
ホームページ >データベース >mysql チュートリアル >MySQL トランザクション ログを一緒に分析しましょう
MySQL トランザクション ログを一緒に分析しましょう

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-03-09 18:32:571801ブラウズ
この記事では、mysql に関する関連知識を提供します。主に mysql トランザクションの関連問題を紹介します。トランザクションは、MySQL と NoSQL を区別し、リレーショナル データベース データを保証する重要な機能です。一貫性の主要なテクノロジ、皆様のお役に立てれば幸いです。

推奨される学習: mysql 学習ビデオ チュートリアル
1. MySQL トランザクション
トランザクションは、MySQL と MySQL を区別するものです。 NoSQL 重要な機能は、リレーショナル データベースのデータの一貫性を確保するための主要なテクノロジです。トランザクションはデータベース操作の基本的な実行単位とみなすことができ、これには 1 つ以上の SQL ステートメントが含まれる場合があります。これらのステートメントが実行されると、すべてが実行されるか、まったく実行されません。
トランザクションの実行には、主にコミットとロールバックの 2 つの操作が含まれます。
送信: コミットし、トランザクションの実行結果をデータベースに書き込みます。
ロールバック: ロールバック、実行されたすべてのステートメントをロールバックし、変更前のデータを返します。
MySQL トランザクションには、4 つの ACID キングとして知られる 4 つの特性が含まれています。
トランザクションのアトミック性は、UNDO ログによって実現されます。トランザクションをロールバックする必要がある場合、InnoDB エンジンは SQL ステートメントを元に戻すために undo ログを呼び出します。データ ロールバック。原子性: ステートメントは完全に実行されるか、まったく実行されません。これはトランザクションの中核機能です。トランザクション自体は原子性によって定義され、実装は主に UNDO ログに基づいています。
Durability (永続性): トランザクション送信後のダウンタイムなどでデータが失われないことを保証します。主に REDO ログに基づいて実装されます。トランザクションの実行は可能な限り可能です 他のトランザクションの影響を受けません; InnoDB のデフォルトの分離レベルは RR です。RR の実装は主に、ロック メカニズム、データの非表示列、元に戻すログ、ネクスト キー ロック メカニズムに基づいています。
一貫性: トランザクション 追求される最終目標である一貫性の実現には、データベース レベルとアプリケーション レベルの両方での保証が必要です。トランザクション アトミック操作と同様に、トランザクションをさらに分割できないことを意味します。すべての操作が完了するか、まったく操作が完了しないかのどちらかです。トランザクション内の SQL ステートメントの実行に失敗した場合、実行されたステートメントもロールバックする必要があります。 、データベースはトランザクション前の状態に戻ります。0 と 1 のみで、他の値はありません。
トランザクションのアトミック性は、トランザクションが全体であることを示します。トランザクションが正常に実行できない場合、すべてトランザクション内で実行されたステートメントはロールバックする必要があるため、データベースはトランザクションが最初に開始されていない状態に戻ります。
永続性
