
ホームページ >データベース >mysql チュートリアル >mysqlのクラスター化インデックスと非クラスター化インデックスの違いは何ですか
mysqlのクラスター化インデックスと非クラスター化インデックスの違いは何ですか

- 青灯夜游オリジナル
- 2022-03-01 14:51:3321315ブラウズ
違い: 1. クラスター化インデックスはテーブル内のデータをリーフ ノードに保存しますが、非クラスター化インデックスは主キーとインデックス列をリーフ ノードに保存します。クラスター化インデックス内のテーブル レコード 並べ替え順序は一貫していますが、非クラスター化インデックスの並べ替え順序は一貫していません; 3. 各テーブルにはクラスター化インデックスが 1 つだけ存在できますが、非クラスター化インデックスは複数存在できます。

このチュートリアルの動作環境: Windows7 システム、mysql8 バージョン、Dell G3 コンピューター。
MySQL の Innodb ストレージ エンジンのインデックスは、クラスター化インデックスと非クラスター化インデックスの 2 つのカテゴリに分類されており、中国語辞書のインデックスを比較することでクラスター化インデックスと非クラスター化インデックスを理解できます。中国語辞書には、中国語の文字を検索する 2 つの方法が用意されています。1 つ目は、ピンイン検索 (漢字の発音がわかっている場合) です。たとえば、cheng のピンインを持つ漢字は、cheng のピンインを持つ漢字の後にランク付けされます。対応する中国語のページ番号はピンインに基づいて検索されます (ピンインの並べ替えを押すとバイナリ検索がすぐに見つかるため)、これは通常辞書の順序と呼ばれるものです。2 番目のタイプは部首ストローク検索で、対応する中国語を検索します。画数に応じて文字を読み、その漢字に対応するページ番号を見つけます。ピンイン検索は、格納されたレコード (データベース内の行データ、辞書内の漢字の詳細レコード) が、ストローク インデックス (ストローク インデックス内で同じストロークを持つ単語が隣接している場合でも) に従ってソートされるため、クラスター化インデックスとなります。実際のストレージ ページ番号は隣接していません。これは非クラスター化インデックスです。
クラスター化インデックス
インデックス内のキー値の論理的順序によって、テーブル内の対応する行の物理的順序が決まります。
クラスター化インデックスは、テーブル内のデータの物理的な順序を決定します。クラスター化インデックスは、データが姓ごとに配置されるという点で電話帳に似ています。クラスター化インデックスは、範囲値が頻繁に検索される列に特に効果的です。クラスター化インデックスを使用して最初の値を含む行を検索すると、後続のインデックス値を含む行が物理的に隣接していることを確認できます。たとえば、アプリケーションが特定の日付範囲内のレコードを頻繁に取得するクエリを実行する場合、クラスター化インデックスを使用して開始日を含む行をすばやく検索し、終了日に達するまでテーブル内の隣接するすべての行を取得できます。これは、そのようなクエリのパフォーマンスの向上に役立ちます。同様に、テーブルから取得したデータを並べ替えるときに列が頻繁に使用される場合、テーブルをその列でクラスタリング (物理的に並べ替え) することで、その列がクエリされるたびに並べ替える必要がなくなり、コストを節約できます。
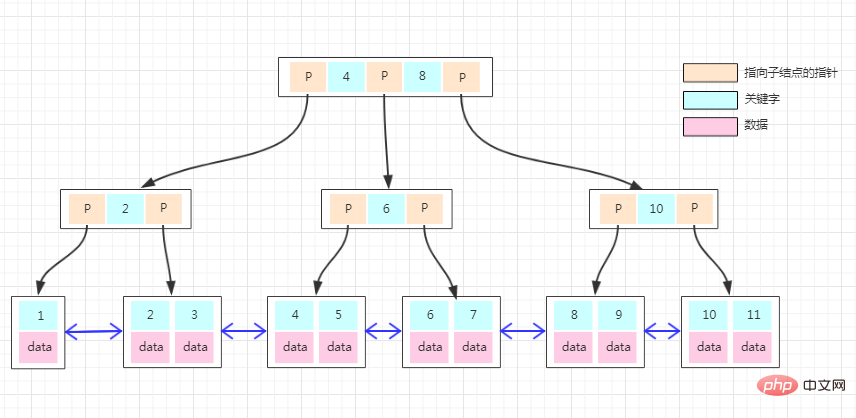
上記は innodb の b ツリー インデックス構造です。
b ツリーは、m 次の B ツリーである b ツリーから進化したことがわかります。
1. 各ノードは最大 m 個の子ノードを持つことができます。
2. ルート ノードとリーフ ノードを除き、各ノードには少なくとも m/2 (切り上げ) の子ノードがあります。
3. ルート ノードがリーフ ノードでない場合、ルート ノードには少なくとも 2 つの子ノードが含まれます。
4. すべてのリーフ ノードは同じレイヤーに配置されます。
5. 各ノードには k 個の要素 (キーワード) が含まれます (m/2 ≤ k 6. 各ノード内の要素(キーワード)は、小さいものから大きいものへと配置されています。
