
ホームページ >Java >&#&チュートリアル >Javaコレクションフレームワークの詳細な分析
Javaコレクションフレームワークの詳細な分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-03-15 18:21:082271ブラウズ
この記事では、java に関する関連知識を提供します。主にコレクション フレームワークに関連する問題を紹介します。Java コレクション フレームワークは、優れたパフォーマンスと使いやすさを備えた一連のインターフェイスとクラスを提供します。 java.util パッケージが皆さんのお役に立てば幸いです。

java 学習チュートリアル 」
1. はじめに1. コレクション フレームワークの概要Java コレクション フレームワークは、優れたパフォーマンスと使いやすさを備えたインターフェイスとクラスのセットを提供しており、java.util パッケージにあります。コンテナには主に Collection と Map が含まれます。Collection にはオブジェクトのコレクションが格納され、Map にはキーと値のペア (2 つのオブジェクト) のマッピング テーブルが格納されます。

2. 関連コンテナの概要
2.1 セット関連
- ##TreeSet は赤黒ツリーの実装に基づいており、範囲に基づいた要素の検索などの順序付けされた操作をサポートします。ただし、検索効率は HashSet ほど良くなく、HashSet の検索時間は O(1) であるのに対し、TreeSet の検索時間は O(logN)
- HashSet## となります。 # ハッシュ テーブルの実装に基づいて、高速検索をサポートしますが、順序付けされた操作はサポートしません。また、要素の挿入順序情報が失われます。これは、Iterator を使用して HashSet を走査することによって得られる結果が不確実であることを意味します。
LinkedHashSet -
HashSet の検索効率を持ち、内部的に二重リンク リストを使用して要素の挿入順序を維持します。
2.2 リスト関連
- ArrayList
-
動的配列実装に基づいて、ランダム アクセスをサポートします。
Vector -
ArrayList に似ていますが、スレッドセーフです。
LinkedList -
二重リンク リストの実装に基づいて、連続的にのみアクセスできますが、要素はリンク リストの途中ですばやく挿入および削除できます。それだけでなく、LinkedList はスタック、キュー、デックとしても使用できます。
2.3 キュー関連
- LinkedList
-
は双方向キューを実装できます。
PriorityQueue -
ヒープ構造に基づいて、優先キューを実装するために使用できます。
2.4 マップ関連
- TreeMap
-
赤黒ツリーの実装に基づいています。
HashMap -
ハッシュ テーブルの実装に基づきます。
HashTable -
HashMap に似ていますが、スレッドセーフです。つまり、データの不整合を引き起こすことなく、複数のスレッドが同時に HashTable に書き込むことができます。これはレガシー クラスであるため、使用しないでください。 ConcurrentHashMap
を使用してスレッド セーフをサポートできるようになりました。ConcurrentHashMapはセグメンテーション ロックを導入するため、より効率的になります。LinkedHashMap 二重リンク リストを使用して、要素の順序を挿入順または最も最近使用された (LRU) 順に維持します -
3。コレクション フォーカス
- Set インターフェイスは、順序付けされていない一意のオブジェクトのセットを格納します。
- Map インターフェイスは、キーと値のオブジェクトのセットを格納し、キーから値へのマッピングを提供します。
- ArrayList は、可変長の配列を実装します。 、メモリ内に連続した領域を割り当てます。要素のトラバースと要素へのランダム アクセスがより効率的です
- LinkedList はリンク リスト ストレージを使用します。
- HashSet はハッシュ アルゴリズムを採用して Set を実装しています
- HashSet の最下層は HashMap を使用して実装されており、hashCode が使用されるためクエリ効率が高くなります。要素を直接決定するアルゴリズムを使用 メモリアドレス、高い追加および削除効率
- #2. ArrayList 解析
- 1. ArrayList は
| Description | boolean add(Object o) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #void add(intindex, Object o) | Add指定されたインデックス位置の要素、 | index 位置 0 からリスト内の要素数までの値である必要があります|||||||||||||
| int size()戻り値リスト内の要素の数 | ||||||||||||||
| Object get(int index) | 指定されたインデックス位置にある要素を返します。 | 取り出した要素はObject型なので、使用前に型変換する必要があります。|||||||||||||
| boolean contains(Object o)Determineリストが指定された要素が存在するかどうか | ||||||||||||||