トランザクションの耐久性とは、トランザクションがコミットされると、データベースの変更は一時的ではなく永続的になる必要があります。これは、トランザクションがコミットされた後は、他の操作やシステムのダウンタイムであっても、元のトランザクションの実行結果に影響を与えないことを意味します。トランザクションの処理は、InnoDB ストレージ エンジンを介して実行されます。REDO ログが実装されます。具体的な実装アイデアについては、以下を参照してください。分離
アトミック性と耐久性は、単一トランザクション自体のプロパティです。 , 一方、分離はトランザクション間で維持されるべき関係を指します。分離では、異なるトランザクションの影響が互いに干渉せず、1 つのトランザクションの操作が他のトランザクションから分離されることが必要です。トランザクションには SQL ステートメントが 1 つだけ含まれているわけではないため、トランザクションの実行中に他のトランザクションの実行が開始される可能性が非常に高くなります。したがって、複数のトランザクションの同時実行には、トランザクション間の操作が互いに分離されている必要があります。これは多少似ています。
ロック メカニズム
トランザクション間の分離は、ロック メカニズムを通じて実現されます。トランザクションが特定の行を変更する必要がある場合データベース内のデータが大きい場合は、最初にデータをロックする必要があります。他のトランザクションは、ロックされたデータに対して操作を実行せず、現在のトランザクションがコミットまたはロールバックしてロックを解放するのを待つだけです。多くのシナリオでは、データの保護と同期のためにさまざまなロックの実装が使用されます。 MySQL では、ロックはさまざまな分割基準に従ってさまざまなタイプに分割することもできます。粒度に応じて分割: 行ロック、テーブル ロック、ページ ロック
用途に応じて分割: 共有ロック、排他ロック
アイデアに応じて分割: 悲観的lock 、 Optimistic locking
ロック機構については多くの知識点がありますが、スペースの都合上、すべて説明します。ここでは、粒度に従って分割されたロックについて簡単に紹介します。
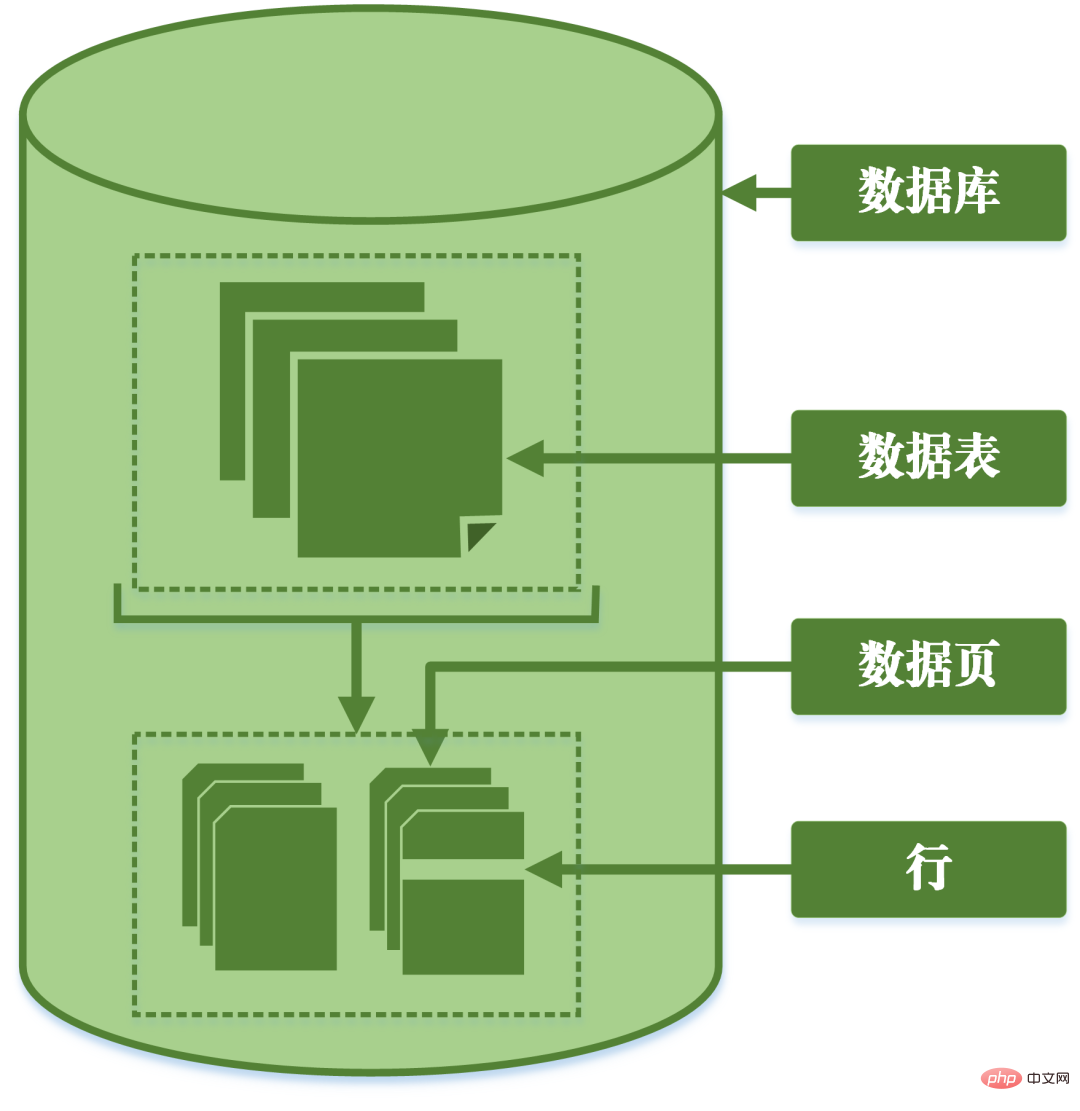
粒度: データ ウェアハウスのデータ ユニットに保存されているデータの精製度または包括性のレベルを指します。精製度が高いほど粒度は小さくなり、逆に精製度が低いほど粒度は大きくなります。
MySQL は、ロックの粒度に応じて行ロック、テーブル ロック、ページ ロックに分類できます。行ロック: 最小粒度のロック。現在の操作の行のみがロックされていることを示します。 テーブル ロック:最大粒度。現在の操作がテーブル全体をロックしていることを示します。
ページ ロック: 行レベルのロックとテーブル レベルのロックの間の粒度を持つロック。つまり、ページをロックします。
テーブル ロックはデータ操作時にテーブル全体をロックするため、同時実行パフォーマンスが低下します。行ロックは、操作が必要なデータのみをロックするため、同時実行パフォーマンスは低下します。良い。ただし、ロック自体がリソースを消費するため (ロックの取得、ロックの確認、ロックの解放などはすべてリソースを消費します)、ロックされたデータが多い場合にはテーブル ロックを使用するとリソースを大幅に節約できます。MySQL のさまざまなストレージ エンジンは、さまざまなロックをサポートできます。 MyIsam はテーブル ロックのみをサポートしますが、InnoDB はテーブル ロックと行ロックの両方をサポートします。パフォーマンス上の理由から、ほとんどの場合、行ロックが使用されます。
同時読み取りと書き込みの問題
MySQL の同時読み取りと書き込みにより、ダーティ リード、非再現性、ファントム読み取りという 3 種類の問題が発生する可能性があります。 。 (1) ダーティ読み取り: 現在のトランザクションは、他のトランザクションからコミットされていないデータ、つまりダーティ データを読み取ります。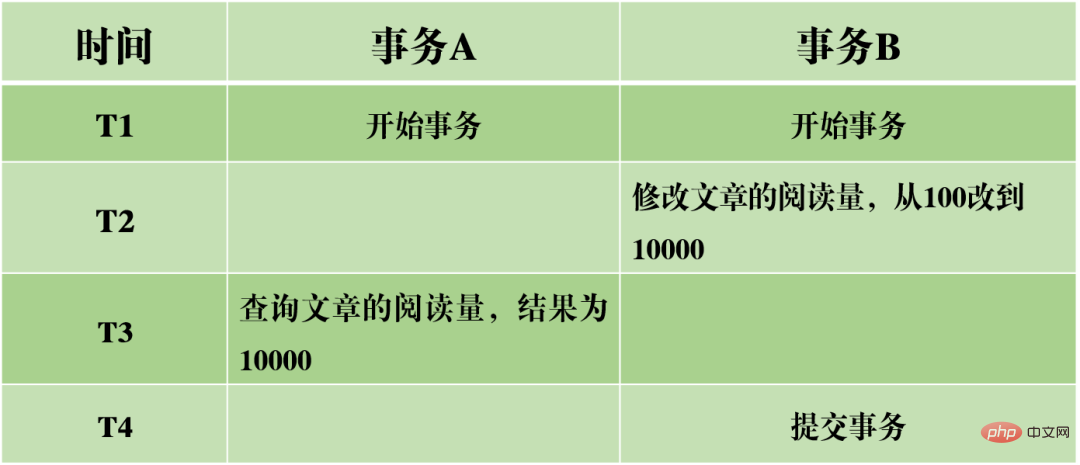
