
ホームページ >データベース >mysql チュートリアル >MySQL インデックスの最下層と最適化について話しましょう
MySQL インデックスの最下層と最適化について話しましょう

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-02-14 18:47:541992ブラウズ
この記事では、mysql の最下層とインデックスの最適化についての知識を提供します。mysql のインデックスに関する知識ポイントを整理しましょう。皆様のお役に立てれば幸いです。

Mysql インデックスの章
最近、多くの Web サイトでインデックス作成に関する知識について読みました。さまざまな意見がありますが、包括的なものではありません。コンセプトは次のとおりです。以下は、エディターによってまとめられた Mysql インデックスのナレッジ ポイントです。
1. まず、インデックスとは何か、そしてインデックスを使用する必要がある理由について説明します。
インデックスは、列内の特定の値を持つ行をすばやく見つけるために使用されます。インデックス。MySQL は次から開始する必要があります。最初のレコードは、関連する行が見つかるまでテーブル全体の読み取りを開始します。テーブルが大きくなるほど、データのクエリに時間がかかります。テーブル内でクエリされるカラムにインデックスがある場合、MySQL は次のことを行うことができます。ファイルを使用すると、すべてのデータを確認する必要がなくなり、時間を大幅に節約できます。
2. インデックス タイプは 2 つのカテゴリに分類されます:
1.hash Index
2.bTree
3. ハッシュ インデックスとbツリーインデックス。
1. ハッシュ テーブルは、キーと値を使用してデータを格納する構造であり、検索するキー、つまりキーを入力するだけで、対応する値が検索されます。価値。ハッシュの考え方は非常にシンプルで、配列に値を入れ、ハッシュ関数を使ってキーを特定の位置に変換し、その値を配列のその位置に入れます。
ハッシュ関数で変換すると、必然的に複数のキー値が同じ値になります。この状況に対処する 1 つの方法は、リンクされたリストを取り出すことです。
2. bTree といえばバイナリ ツリーについて言及する必要があります。バイナリ ツリーは、二分探索ツリー、バランス二分ツリー、等もちろん、重要なポイントである 红黑木 もあります。
1) 二分探索木の特性は次のとおりです: 親ノードの左側のサブツリー内のすべてのノードの値は、次の値より小さいです。親ノード。右側のサブツリー内のすべてのノードの値は、親ノードの値より大きくなります。 以下では、二分探索ツリーを説明するための例として図を使用します。
| ID | 名前 |
|---|---|
| 张五 | |
| 张六 | #7 |
| ##2 | 张二 |
| 1 | 张一 |
| 4 | 张四 |
| #3 | 张三 |
| #
5) B ツリー : 上で述べたように、BTree はツリーの高さを制御し、Mysql のインデックス作成のニーズを満たすことができますが、最終的には Mysq インデックスの実装がは BTree ではなく B Tree ですが、Mysql が B-tree に少し手を加えて B-tree を取得したものであり、B-tree のアップグレード版であることもわかります。 この図からわかるように、非リーフ ノードはインデックスのみを格納し、データは格納しません。また、ノード間ではポインタが使用されます。リーフノードが接続されています。 B ツリーのリーフ ノードと非リーフ ノードの両方にインデックスとデータが格納され、リーフ ノードのポインタは空です。B ツリーはデータをリーフ ノードに配置するため、非リーフ ノードはインデックスとデータを格納できます。毎回、より多くのインデックス ディスク IO からより多くのインデックスを取得することもできます。 Baidu で描画された B ツリーと多くのブログ それは間違っています、穴を避けなければなりません。 4. インデックスの分類1. インデックスのストレージの関連付けによる分類: 大きく 2 つのカテゴリに分かれます 1.1) MySQL には、MyISAM と InnoDB という 2 つの一般的に使用されるストレージ エンジンがあることは誰もが知っていますが、2 つのストレージ エンジンの基礎となるデータ ストレージ構造を実際に理解していますか? 2. 機能別分類: 主に 5 つのカテゴリに分類されます 3. 2.2 で、通常のインデックスにはテーブルの戻り操作が必要であると述べましたが、テーブルの戻り操作を必要としない通常のインデックスはありますか? 答えは「はい」です。特定のクエリでは、インデックスはすでにクエリのニーズをカバーしているため、これをカバーインデックスと呼びます。このとき、テーブルに戻る必要はありません。 例: 以下は、このテーブルの初期化ステートメントです。 mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'), (300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg'); 上記のテーブル T で、select * from T (k は 3 ~ 5) を実行すると、ツリー検索操作は何回実行する必要があり、スキャンされる行は何行になりますか? この処理のうち、主キーインデックスツリー検索に戻る処理をテーブルリターン といいます。このクエリ プロセスは、k インデックス ツリーの 3 つのレコードを読み取り (ステップ 1、3、および 5)、テーブルを 2 回返します (ステップ 2 と 4)。 この例では、クエリ結果に必要なデータは主キー インデックス上にのみあるため、テーブルに返す必要があります。実行されたステートメントが select ID from T where k between 3 and 5 の場合、現時点では、ID の値を確認するだけでよく、ID の値はすでに k インデックスに含まれています。ツリーなので、直接提供できます。クエリ結果をテーブル に返す必要はありません。つまり、このクエリでは、インデックス k にクエリ要件が「covered 」あり、これをカバリング インデックスと呼びます。 InnoDB では、テーブルは主キーの順序に従ってインデックス形式で格納され、このように格納されたテーブルはインデックス構成テーブルと呼ばれます。前述したように、InnoDB は B ツリー インデックス モデルを使用するため、データは B ツリーに保存されます。各インデックスは InnoDB の B ツリーに対応します。 5. インデックスの最適化1. 上記では、インデックスの基本概念、分類、および基礎となる基本的な構造関連の知識について説明しています。インデックスの最適化に関する関連知識について話しましょう。1.) create table employees(
