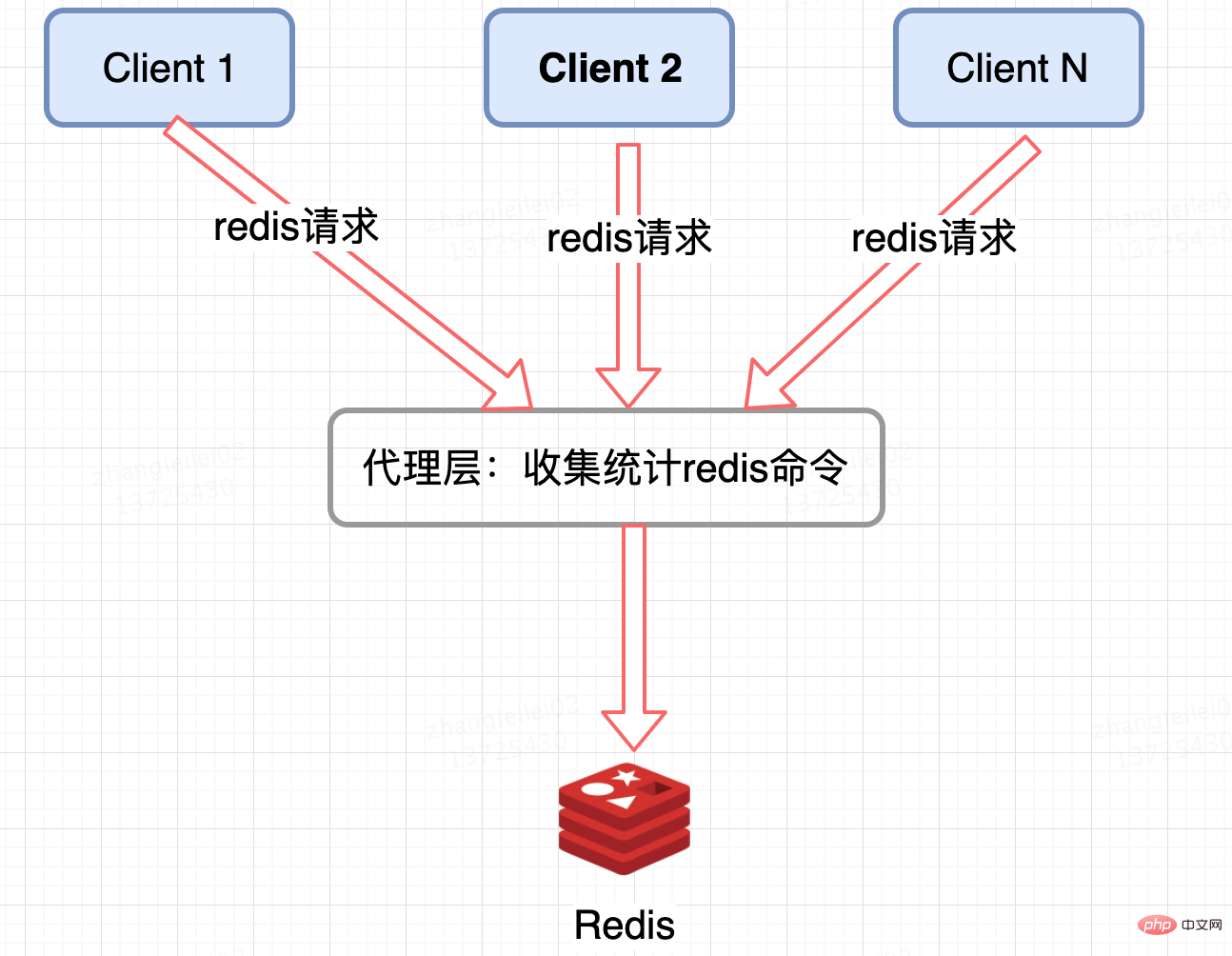
Redis クラスター プロキシ レイヤー統計:
Twemproxy や codis などのエージェント ベースの Redis 分散アーキテクチャには統合された入り口があり、プロキシ レイヤーで収集およびレポートできます。ただし、欠点は明らかで、すべての Redis クラスター アーキテクチャにプロキシがあるわけではありません。
-
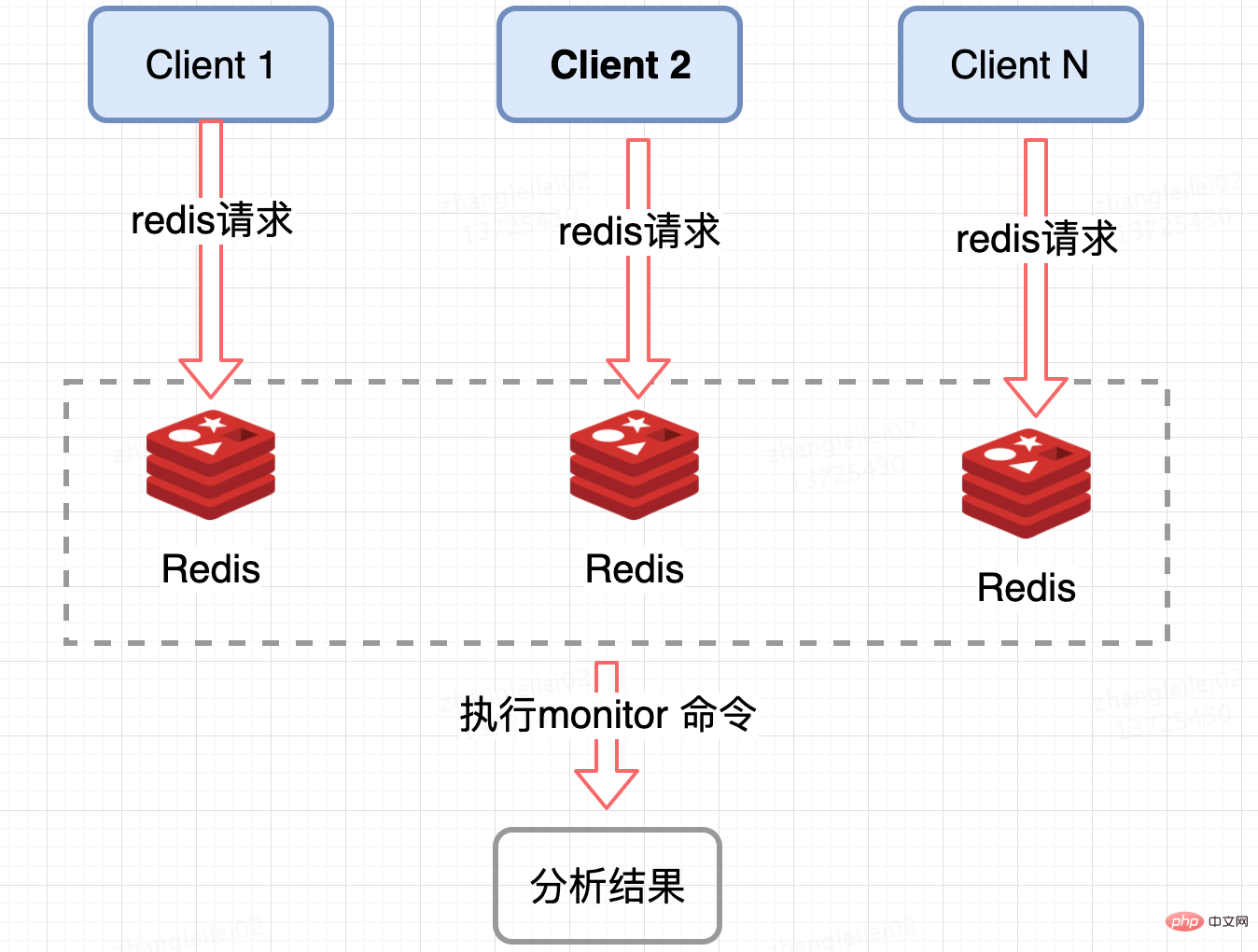
Redis サーバーの収集:
単一の Redis シャードの QPS を監視し、QPS がある程度傾けられたノードを監視してホットスポット キーを取得します。 Redis には監視コマンドが用意されており、一定期間内の特定の Redis ノード上のすべてのコマンドをカウントし、ホット キーを分析できます。高い同時実行条件では、メモリ爆発と Redis パフォーマンスの潜在的な危険があるため、この方法が適しています短期間の使用のため; また、Redis ノードのホットスポット キーをカウントすることしかできませんが、クラスターの場合は要約統計が必要ですが、ビジネスの観点からは少し面倒です。
上記の 4 つの方法は業界で一般的に使用されていますが、Redis のソース コードを調べて新しいアイデアを思いつきました。タイプ 5: Redis ソース コードを変更します。
-
Redis ソース コードを変更する: (ソース コードを読んでアイデアを考える)
Redis4.0 が多くのことをもたらしてくれることがわかりました。新しい機能 LFU ベースのホットスポット キー検出メカニズムを含むこの新機能により、これに基づいてホットスポット キー統計を実装できます。これは単なる私の個人的なアイデアです。
面接官の心理: この青年はとても思慮深く、視野が広く、ソースコードの修正にも気を配っていますが、私にはそんな野心はありません。私たちのチームにはこのような人材が必要です。
