| select_type |
クエリ タイプ |
| table |
結果セットを出力するテーブル |
| type |
テーブルの接続タイプ |
| possible_keys |
クエリ時に使用できるインデックス |
#key | 実際に使用されるインデックス |
key_len | インデックス フィールドの長さ |
#ref
| 列とインデックスの比較 |
|
rows
| スキャンされた行数 (推定行数) ) |
|
追加
| 実行の説明と説明 |
|
3. 各フィールドの意味の説明
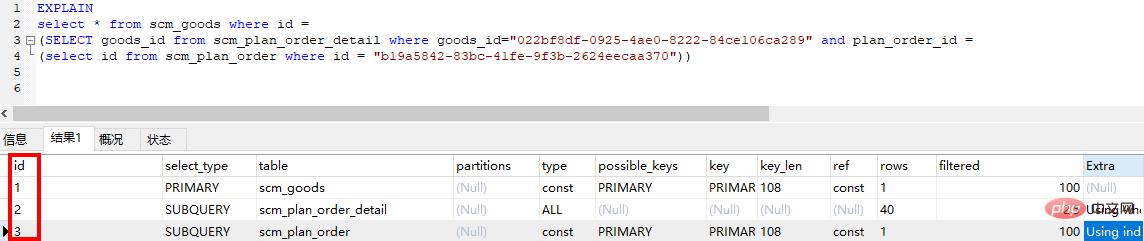
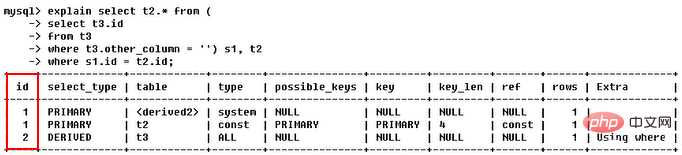
3.1 id
id は、一連の数字を含む選択クエリのシーケンス番号です。クエリの実行を示す select 句または操作テーブルの順序。 id の結果は以下の 3 つの状況があります。
●● id が同じで、実行順序は sql

# の順序に関係なく上から下になります。 # 子クエリの場合、id の通し番号が大きくなり、id が大きいほど優先度が高く、より早く実行されます
## ●● id が同じ場合は上から順にグループとみなし、すべてのグループ内で id の値が大きいほど優先順位が高く、最初に実行されます。
3.2 select_type select_typeクエリ内の各 select 句のタイプ、一般的に使用される select_type のタイプを表示します。シンプル、プライマリ、サブクエリ、派生、ユニオン、ユニオン結果があります
(1) simple (単純な選択、ユニオンやサブクエリなどの複雑なクエリは使用しません)
(2) primary (サブクエリの最も外側のクエリ。クエリに複雑なサブパートが含まれている場合、最も外側の選択がプライマリとしてマークされます)
Sync (3) subquery (select または where リストに含まれるサブクエリ)
Sync (4) derived (サブクエリfrom リストに含まれるサブクエリは派生 (派生) としてマークされており、MySQL はこれらのサブクエリを再帰的に実行し、結果を一時テーブルに置きます)
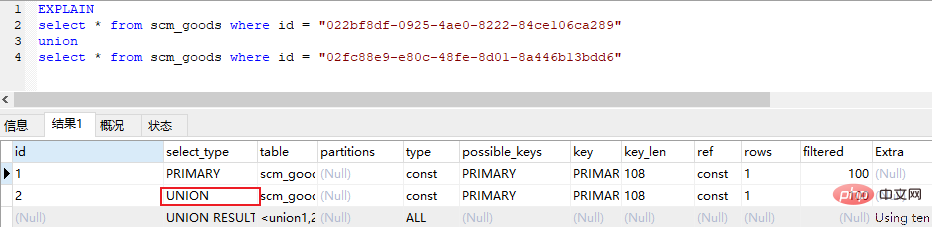
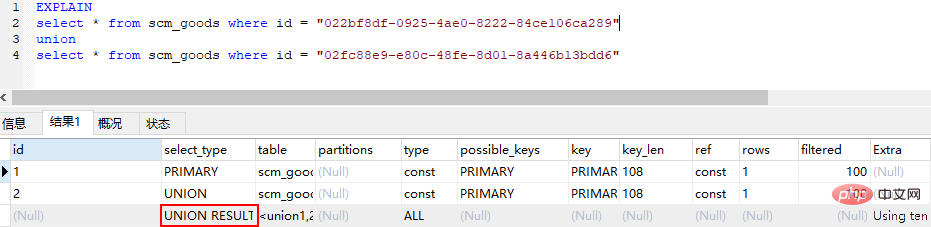
(5) union (2 番目以降の selectユニオン内のステートメント)
(6) union result (ユニオンの結果、union ステートメントの 2 番目の select ステートメント以降のすべての選択) select start)
##3.3 table
table このステップでアクセスするデータベース内のテーブルの名前を表示します (表示このデータ行はどのテーブルを参照していますか?)。
3.4 type