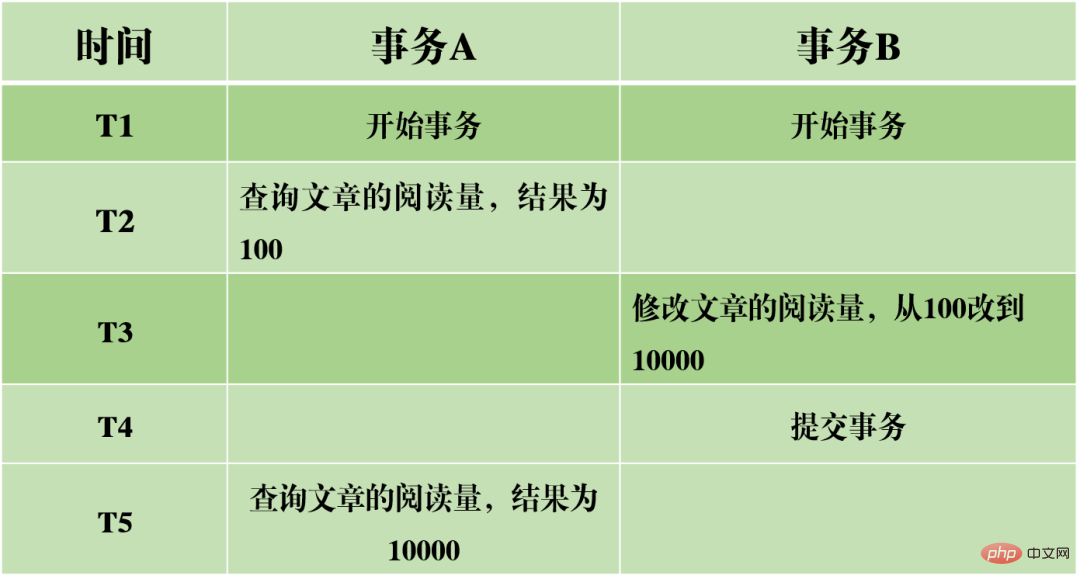
 上の図は例で、0
上の図は例で、0
上記の 3 つの問題に基づいて、データベースの分離特性の異なる程度を示す 4 つの分離レベルが生成されました。
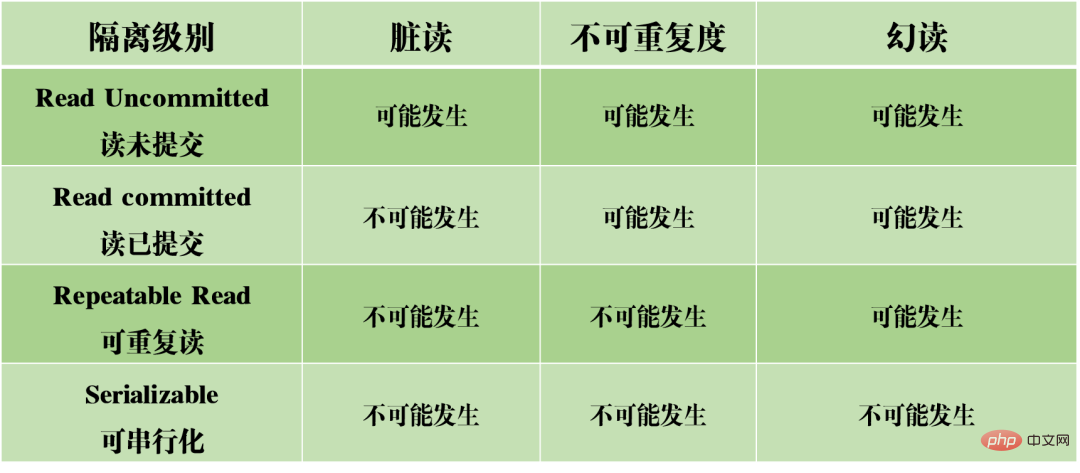 実際のデータベース設計では、分離レベルが高くなるほどデータベースの同時実行効率が低下し、分離レベルが低すぎると、データベースの読み取りおよび書き込みプロセス中にエラーが発生すると、あらゆる種類のやっかいな問題が発生します。
実際のデータベース設計では、分離レベルが高くなるほどデータベースの同時実行効率が低下し、分離レベルが低すぎると、データベースの読み取りおよび書き込みプロセス中にエラーが発生すると、あらゆる種類のやっかいな問題が発生します。
したがって、ほとんどのデータベース システムでは、デフォルトの分離レベルはコミット読み取り (Oracle など) または反復読み取り RR (MySQL の InnoDB エンジン) です。
MVCCまたしても噛み砕くのが難しい大きな作品。 MVCC は、RR を繰り返し読み取ることができる上記の 3 番目の分離レベルを実装するために使用されます。
MVCC: マルチバージョン同時実行制御、マルチバージョン同時実行制御プロトコル。MVCC の特徴は、異なるトランザクションで異なるバージョンのデータを同時に読み取ることができるため、ダーティ リードや反復不可能な読み取りの問題が解決されることです。
MVCC は実際に、データの非表示列とロールバック ログ (UNDO ログ) を通じて、複数のバージョンのデータの共存を実現します。この利点は、MVCC を使用してデータを読み取るときにロックする必要がないため、同時読み取りと書き込みの競合が回避されることです。
MVCC を実装すると、バージョン番号、現在の行が作成されたときの削除時刻、UNDO ログへのロールバック ポインタなど、いくつかの追加の非表示列がデータの各行に保存されます。ここでのバージョン番号は実際の時間値ではなく、システムのバージョン番号です。新しいトランザクションが開始されるたびに、システムのバージョン番号が自動的に増加します。トランザクションの開始時のシステム バージョン番号はトランザクションのバージョン番号として使用され、クエリ内のレコードの各行のバージョン番号と比較するために使用されます。
各トランザクションには独自のバージョン番号があるため、トランザクション内でデータ操作が実行されるとき、バージョン番号の比較によってデータのバージョン管理の目的が達成されます。
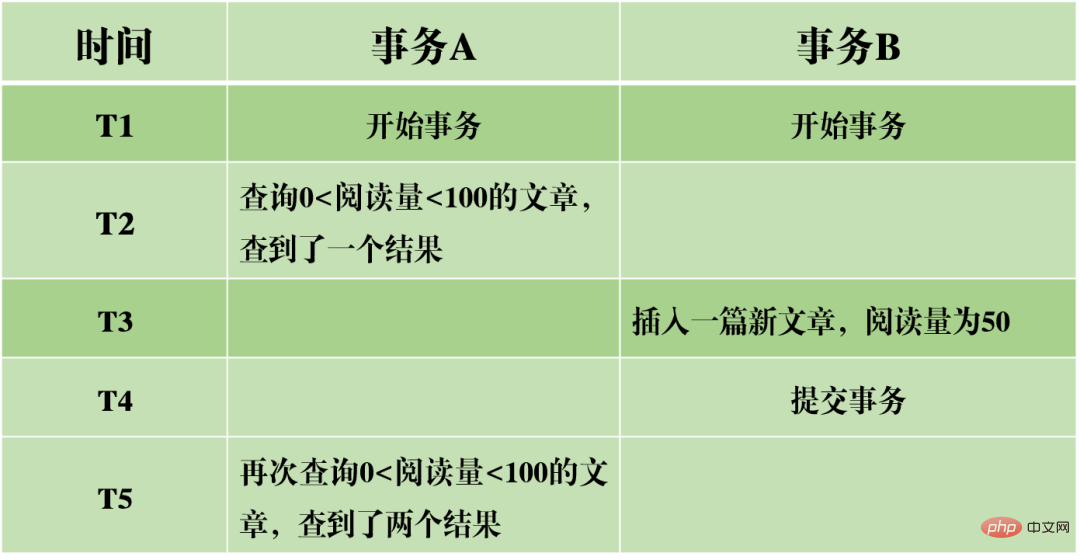
さらに、InnoDB によって実装された分離レベル RR は、ネクスト キー ロック メカニズムによって実現されるファントム読み取り現象を回避できます。
ネクストキー ロックは実際には行ロックの一種ですが、現在の行レコード自体をロックするだけでなく、範囲もロックします。たとえば、上記のファントム リーディングの例では、0
ギャップ ロック: インデックス レコードのギャップをブロックします。
InnoDB はファントム リードの問題を回避するためにネクスト キー ロックを使用しますが、これは真にシリアル化可能な分離ではありません。別の例を見てみましょう。
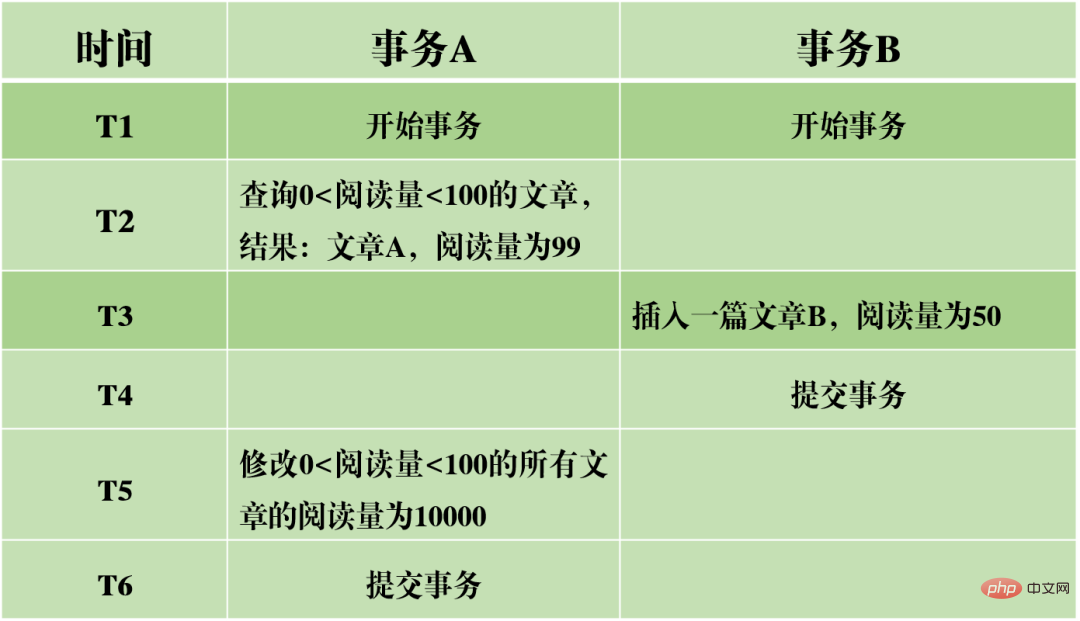
最初に質問します:
トランザクション A がトランザクションをコミットした後の T6 時点で、記事 A と記事 B の読書量を推測します。いくらですか?