(問題を発見し、問題を分析し、問題を解決し、面接官の質問を待たずにホットデータの問題の解決方法を直接伝える。これが核となるコンテンツです)
3. ホット データの問題を解決する方法
回答: ホット データの問題を管理する方法に関して、この問題を解決するために主に 2 つの側面を考慮します。 1 つはデータのシャーディングであり、単一マシンのハングを防ぐためにクラスターの複数のシャードに圧力が均等に分散されます。2 つ目は移行の分離です。
概要の概要:
-
キー分割:
現在のキーの種類がハッシュなどのセカンダリ データ構造の場合タイプ。ハッシュ要素の数が多い場合は、現在のハッシュを分割して、ホット キーをいくつかの新しいキーに分割し、異なる Redis ノードに分散することによってプレッシャーを軽減することを検討できます。 -
ホットスポットの移行key:
Redis クラスターを例にとると、ホットスポット キーが配置されているスロットを新しい Redis ノードに個別に移行できます。この方法では、このホットスポット キーの QPS が非常に高い場合でも、クラスター全体には影響しません。他のビジネスもカスタマイズおよび開発でき、ホットスポット キーは自動的に独立したノードに移行されます。このソリューションは、より マルチコピー です。 -
ホットスポット キーの電流制限:
読み取りコマンドの場合は、ホットスポット キーを移行してからスレーブ ノードを追加することで問題を解決できます。書き込みコマンドの場合は、次の方法で電流を制限できます。このホットスポット キーを個別にターゲットにします。 -
ローカル キャッシュを増やす:
データの一貫性がそれほど高くないビジネスの場合、ホットスポット キーはローカル キャッシュにあるため、ビジネス マシンのローカル キャッシュにキャッシュできます。リモート IO コールが不要になります。ただし、データが更新されると、ビジネスと Redis データの間で不整合が発生する可能性があります。