type は、クエリで使用される型を示します。型には、all、index、range、ref、eq_ref、const、system、NULL が含まれます、そのパフォーマンスは順番に向上します。
all: フル テーブル スキャン、MySQL はテーブル全体を走査して一致する行を見つけます
## ● ● index
: フル インデックス スキャン。インデックスと ALL の違いは、インデックス タイプがインデックス ツリーのみをスキャンすることです。
· range
: 取得のみを実行します。指定された範囲内の行。インデックスを使用して行を選択します。
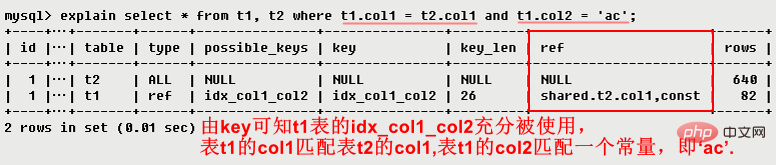
· ref
: 上記のテーブルの結合一致条件を示します。列または定数は、インデックス列を検索するために使用されます。
の値 ● eq_ref
: ref と同様ですが、使用されるインデックスが異なる点です。一意のインデックス 各インデックス キー値について、テーブル内に 1 つだけ存在します レコード マッチングとは、簡単に言えば、複数テーブル接続での関連付け条件として主キーまたは一意キーを使用することです これらの型を使用して定数にアクセスします。主キーが where リストに配置されている場合、MySQL はクエリを定数に変換できます。System は const タイプの特殊なケースです。クエリされたテーブルに 1 行しかない場合は system を使用してください。
## ● NULL : MySQL は最適化プロセス中にステートメントを分解し、実行中にテーブルやインデックスにアクセスする必要さえありません (選択など)。インデックス列の最小値 これは、別のインデックス検索によって実行できます。
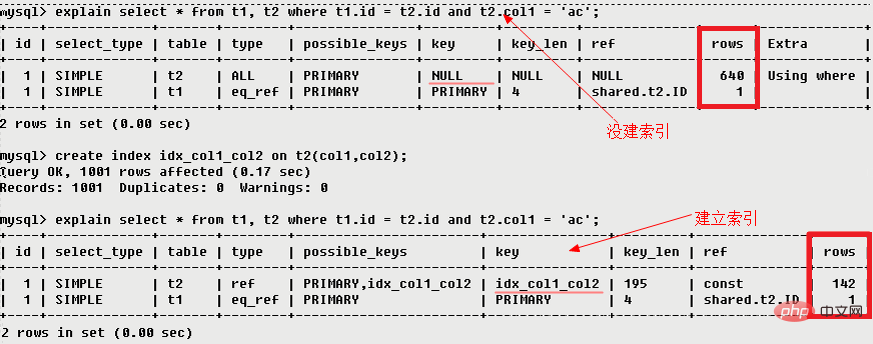
3.5 possible_keys
possible_keysこのテーブルに適用できる 1 つ以上のインデックスを表示します。クエリに関係するフィールドにインデックスが存在する場合、そのインデックスはリストに表示されますが、 ですが、実際にはクエリ
で使用されない可能性があります。 (このクエリが利用できるインデックス。インデックスがない場合は null が表示されます)
3.6 key
keyMySQL が実際に使用することを決定したキー (インデックス) を表示します。これは possible_keys に含める必要があります。インデックスが選択されていない場合は NULL。 MySQL に possible_keys 列のインデックスの使用または無視を強制するには、クエリで forceindex、useindex、または ignoreindex を使用します。
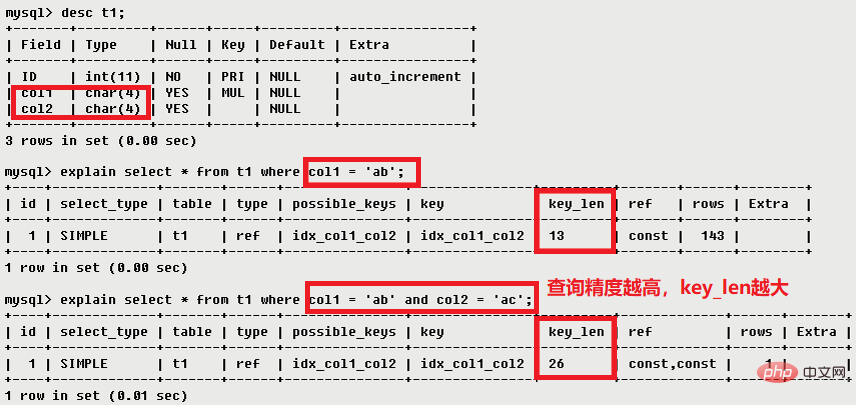
3.7 key_len