答えは、記事 AB の閲覧数が 10,000 に変更されたことです。これは、トランザクション B の送信が実際にトランザクション A の実行に影響を与えることを意味し、2 つのトランザクションが完全に分離されていないことを示しています。ファントムリード現象は回避できますが、シリアル化できるレベルには達しません。
これは、ダーティ リード、反復不可能なリード、ファントム リードを回避することが、シリアル化可能な分離レベルを達成するために必要な条件ではあるが、十分な条件ではないことも示しています。シリアル化可能性により、ダーティ リード、ノンリピータブル リード、ファントム リードを回避できますが、ダーティ リード、ノンリピータブル リード、ファントム リードを回避しても必ずしもシリアル化可能性が実現するとは限りません。
一貫性
一貫性とは、トランザクションの実行後、データベースの整合性制約が破壊されず、トランザクションの実行前後のデータ状態が正当であることを意味します。実行されました。
一貫性はトランザクションによって追求される究極の目標であり、実際にはデータベース状態の一貫性を確保するために原子性、耐久性、分離性が存在します。
これ以上は言いません。丁寧に味わっていただきます。
2. MySQL ログ システム
MySQL の基本構造を理解すると、通常、MySQL の実行プロセスをより明確に理解できるようになります。次にロギングシステムについて紹介します。
MySQL ログ システムはデータベースの重要なコンポーネントであり、データベースの更新と変更を記録するために使用されます。データベースに障害が発生した場合、別のログ レコードを通じてデータベースの元のデータを復元できます。したがって、実際には、ログ システムが MySQL 操作の堅牢性と堅牢性を直接決定します。
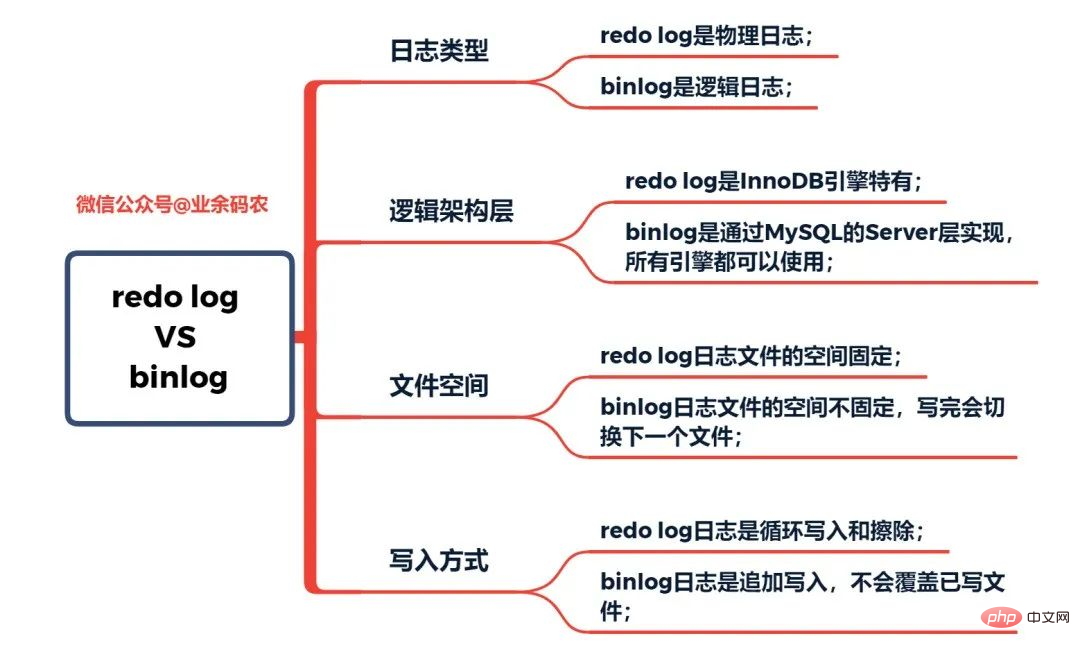
MySQL には、バイナリ ログ (binlog)、エラー ログ、クエリ ログ、スロー クエリ ログなど、多くの種類のログがあります。さらに、InnoDB ストレージ エンジンは、次の 2 種類のログも提供します。REDO ログ ( redo ログ)と undo ログ(ロールバック ログ)。ここでは InnoDB エンジンに焦点を当て、REDO ログ、ロールバック ログ、バイナリ ログの 3 種類を分析します。
Redo ログ (redo ログ)
REDO ログ (redo ログ) は、InnoDB エンジン層のログであり、原因となったデータの変更を記録するために使用されます。トランザクション操作による、データ ページの物理的な変更です。
日記のやり直し機能は実はわかりやすいので例えてみましょう。データベース内のデータの変更は、自分で書いた論文のようなものですが、ある日その論文を紛失してしまったらどうなるでしょうか?このような不幸な出来事を防ぐために、論文を書くときに、すべての変更を記録する小さなノートを用意し、特定のページにいつ、どのような変更が加えられたかを記録することができます。これはやり直しログです。
InnoDB エンジンは、最初に更新レコードを REDO ログに書き込み、次にシステムがアイドル状態のときまたは設定された更新戦略に従ってログの内容をディスクに更新することによってデータを更新します。これはいわゆる先行書き込み技術 (Write Ahead ロギング) です。このテクノロジーにより、IO 操作の頻度が大幅に削減され、データ更新の効率が向上します。
ダーティデータフラッシュ
REDOログのサイズは固定であることに注意してください.更新レコードを継続的に書き込むために、REDOでは2つのフラグ位置が設定されますログには、checkpoint と write_pos があり、それぞれ消去が記録された位置と書き込みが記録された位置を示します。 REDO ログのデータ書き込み図を次の図に示します。