インタビュアー: とても丁寧に答えていただき、非常に総合的に検討していただきました。
4. インタビュアー: Redis に関する最後の質問についてですが、Redis は豊富なデータ型をサポートしていますが、これらのデータ型に大きな値が格納される問題をどのように解決すればよいでしょうか? オンラインでこのような状況に遭遇したことがありますか?
問題分析: ホット キーという大きな概念と比較して、大きな値という概念は理解しやすいです。Redis はシングル スレッドで実行されるため、操作が非常に大きい場合、操作全体に影響します。Redis は Key-Value 構造のデータベースであるため、Redis の応答時間は悪影響を及ぼします。値が大きいということは、単一の値が大量のメモリを占有することを意味します。最も直接的なものは、 Redis クラスターへの影響は データ スキュー です。
回答: (私を困らせたいのですか? 私は準備ができています。)
まず、会社の価値に基づいて与えられる価値がどれほど大きいかについて話しましょう。
注: (経験値は標準ではなく、クラスタの運用保守担当者によるオンライン事例の長期観察に基づいてまとめられています)
- Big: 文字列型の値 > 10K、セット、リスト、ハッシュ、zset およびその他のコレクション データ型の要素数 > 1000。
- 特大: 文字列型の値 > 100K、set、list、hash、zset およびその他のコレクション データ型の要素数 > 10000。
Redis は単一スレッドで実行されるため、操作の値が非常に大きい場合、Redis 全体の応答時間に悪影響を及ぼします。事業の観点から分割することができます。典型的な分割をいくつか示します: 解体計画:
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
以上がRedis のホットデータ問題の解決策を一緒に分析しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。