
ホームページ >データベース >mysql チュートリアル >MySQLインタビューQ&A集(概要共有)
MySQLインタビューQ&A集(概要共有)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-03-22 17:44:432356ブラウズ
この記事は、mysql に関する関連知識を提供します。主に、データベース アーキテクチャ、インデックス作成、SQL 最適化など、面接でよくある質問をいくつかまとめています。皆様のお役に立てれば幸いです。

推奨学習: mysql チュートリアル
1. データベース アーキテクチャ
1.1. の基本アーキテクチャについて説明します。 MySQL の図
MySQL の論理アーキテクチャについて面接官に伝えてください。ホワイトボードをお持ちの場合は、次の図を描くことができます。この図はインターネットから取得したものです。
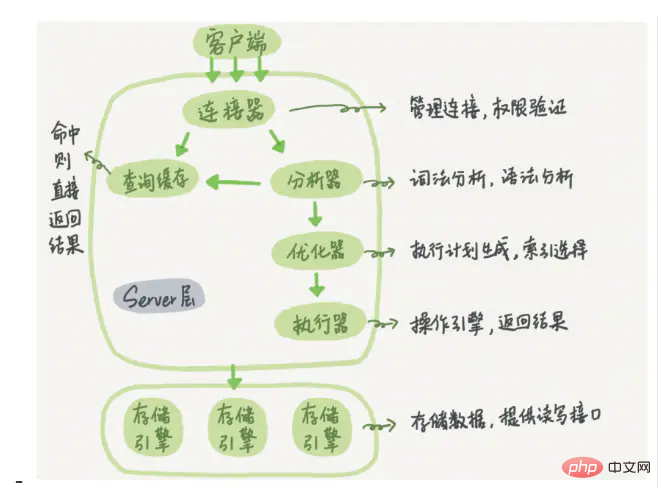
Mysql の論理アーキテクチャ図は主に 3 つの層に分かれています:
(1) 最初の層は接続処理、認可認証、セキュリティなどを担当します。 .
(2) 2 番目の層は SQL のコンパイルと最適化を担当します
(3) 3 番目の層はストレージ エンジンです。
1.2. SQL クエリ ステートメントは MySQL でどのように実行されますか?
まずステートメント
に権限があるかどうかを確認します。権限がない場合は、直接エラー メッセージが返されます。権限がある場合は、キャッシュがクエリされます。最初 (MySQL8.0 バージョンより前)。キャッシュがない場合、アナライザーは
字句解析を実行し、SQL ステートメント内の select などの重要な要素を抽出し、SQL ステートメントが文法的であるかどうかを判断します。キーワードが正しいかどうかなどのエラー。最後に、オプティマイザは実行計画を決定し、権限の検証を実行します。権限がない場合は直接エラー メッセージを返します。権限がある場合は、
call を実行します。データベース エンジン インターフェイスを実行し、実行に戻ります。
2. SQL の最適化
2.1. 日常業務で SQL をどのように最適化しますか?
この質問には次の観点から答えることができます:
2.1.1、テーブル構造の最適化
(1) 数値フィールドを使用してみてください
数値情報のみを含むフィールドを文字型として設計しない場合、クエリと接続のパフォーマンスが低下し、ストレージのオーバーヘッドが増加します。これは、エンジンがクエリや接続を処理するときに文字列内の各文字を 1 つずつ比較し、数値型の場合は 1 回の比較だけで十分であるためです。
(2) できる限り char ではなく varchar を使用してください。
可変長フィールドは記憶領域が小さいため、記憶領域を節約できます。
(3) インデックス列に重複データが大量にある場合、インデックスを削除することができます。
例えば、性別の列がある場合、ほぼ男性、女性のみ、不明な場合、そのようなインデックスは無効です。
2.1.2、クエリの最適化
where 句では != または 演算子を使用しないようにしてください
条件を接続するために where 句で または を使用することは避けてください
- ##どのクエリにも select を表示しないでください * #where 句のフィールドでの null 値判定を避ける
- 2.1.3,
- のインデックスを作成するクエリ条件として機能し、順序付けされるフィールド
- あまりにも多くのインデックスを作成することを避け、結合インデックスを使用します
- 2.2. 実行計画の見方(説明して)その中の各フィールドの意味を理解していますか?