7. 各要素 (キーワード) の左ノードの値は、要素 (キーワード) 以下です。右側のノードの値は要素(キーワード)以上です。
b ツリーの特性は次のとおりです:
1. すべての非リーフ ノードはキーワード情報のみを保存します。
2. すべての衛星データ (特定のデータ) はリーフ ノードに格納されます。
3. すべてのリーフ ノードには、すべての要素に関する情報が含まれています。
4. すべてのリーフ ノード間にはリンク ポインタがあります。
b trre には次の特性があることがわかりました:
- は範囲内のクエリ (リーフ チェーン ポインタを介した) に対して特に効果的で高速です;
- は特定のクエリに特に効果的 キー値クエリは、B ツリーよりもわずかに効率が劣ります (リーフ レベルに移動する必要があるため) が、無視することもできます。クラスター化インデックス
インデックス ディスク内のインデックスの論理的順序は、ディスク上の行の物理的な格納順序とは異なります。 実際、定義によれば、クラスター化インデックス以外のインデックスは非クラスター化インデックスですが、人々は非クラスター化インデックスを通常のインデックス、一意のインデックス、およびフルテキスト インデックスに細分したいと考えています。非クラスター化インデックスを現実のものにたとえる必要がある場合、非クラスター化インデックスは新華社辞書の部首辞書のようなものであり、その構造順序は実際の格納順序と必ずしも一致しません。
非クラスター化インデックスのストレージ構造は以前と同じですが、違いは、リーフ ノードのデータ部分には特定のデータが格納されなくなり、集計が格納されることです。データのインデックスのキー。したがって、非クラスター化インデックスを介して検索するプロセスは、最初にインデックス キーに対応するクラスター化インデックスのキーを見つけ、次にクラスター化インデックスのキーを使用して、主キー インデックス ツリー上で対応するデータを見つけることです。プロセスは table return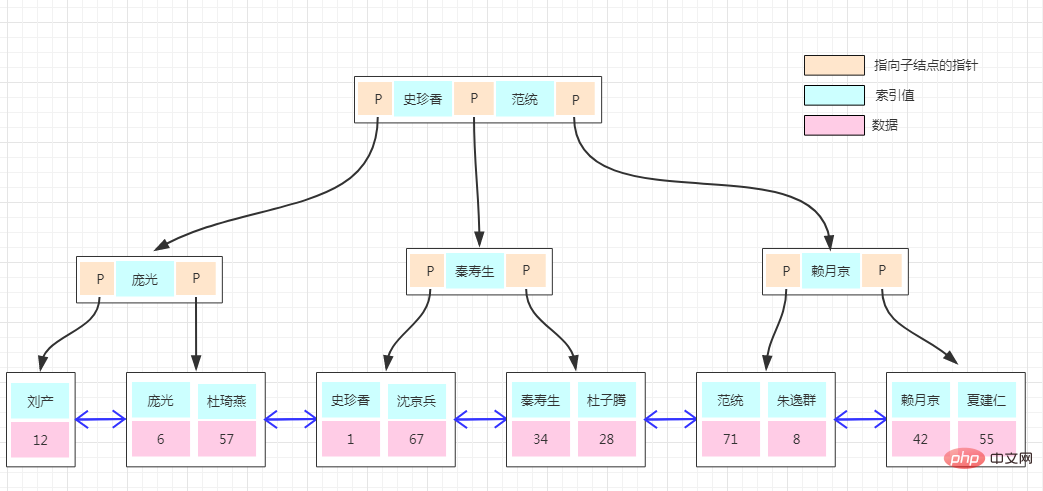 と呼ばれます。
と呼ばれます。
例を示します: create table student (
`id` INT UNSIGNED AUTO_INCREMENT,
`username` VARCHAR(255),
`score` INT,
PRIMARY KEY(`id`), KEY(`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
クラスター化インデックス クラスター化インデックス(ID)、非クラスター化インデックス インデックス(ユーザー名)。
使用以下语句进行查询,不需要进行二次查询,直接就可以从非聚集索引的节点里面就可以获取到查询列的数据。
select id, username from t1 where username = '小明' select username from t1 where username = '小明'
但是使用以下语句进行查询,就需要二次的查询去获取原数据行的score:
select username, score from t1 where username = '小明'
聚集索引和非聚集索引区别
区别一:
聚集索引:就是以主键创建的索引,在叶子节点存储的是表中的数据
非聚集索引:就是以非主键创建的索引(也叫做二级索引),在叶子节点存储的是主键和索引列。
区别二:
聚集索引中表记录的排列顺序和索引的排列顺序一致;所以查询效率快,因为只要找到第一个索引值记录,其余的连续性的记录在物理表中也会连续存放,一起就可以查询到。缺点:新增比较慢,因为为了保证表中记录的物理顺序和索引顺序一致,在记录插入的时候,会对数据页重新排序。
非聚集索引中表记录的排列顺序和索引的排列顺序不一致。
区别三:
聚集索引是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储不连续。
区别四:
聚集索引每张表只能有一个,非聚集索引可以有多个。
【相关推荐:mysql视频教程】
以上がmysqlのクラスター化インデックスと非クラスター化インデックスの違いは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。