| boolean delete(Object o) | リストから要素を削除します | |||||||||||||
| Object delete(intindex) | リストから指定された位置にある要素を削除します。開始インデックスは 0 | |||||||||||||
から始まります。2. ArrayList の概要
さらに、ArrayList と Vector の違いは次のとおりです: ArrayList はスレッド安全ではありません。スレッドが同じ ArrayList コレクションにアクセスする場合、プログラムはコレクションの同期を手動で確保する必要がありますが、Vector はスレッドセーフです。 3. ソースコードの分析3.1 継承構造と階層関係public class ArrayList<e> extends AbstractList<e> implements List<e>, RandomAccess, Cloneable, java.io.Serializable</e></e></e>
ここでの継承構造は、IDEA の [ナビゲート] > [型階層] から確認できます。
3.2 プロパティ//版本号
private static final long serialVersionUID = 8683452581122892189L;
//缺省容量
private static final int DEFAULT_CAPACITY = 10;
//空对象数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//缺省空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//存储的数组元素
transient Object[] elementData; // non-private to simplify nested class access
//实际元素大小,默认为0
private int size;
//最大数组容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
3.3 構築方法/**
* 构造具有指定初始容量的空列表
* 如果指定的初始容量为负,则为IllegalArgumentException
*/public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}}/**
* 默认空数组的大小为10
* ArrayList中储存数据的其实就是一个数组,这个数组就是elementData
*/public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/**
* 按照集合迭代器返回元素的顺序构造包含指定集合的元素的列表
*/public ArrayList(Collection extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 转换为数组
//每个集合的toarray()的实现方法不一样,所以需要判断一下,如果不是Object[].class类型,那么久需要使用ArrayList中的方法去改造一下。
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 否则就用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}}
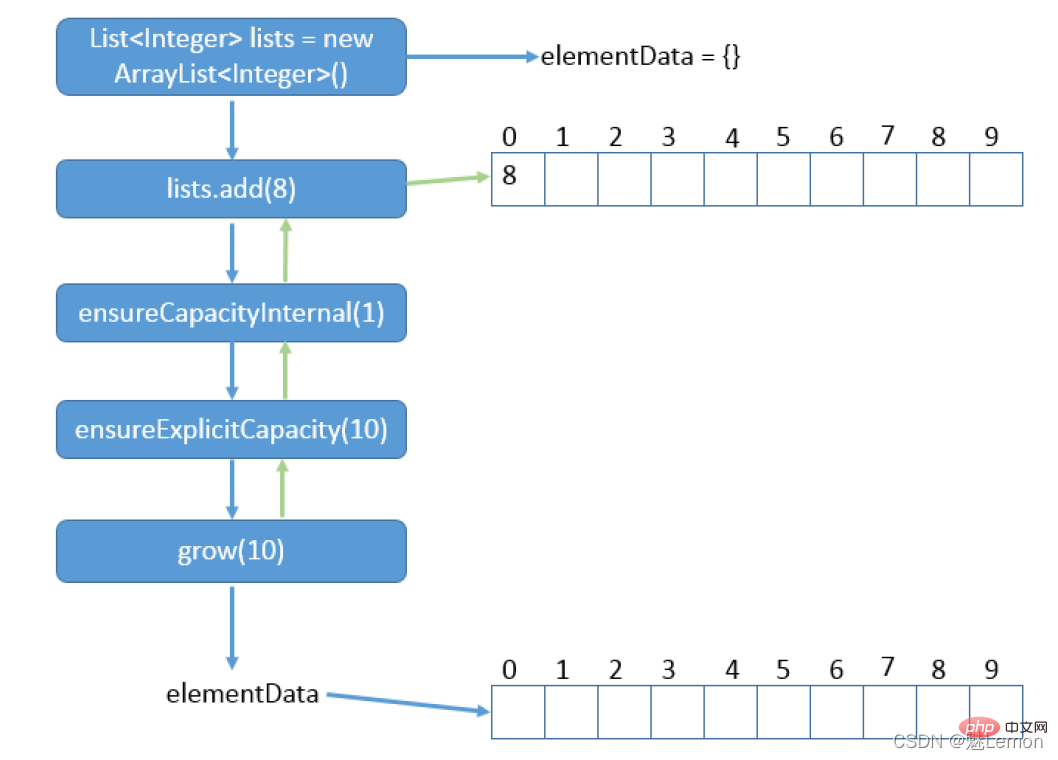
3.4 自動拡張配列に要素を追加するたびに、追加された要素の数が現在の配列の長さを超えないかどうかを確認する必要があります。を超えると、データ追加のニーズを満たすために配列が拡張されます。配列の拡張は、パブリック メソッド 配列を拡張すると、古い配列の要素が新しい配列にコピーされ、配列の容量が増加するたびに元の容量の約 1.5 倍になります。 **この操作のコストは非常に高いため、実際の使用ではアレイ容量の拡張を避けるように努める必要があります。保存する要素の数が予測できる場合は、配列の拡張を避けるために ArrayList インスタンスを構築するときにその容量を指定する必要があります。または、実際のニーズに応じて、ensureCapacity メソッド を呼び出して、ArrayList インスタンスの容量を手動で増加します。 private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {
//判断初始化的elementData是不是空的数组,也就是没有长度
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//因为如果是空的话,minCapacity=size+1;其实就是等于1,空的数组没有长度就存放不了
//所以就将minCapacity变成10,也就是默认大小,但是在这里,还没有真正的初始化这个elementData的大小
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//确认实际的容量,上面只是将minCapacity=10,这个方法就是真正的判断elementData是否够用
return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//minCapacity如果大于了实际elementData的长度,那么就说明elementData数组的长度不够用
/*第一种情况:由于elementData初始化时是空的数组,那么第一次add的时候,