実行計画情報を返すには、select ステートメントの前に Explain キーワードを追加します。
 (1) id 列: select ステートメントのシリアル番号 MySQL では、select クエリを単純なクエリと複雑なクエリに分けます。
(1) id 列: select ステートメントのシリアル番号 MySQL では、select クエリを単純なクエリと複雑なクエリに分けます。
(2) select_type 列: 対応する行が単純なクエリであるか、複雑なクエリであるかを示します。
(3) テーブル列: Explain の行がどのテーブルにアクセスしているかを示します。
(4) type 列: 最も重要な列の 1 つ。 MySQL がテーブル内の行を検索する方法を決定する関連付けのタイプまたはアクセス タイプを表します。最良から最悪の順: システム > const > eq_ref > ref > フルテキスト > ref_or_null > インデックスマージ > unique_subquery > インデックス サブクエリ > 範囲 > インデックス > ALL
( 5) possible_keys 列: クエリが検索に使用できるインデックスを示します。
(6) キー列: この列は、mysql がテーブルへのアクセスを最適化するために実際に使用するインデックスを示します。
(7) key_len 列: インデックス内の mysql によって使用されるバイト数を示します。この値は、インデックス内のどの列が使用されているかを計算するために使用できます。
(8) ref 列: この列は、キー列レコードのインデックス内の値を検索するためにテーブルで使用される列または定数を示します。一般的なものは次のとおりです: const (定数)、func、NULL 、およびフィールド名。
(9) rows 列: この列は、mysql が読み取りおよび検出するために推定する行数です。これは結果セット内の行数ではないことに注意してください。
(10) 追加列: 追加情報を表示します。たとえば、インデックスの使用、where の使用、一時的な使用などがあります。
2.3. ビジネス システム内の時間のかかる SQL について気にしたことはありますか?クエリ統計が遅すぎますか?遅いクエリをどのように最適化しましたか?
通常 SQL を記述するときは、Explain 分析を使用する習慣を身に付ける必要があります。遅いクエリ、運用、メンテナンスの統計により、定期的な統計が得られます。
遅いクエリの最適化アイデア:
-
ステートメントを分析して、不要なフィールド/データが読み込まれているかどうかを確認します
SQLの実行文、インデックスがヒットしたかなどを分析します。
-
SQLが非常に複雑な場合は、SQL構造を最適化します
テーブル データの量が大きすぎる場合は、テーブルを分割することを検討してください。
- B ツリーは範囲クエリを実行できますが、ハッシュ インデックスは実行できません。
- B ツリーはジョイント インデックスの左端の原則をサポートしていますが、ハッシュ インデックスはそれをサポートしていません。
- B ツリーはソートによる順序をサポートしていますが、ハッシュ インデックスはそれをサポートしていません。
- ハッシュ インデックスは、同等のクエリに対して B ツリーよりも効率的です。
- B ツリーがあいまいクエリに like を使用する場合、like の後の単語 (% で始まるなど) が最適化の役割を果たす可能性があり、ハッシュ インデックスはあいまいクエリをまったく実行できません。
- データ量が少ない場合、インデックスの追加は適していません
- 更新頻度が高い インデックス作成に適さない = 識別性の低いフィールドはインデックス作成に適さない (性別など)
##(1) 利点:
- 一意のインデックスにより、データベース テーブル内のデータの各行の一意性が保証されます
- # #Index データ クエリを高速化し、クエリ時間を短縮できます
#(2) 欠点:
インデックスの作成と維持に時間がかかります
インデックスは物理スペースを占有する必要があります。データ テーブルが占有するデータ スペースに加えて、各インデックスも一定量の物理スペースを占有します。
-
テーブル内のデータに基づいて追加、削除、または変更する場合、インデックスも動的に維持する必要があります。
4. ロック
4.1. MySQL でデッドロックの問題が発生したことがありますか? どのように解決しましたか?
遭遇しました。デッドロックをトラブルシューティングするための一般的な手順は次のとおりです。
(1) デッドロック ログを確認して、エンジンの innodb ステータスを表示します。
(2) デッドロック SQL を特定します。
(3) SQL ロックの状況を分析します。
( 4) デッドロックケースのシミュレーション
(5) デッドロックログの分析
(6) デッドロック結果の分析
4.2. データベースの楽観的ロックと悲観的ロックについて説明します。彼らの違いは?