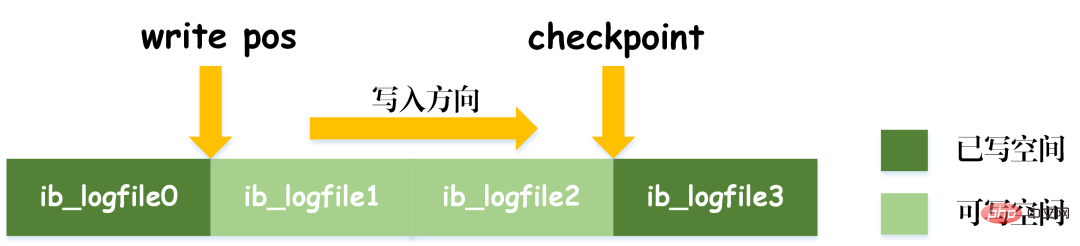
write_pos マークがログの末尾に達すると、ログの末尾から先頭にジャンプして再循環書き込みを行います。したがって、REDO ログの論理構造は直線的ではなく、循環運動とみなすことができます。 write_pos と Checkpoint の間のスペースは新しいデータの書き込みに使用でき、書き込みと消去は 1 サイクル内で前後に実行されます。
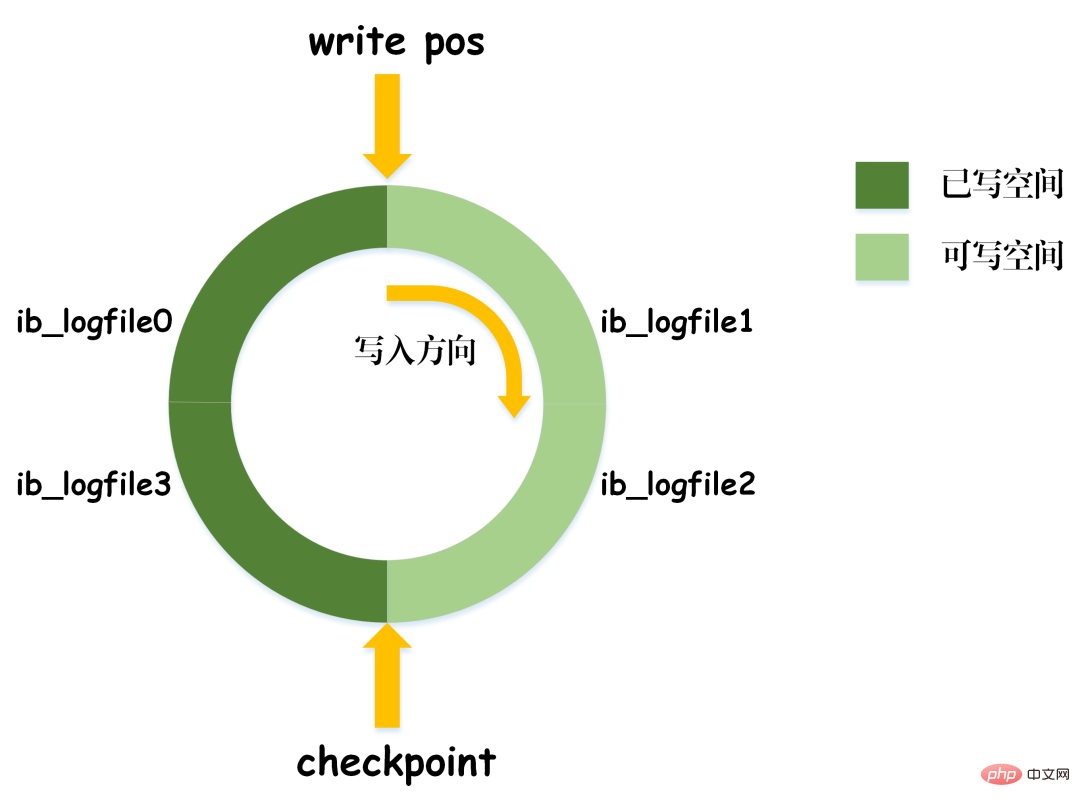
write_pos がチェックポイントに追いつくと、REDO ログがいっぱいになったことを意味します。現時点では、新しいデータベース更新ステートメントを実行し続けることはできません。最初にいくつかのレコードを停止して削除し、チェックポイント ルールを実行して書き込み可能な領域を解放する必要があります。
チェックポイント ルール: チェックポイントがトリガーされた後、バッファ内のダーティ データ ページとダーティ ログ ページの両方をディスクにフラッシュします。
ダーティ データ: ディスクにフラッシュされていないメモリ内のデータを指します。
REDO ログの最も重要な概念はバッファ プールです。これはメモリ内に割り当てられる領域であり、データベースにアクセスするためのバッファとしてディスク内の一部のデータ ページのマッピングが含まれます。
データの読み取りをリクエストすると、まずバッファ プールにヒットがあるかどうかが判断され、ミスがあった場合は、ディスク上でデータが取得され、バッファ プールに置かれます。
##データの書き込み要求が行われると、まずそのデータがバッファー プールに書き込まれ、バッファー プール内の変更されたデータが定期的にディスクに更新されます。このプロセスはブラッシングとも呼ばれます。したがって、データが変更されると、バッファー プール内のデータの変更に加えて、操作が REDO ログにも記録され、トランザクションが送信されるとデータがフラッシュされます。 REDO ログレコードに基づくプレート。 MySQL がダウンした場合でも、再起動時に REDO ログ内のデータを読み取ってデータベースを復元できるため、トランザクションの耐久性が確保され、データベースのクラッシュセーフ機能が得られます。
ダーティ ログのフラッシュ
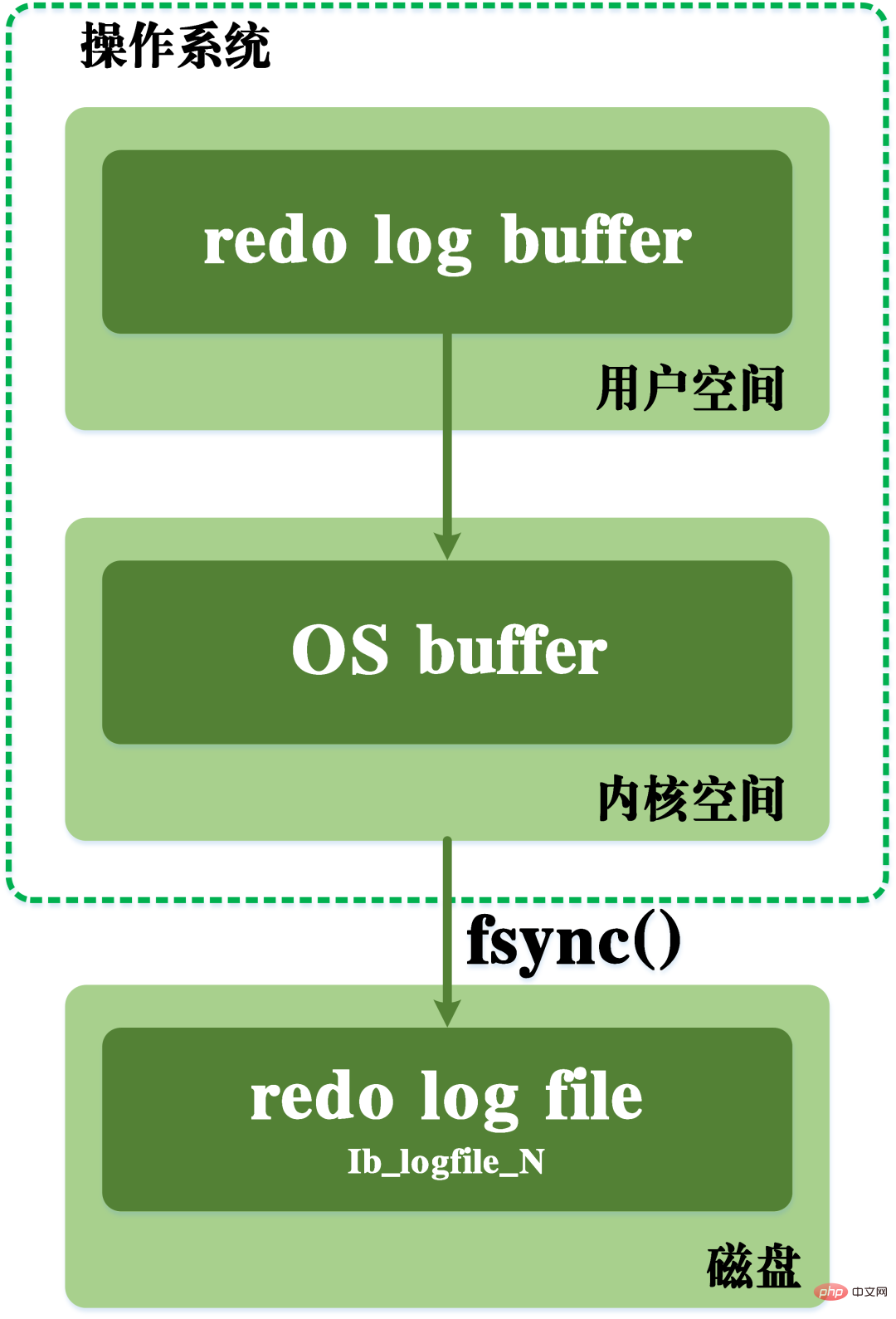
上記のダーティ データのフラッシュに加えて、実際には、REDO ログが記録されるときに、ログ ファイルを作成するには、ログ レコードをメモリからディスクに書き込むプロセスも実行する必要があります。 REDO ログのログは、揮発性メモリ上に存在するキャッシュログ REDO ログ buff と、ディスク上に保存された REDO ログファイル REDO ログファイルの 2 つに分けられます。 各レコードをディスク上のログに確実に書き込むために、REDO ログ バッファ内のログが REDO ログ ファイルに書き込まれるたびに、オペレーティング システムの fsync 操作が呼び出されます。fsync 関数: UNIX システム ヘッダー ファイル #include書き込みプロセス中に、オペレーティング システムのカーネル空間の OS バッファも通過する必要があります。 REDO ログの書き込みプロセスを次の図に示します。に含まれており、メモリ内で変更されたすべてのファイル データをストレージ デバイスに同期するために使用されます。
バイナリ ログ (binlog)