minCapacity=size+1;也就minCapacity=1,在上一个方法(确定内部容量ensureCapacityInternal)
就会判断出是空的数组,就会给将minCapacity=10,到这一步为止,还没有改变elementData的大小。
第二种情况:elementData不是空的数组了,那么在add的时候,minCapacity=size+1;也就是
minCapacity代表着elementData中增加之后的实际数据个数,拿着它判断elementData的length
是否够用,如果length不够用,那么肯定要扩大容量,不然增加的这个元素就会溢出。*/
if (minCapacity - elementData.length > 0)
grow(minCapacity);}//ArrayList核心的方法,能扩展数组大小的真正秘密。private void grow(int minCapacity) {
//将扩充前的elementData大小给oldCapacity
int oldCapacity = elementData.length;
//newCapacity就是1.5倍的oldCapacity
int newCapacity = oldCapacity + (oldCapacity >> 1);
/*这句话就是适应于elementData就空数组的时候,length=0,那么oldCapacity=0,newCapacity=0,
所以这个判断成立,在这里就是真正的初始化elementData的大小了,就是为10.前面的工作都是准备工作。
*/
if (newCapacity - minCapacity 0)
newCapacity = hugeCapacity(minCapacity);
//新的容量大小已经确定好就copy数组,改变容量大小。
elementData = Arrays.copyOf(elementData, newCapacity);}//用来赋最大值private static int hugeCapacity(int minCapacity) {
if (minCapacity MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;}
3.5 add() メソッド/**
* 添加一个特定的元素到list的末尾。
* 先size+1判断数组容量是否够用,最后加入元素
*/public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;}/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/public void add(int index, E element) {
//检查index也就是插入的位置是否合理。
rangeCheckForAdd(index);
//检查容量是否够用,不够就自动扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//这个方法就是用来在插入元素之后,要将index之后的元素都往后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;}
add() メソッドが呼び出されると、実際の関数が呼び出されます: add→ensureCapacityInternal→ensureExplicitCapacity(→ give→hugeCapacity ) たとえば、空の配列を初期化して値を追加した後、最初に容量が自動的に拡張されます 3.6 TrimToSize()現在のリストに保存されている実際の要素のサイズに合わせて基になる配列の容量を調整する関数 public void trimToSize() {
modCount++;
if (size <h3>3.7 delete() メソッド</h3><p><code>remove( )</code>このメソッドには 2 つのバージョンもあります。1 つは <code>remove(int index)</code>指定された位置にある要素を削除するもので、もう 1 つは <code>remove(Object o)</code> を削除するものです。 <code>o.equals(elementData[index])</code>Elements を満たす最初のもの。削除操作は <code>add()</code> 操作の逆のプロセスであり、削除ポイントの後の要素を 1 つ前に移動する必要があります。 GC が機能するには、最後の位置に明示的に <code>null</code> 値を割り当てる必要があることに注意してください。 </p><pre class="brush:php;toolbar:false">public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //清除该位置的引用,让GC起作用
return oldValue;
}3.8 その他のメソッドここでは、コア メソッドについて簡単に説明します。ソース コードを参照すると、他のメソッドをすぐに理解できます。 3.9 フェイルファスト メカニズムArrayList の採用 4. 概要
3. LinkedList 分析1. LinkedList を使用します
|






以上がJavaコレクションフレームワークの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。