(1) 悲観的ロック:
悲観的ロックは一途で不安な性格で、時事問題にのみ心を持ち、大切なデータが盗まれるのではないかと常に不安を感じています。他のトランザクションによって変更されるため、トランザクションが悲観的ロックを所有 (取得) した後は、他のトランザクションはデータを変更できず、ロックが解放されるのを待ってから実行することしかできません。
(2) 楽観的ロック:
楽観的ロックの「楽観主義」は、データがあまり頻繁に変更されないと信じているという事実に反映されています。したがって、複数のトランザクションが同時にデータを変更できるようになります。
実装方法: オプティミスティック ロックは通常、バージョン番号メカニズムまたは CAS アルゴリズムを使用して実装されます。
4.3. MVCC について詳しく、その基礎となる原則を知っていますか?
MVCC (Multiversion Concurrency Control)、つまりマルチバージョン同時実行制御技術です。
MySQL InnoDB での MVCC の実装は、主にデータベースの同時実行パフォーマンスを向上させ、読み取り/書き込みの競合を処理するためのより良い方法を使用することで、読み取り/書き込みの競合が発生した場合でもロックを実現できません。 -同時読み取りのブロック。
5. トランザクション
5.1. MySQL トランザクションの 4 つの主要な特性と実装原則
原子性: トランザクションは全体として実行され、データベースに対するすべての操作が実行されるか、何も実行されないかのいずれかです。
一貫性: トランザクションの開始前とトランザクションの終了後にデータが破壊されないことを意味します。アカウント A がアカウント B に 10 元を送金した場合、成功または失敗に関係なく、A とB 合計金額は変わりません。
分離: 複数のトランザクションが同時にアクセスする場合、トランザクションは互いに分離されます。つまり、1 つのトランザクションは他のトランザクションの実行効果に影響を与えません。一言で言えば、物事の間に矛盾がないことを意味します。
永続性: トランザクションの完了後、トランザクションによってデータベースに加えられた操作上の変更がデータベースに永続的に保存されることを示します。
5.2. トランザクションの分離レベルは何ですか? MySQL のデフォルトの分離レベルは何ですか?
- #コミットされていない読み取り #コミットされた読み取り
- #繰り返し可能な読み取り
-
#Serializable
Mysql のデフォルトのトランザクション分離レベルは反復可能読み取りです)
5.3. ファントム リード、ダーティ リード、および非反復可能読み取りとは何ですか?
トランザクション A と B は交互に実行されます。トランザクション A はトランザクション B のコミットされていないデータを読み取るため、トランザクション A はトランザクション B によって干渉されます。これはダーティ リードです。
トランザクションのスコープ内で、2 つの同一のクエリが同じレコードを読み取りますが、異なるデータを返します。これは反復不可能な読み取りです。
トランザクション A は範囲の結果セットをクエリし、別の同時トランザクション B はこの範囲にデータを挿入/削除し、サイレントにコミットします。その後、トランザクション A は同じ範囲を再度クエリし、2 回読み取ります。結果セットは次のとおりです。それはファントムリーディングです。
6. 実践的な戦闘
6.1. MySQL データベースの CPU サージにどう対処するか?
トラブルシューティング プロセス:
(1) top コマンドを使用して、mysqld が原因であるか、他の理由が原因であるかを観察して判断します。
(2) mysqld が原因の場合は、processlist を表示し、セッションのステータスを確認し、リソースを消費する SQL が実行されているかどうかを確認します。
(3) 消費量の多い SQL を見つけて、実行計画が正確かどうか、インデックスが欠落していないか、データ量が多すぎるかどうかを確認します。
処理:
(1) これらのスレッドを強制終了します (そして CPU 使用率が減少するかどうかを観察します)
(2) 対応する調整を行います (インデックスの追加、SQL の変更、メモリパラメータの変更)
(3) これらの SQL を再実行します。
その他の状況:
各 SQL ステートメントが多くのリソースを消費しないにもかかわらず、突然多数のセッションが接続され、CPU の使用率が急増する可能性もあります。アプリケーションに連絡する必要があります。接続数が急増する理由を分析してから、接続数の制限など、対応する調整を行ってください。
6.2. マスター/スレーブ遅延を解決するにはどうすればよいですか?マイSQL?