バイナリ ログ binlog はサービス層です。ログはアーカイブ ログとも呼ばれます。 Binlog は主に、データベースのすべての更新操作を含む、データベース内の変更を記録します。データ変更を伴うすべての操作はバイナリ ログに記録する必要があります。したがって、binlog はデータのコピーとバックアップが簡単にできるため、マスター/スレーブ ライブラリの同期によく使用されます。 ここで binlog に保存されている内容は、REDO ログに非常に似ているように見えますが、そうではありません。 REDO ログは特定のデータに対する実際の変更を記録する物理ログですが、binlog は SQL ステートメントの元のロジックを記録する論理ログです。たとえば、「ID=2 の行のフィールドを指定する」などです。プラス1」。 binlog ログの内容はバイナリであり、ログ形式パラメータに応じて、SQL ステートメント、データ自体、またはその 2 つの混合に基づく場合があります。一般によく使用されるレコードは SQL ステートメントです。 ここでの物理と論理の概念についての私の個人的な理解は次のとおりです:物理ログは、実際のデータベースのデータ ページの変更情報とみなすことができ、 「どのような方法でこの結果になったか」は重要ではなく、 論理ログとは、ある方法や操作方法によるデータの変化とみなして、論理的な操作を記録したものです。同時に、REDO ログは MySQL クラッシュ後のデータ回復を保証するクラッシュ リカバリに基づいており、一方、binlog はポイントインタイム リカバリに基づいており、サーバーがデータに基づいてデータを回復できることを保証します。時点、またはデータのバックアップを作成します。 実は、MySQL には最初は REDO ログがありませんでした。当初、MySQL には InnoDB エンジンがなかったため、組み込みエンジンは MyISAM でした。 Binlog はサービス層のログであるため、すべてのエンジンで使用できます。ただし、binlog ログだけではアーカイブ機能しか提供できず、クラッシュ セーフ機能を提供できないため、InnoDB エンジンは Oracle から学んだ技術、つまり REDO ログを使用してクラッシュ セーフ機能を実現します。ここでは、REDO ログと binlog の特性をそれぞれ比較します。
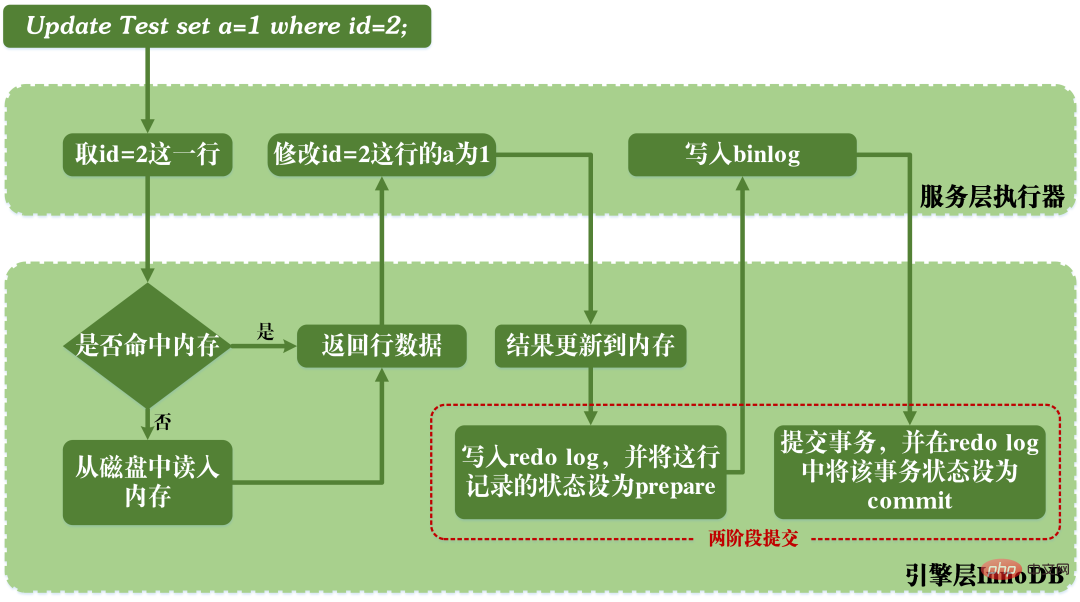
MySQL update ステートメントの実行プロセス
上の図からわかるように、MySQL は update ステートメントを実行すると、サービス層でステートメントを解析して実行します。エンジン層はデータを抽出して保存し、同時にサービス層は InnoDB にバイナリログと REDO ログを書き込みます。
それだけではなく、REDO ログの書き込みには 2 つの段階があります。1 つはバイナリログが書き込まれる前の準備状態の書き込み、もう 1 つはバイナリログが書き込まれた後のコミット状態の書き込みです。 。
このような 2 段階の提出を設定したのには、当然のことながら理由があります。ここで、2 段階の送信を使用する代わりに、「単一段階」の送信、つまり、最初に REDO ログを書き込んでから binlog を書き込むか、最初に binlog を書き込んでから REDO ログを書き込むかのいずれかを採用すると仮定できます。これら 2 つの方法で送信すると、元のデータベースの状態と復元されたデータベースの状態が一致しなくなります。
最初に REDO ログを書き込み、次に binlog を書き込みます:
REDO ログを書き込んだ後、現時点ではデータにはクラッシュ セーフ機能があるため、システムがクラッシュし、データがトランザクション開始前の状態に復元されます。ただし、REDO ログが完了し、バイナリログが書き込まれる前にシステムがクラッシュした場合、システムはクラッシュします。現時点では、binlog は上記の更新ステートメントを保存しないため、binlog を使用してデータベースをバックアップまたは復元すると、上記の更新ステートメントが失われます。その結果、id=2の行のデータは更新されません。
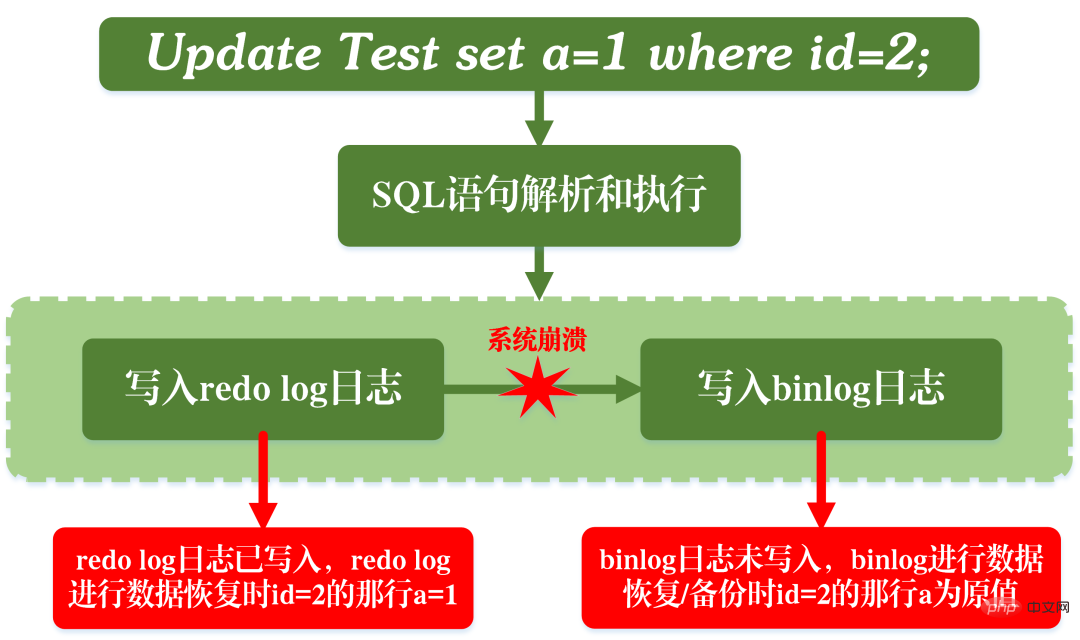
最初に REDO ログを書き込み、次に binlog を書き込む問題
最初に binlog を書き込み、次に REDO ログを書き込みます:
バイナリログの書き込み後、すべてのステートメントが保存されるため、バイナリログを通じてコピーまたは復元されたデータベースの行 id=2 のデータは a=1 に更新されます。ただし、REDO ログが書き込まれる前にシステムがクラッシュした場合、REDO ログに記録されたトランザクションは無効となり、実際のデータベースの id=2 行のデータは更新されません。
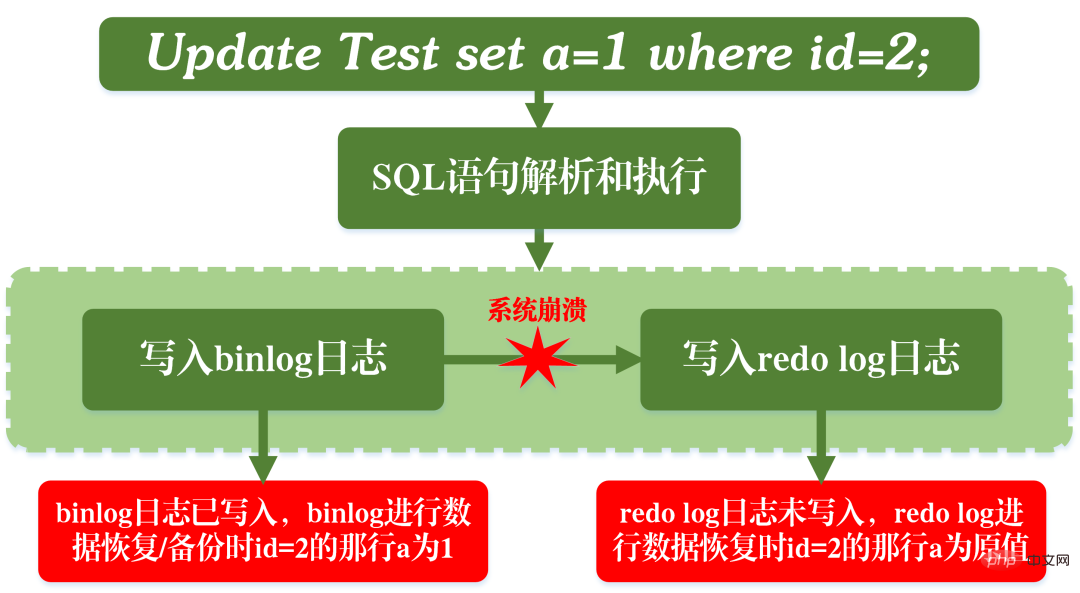
最初に binlog を書き込み、次に redo ログを作成する問題
2 段階の送信は、上記の問題を回避するために binlog を作成するためであることがわかります。 REDO ログと REDO ログに保存される情報は一貫しています。
ロールバック ログ (undo ログ)
ロールバック ログは、InnoDB エンジンによって提供されるログでもあり、名前が示すように、ロールバック ログの機能は次のとおりです。データをロールバックします。トランザクションがデータベースを変更すると、InnoDB エンジンは REDO ログを記録するだけでなく、対応する UNDO ログも生成します。トランザクションの実行が失敗するかロールバックが呼び出され、トランザクションがロールバックされた場合、UNDO ログ内の情報はデータを復元するために使用できます。変更前の状態までスクロールします。
ただし、UNDO ログは REDO ログとは異なり、論理的なログです。 SQL ステートメントの実行に関連する情報を記録します。ロールバックが発生すると、InnoDB エンジンは、元に戻すログのレコードに基づいて、前の作業の逆を実行します。たとえば、各データ挿入操作 (insert) に対して、ロールバック中にデータ削除操作 (delete) が実行され、各データ削除操作 (delete) に対して、ロールバック中にデータ挿入操作 (insert) が実行されます。 update 操作 (update)、ロールバックする場合、データを元に戻すために逆データ更新操作 (update) が実行されます。 Undo ログには 2 つの機能があります。1 つはロールバックを提供することで、もう 1 つは MVCC を実装することです。
3. マスター/スレーブ レプリケーション
マスター/スレーブ レプリケーションの概念は非常に単純で、元のデータベースから同一のデータベースをコピーすることです。はマスター データベースと呼ばれ、レプリケートされたデータベースはスレーブ データベースと呼ばれます。スレーブ データベースはデータをマスター データベースと同期して、2 つのデータベース間のデータの一貫性を維持します。
マスター/スレーブ レプリケーションの原理は、実際には bin ログを通じて実装されます。 bin log ログにはデータベース内のすべての SQL ステートメントが保存されており、bin log ログ内の SQL ステートメントをコピーして実行することで、スレーブ データベースとマスター データベースの間で同期を実現できます。