key_len は、インデックスで使用されるバイト数を表します。この列は、クエリで使用されるインデックスの長さを計算するために使用できます。 (key_len によって表示される値は、実際に使用される長さではなく、インデックス フィールドの可能な最大長です。つまり、key_len はテーブルから取得されるのではなく、テーブル定義に基づいて計算されます)。精度を損なうことなく、長さが短ければ短いほど、長ければ長いほど良いです。##。
3.8 ref
インデックスを表示する列は、上記の表の接続一致条件を示すために使用されます。つまり、どの列または定数は、インデックス列の値を見つけるために使用されます。行数は、テーブル統計とインデックス選択に基づいて、必要なレコードを見つけるために読み取る必要がある行数を MySQL が推定することを示します。
3.10 補足
補足この列には、クエリを解決する MySQL に関する詳細情報が含まれています。次のような状況があります。
要求されたカラムがすべて同じインデックスの一部である場合、ストレージ エンジンが行を取得した後に mysql サーバーが行をフィルタリングすることを意味します。 MySQL が使用する必要があることを示します 一時テーブルは、クエリの並べ替えとグループ化で一般的に使用される結果セットを保存するために使用されます。操作による順序付け、インデックスによるソートは使用できません。この操作は「ファイル ソート」と呼ばれます。
結合バッファーの使用変更された値は、取得時にインデックスが使用されないことを強調します。結合条件、および中間結果を保存するために結合バッファーが必要です。この値が表示される場合は、クエリの特定の条件によっては、パフォーマンスを向上させるためにインデックスの追加が必要になる場合があることに注意してください。
#Impossible where この値は、where ステートメントの結果として条件を満たす行が存在しない (統計の収集では存在し得ない結果) ことを強調します。
● 最適化されたテーブルを選択 この値は、インデックスのみを使用することにより、オプティマイザが集計関数の結果から 1 行のみを返すことを意味します。
●
テーブルなしused Queryuses from Dual or doesn't contain any from clause
4. まとめ ● Explain では、トリガー、ストアド プロシージャ、ユーザーに関する情報はわかりません。クエリのカスタム関数
● Explain はさまざまな Cache を考慮しません ● Explain はクエリの実行時に MySQL によって行われた最適化作業を表示できません
● Explain できるのは選択操作の Explain だけです、その他の操作は select に書き換えて実行プランを表示する必要があります ● 一部の統計情報は推定値であり、正確な値ではありません
推奨学習: mysql ビデオ チュートリアル






 index
index  range
range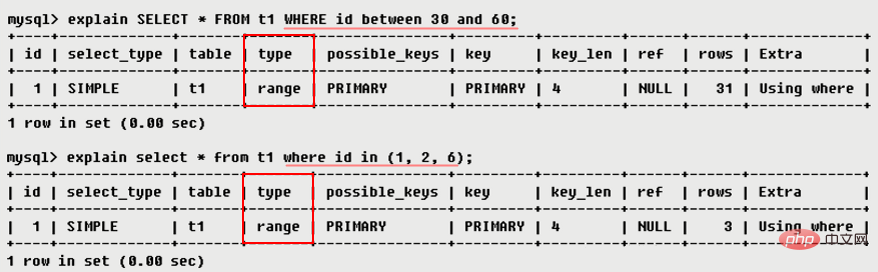 ref
ref eq_ref
eq_ref