マスター/スレーブ レプリケーションは 5 つのステップに分かれています: (画像はインターネットからのものです)
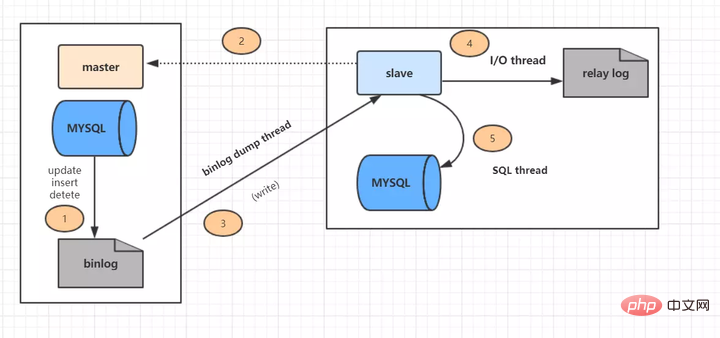 ステップ 1: メイン ライブラリの更新イベント (更新、挿入、削除) が binlog に書き込まれます
ステップ 1: メイン ライブラリの更新イベント (更新、挿入、削除) が binlog に書き込まれます
- #ステップ 2: スレーブ ライブラリから接続を開始し、メイン ライブラリに接続します。
- ステップ 3: この時点で、メイン ライブラリはバイナリ ダンプ スレッドを作成し、バイナリ ログの内容をスレーブ ライブラリに送信します。 #ステップ 4: スレーブ ライブラリから開始した後、I/O スレッドを作成し、メイン ライブラリから渡されたバイナリ ログの内容を読み取り、リレー ログに書き込みます
- ステップ 5: リレー ログからコンテンツを読み取り、Exec_Master_Log_Pos 位置から始まる読み取り更新イベントを実行し、更新されたコンテンツをスレーブ データベースに書き込む SQL スレッドも作成されます
- マスタ/スレーブ同期遅延の原因
サーバーはクライアントが接続するために N 個のリンクを開くため、大規模な同時更新操作が行われますが、サーバーからバイナリログを読み取るスレッドは 1 つだけです。長時間使用したり、特定の SQL でテーブルをロックする必要があるため、マスター サーバー上に大量の SQL バックログが存在し、スレーブ サーバーに同期されなくなります。これは、マスターとスレーブの不一致、つまりマスターとスレーブの遅延につながります。
マスター/スレーブ同期遅延の解決策
マスター サーバーは更新操作を担当し、スレーブ サーバーよりも高いセキュリティ要件があります。したがって、sync_binlog=1、innodb_flush_log_at_trx_commit = 1、その他の設定など、一部の設定パラメータは変更できます。
スレーブとしてより優れたハードウェア デバイスを選択してください。
クエリを提供せずにスレーブサーバーをバックアップとして使用すると、スレーブサーバーの負荷が軽減され、必然的に中継ログの SQL 実行効率が高くなります。
スレーブ サーバーを追加する目的は、読み取りのプレッシャーを分散し、サーバーの負荷を軽減することです。
6.3. サブデータベースとサブテーブルを設計するように頼まれた場合、どうするかを簡単に教えてください。
サブデータベースとテーブル スキーム:
水平サブデータベース:フィールドに基づき、特定の戦略 (ハッシュ、範囲など) に基づきます。 .)、1 つのライブラリ内のデータが複数のライブラリに分割されます。
水平テーブル分割: フィールドと特定の戦略 (ハッシュ、範囲など) に基づいて、1 つのテーブル内のデータを複数のテーブルに分割します。
データベースの垂直分割: テーブルに基づいて、異なるビジネス所有権に従って、異なるテーブルが異なるデータベースに分割されます。
垂直テーブル分割: フィールドに基づいて、フィールドのアクティビティに従って、テーブル内のフィールドが異なるテーブル (メイン テーブルと拡張テーブル) に分割されます。
# 一般的に使用されるシャーディング ミドルウェア:
- ##sharding-jdbc
- Mycat
- #サブデータベースおよびサブテーブルで発生する可能性のある問題
トランザクションの問題: 分散が必要です タイプトランザクション
- クロスノード結合の問題: この問題を解決するには、2 回クエリを実行して、
- クロスノード結合を実現します。 count、order by、group by、および集計関数の問題: 結果は各ノードで取得され、アプリケーション側でマージされます。
- データ移行、容量計画、拡張などの問題
- ID 問題: データベースが分割されると、データベースに依存できなくなります。データベース自体の主キーの生成メカニズム、最も単純なものでは UUID を検討できます
- クロスシャードのソートとページングの問題
- 推奨される学習: mysql学習チュートリアル
以上がMySQLインタビューQ&A集(概要共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。