マスター/スレーブ レプリケーション プロセスを次の図に示します。マスター/スレーブ レプリケーション プロセスは主に 3 つのスレッドによって実行され、送信スレッドはマスター サーバーで実行され、binlog ログをスレーブ サーバーに送信するために使用されます。スレーブ サーバー上では、さらに 2 つの I/O スレッドと SQL スレッドが実行されます。 I/O スレッドは、メイン サーバーから送信された binlog ログの内容を読み取り、それをローカル リレー ログにコピーするために使用されます。 SQL スレッドは、リレー ログ内のデータ更新に関する SQL ステートメントを読み取り、それらを実行してマスター ライブラリとスレーブ ライブラリ間のデータの一貫性を実現するために使用されます。
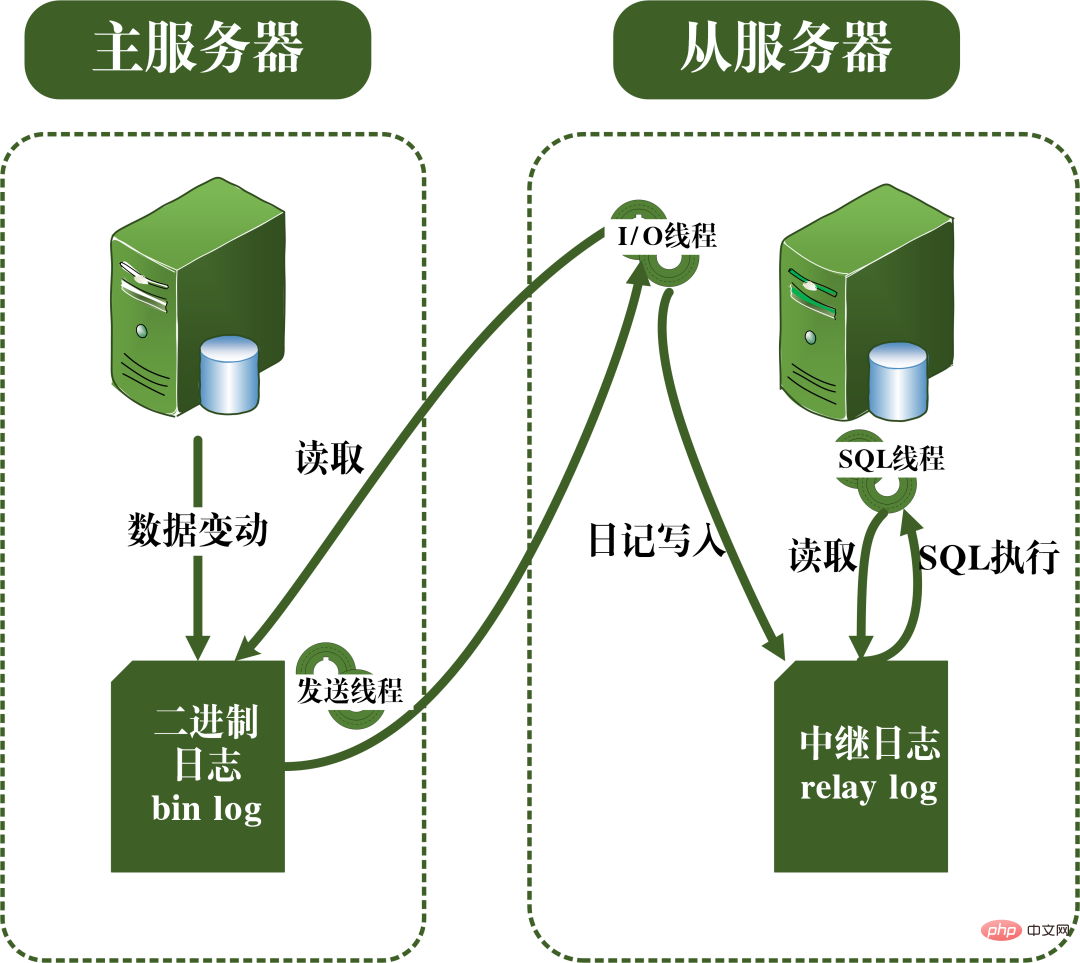
マスター スレーブ レプリケーションの原則
#マスター スレーブ レプリケーションを実装する必要がある理由は、実際には、実際のアプリケーション シナリオによって決まります。マスター/スレーブ レプリケーションによってもたらされる利点は次のとおりです:
1. データのオフサイト バックアップはレプリケーションによって実現され、マスター データベースに障害が発生した場合、データ損失を回避するためにスレーブ データベースを切り替えることができます。
2. アーキテクチャは拡張可能であり、業務量がますます増大し、I/O アクセス頻度が高すぎる場合、マルチデータベース ストレージを使用することでディスク I/O アクセス頻度を減らし、パフォーマンスを向上させることができます。単一マシンの I/O、O パフォーマンス。
3. 読み取りと書き込みの分離を実現できるため、データベースはより優れた同時実行性をサポートできます。
4. 顧客のクエリの負荷をマスター サーバーとスレーブ サーバーに分散して、サーバーの負荷分散を実装します。
概要
MySQL データベースは、プログラマーが習得しなければならないテクノロジーの 1 つと見なされるべきです。プロジェクトの進行中であっても、面接中であっても、MySQL は非常に重要な基礎知識です。ただし、MySQL には本当に必要なことが多すぎます。この記事を書くにあたり、色々な情報を参考にしましたが、理解できないことが多ければ多いほどわかりました。これは本当に次の格言に当てはまります:
知れば知るほど、知らないことも増えます。
この記事では、MySQL の基本トランザクションとロギング システムの基本原理を理論的な観点から分析することに重点を置いており、説明する際には実際のコードを使用して説明することは避けるようにしています。 10,000 語近くの単語と 20 近くの手書きのイラストを含むこの記事でも、MySQL の幅広さと奥深さを完全に分析することはできません。
しかし、初心者にとって、これらの理論は MySQL の全体的な認識を与え、「リレーショナル データベースとは何か」という質問をより明確に理解できると信じています。また、MySQL に精通している人にとっては、おそらくこの記事は、長い間失われていた根本的な理論的基礎を目覚めさせることができ、その後の面接にも役立ちます。
テクノロジーに絶対的な善悪はありません。記事に間違いがあった場合はご容赦ください。また、議論を歓迎します。独立した思考は、受動的に受け入れるよりも常に効果的です。
推奨学習: mysql ビデオ チュートリアル
以上がMySQL トランザクション ログを一緒に分析しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。