id int primary key auto_increment comment '主键自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年龄',
id_card varchar(40) not null default '' comment '身份证号',
position varchar(40) not null default '' comment '位置'
);
-- 创建联合索引
create index name_index on employees (name,age,position);
-- 插入一条数据
insert into employees(name,age,id_card,position) values('张三',15,
'201124199011035321','北京');
-- 下面以10条sql测试,注意建立的联合索引顺序是 name,age,position 1.explain select * from employees where age=15 and position='北京' and name='张三'; 2.explain select * from employees where name='张三' and age=15 and position='北京'; 3.explain select * from employees where age=15 and name='张三'; 4.explain select * from employees where position='北京' and name='张三'; 5.explain select * from employees where position='北京' and age=15; 6.explain select * from employees where position='北京' and age>15 and name='张三'; 7.explain select * from employees where position='北京'; 8.explain select * from employees where age=15; 9.explain select * from employees where name='张三'; 10.explain select * from employees where name != '张三'; 以上10条sql有哪些是索引失效,有哪些是索引没有失效的呢? 相信同学们已经有了答案,但是答案对不对呢,下面我们一起分析下。 首先说第1条,查询条件把3个索引全部用上了,但是索引的顺序有变化,由name,age,position变成 了age,position,name,想到这里肯定有很多同学给出的答案就是索引失效,但是事实证明这个结果 是错的,索引生效,肯定有很多同学疑惑,为什么呢,这条sql不满足最左原则法则呀,这就要涉及到sql 的执行流程了,这里博主简单说下,sql执行有1个优化器的过程,优化器的作用之一就是索引的选择优化, 所以优化器帮我们把索引的顺序变成正确的了,所以索引生效。 下面是第1条按照索引顺序sql和第2条没有按照索引顺序sql的执行结果。 执行结果入下图:可以发现全部生效。最初の SQL 型の値は ref、バイトは 288、ref には 3 つの const があり、それらはすべて有効です。
想学习sql的执行流程的可以看博主的另一篇关于sql执行流程的文章哦。 有的同学有疑问了,那最左原则没有用了吗? 答案:有用的。 现在我们说下第3、4、5条sql 第3条: explain select * from employees where age=15 and name='张三'; sql在执行的时候,优化器替我们把索引的顺序优化了,由 age -> name 变成 name -> age,这时 索引是生效的。 第4条: explain select * from employees where position='北京' and name='张三'; 索引顺序优化为name - > position,但是这时索引只有name索引生效,position没有生效,因为我 们建立的索引顺序是 name -> age - > position,你会发现跳过了age,索引本质也是一棵树,少 了一个节点,下面的索引当然不会生效了,这就没有满足最左原则法则。 第5条: explain select * from employees where position='北京' and age=15; 这就和第4条sql一样的道理了,第一个索引都不见了,后面的不可能生效。 执行结果如下:3 番目の SQL 型の値は ref で、バイトは 126、ref には 2 const があり、すべて有効であることがわかります。
下面说第6条sql,剩下的sql都是和之前的sql一样的道理。 explain select * from employees where position='北京' and age>15 and name='张三'; 这条sql我们会发现,把索引字段全部使用了并且当作条件查询,不一样的是age是范围查找,优化器替我 们把索引顺序优化成 name -> age - > position ,按照我们索引优化第2条:在列上做计算索引失效,范围之后的索引全部失效,想必答案同学们都知道了。 执行结果如下:第 6 条 SQL は 126 バイトしかなく、型の値は範囲です。範囲検索の場合、名前と年齢のインデックスのみが有効です。
推奨学習: mysql ビデオ チュートリアル ### |
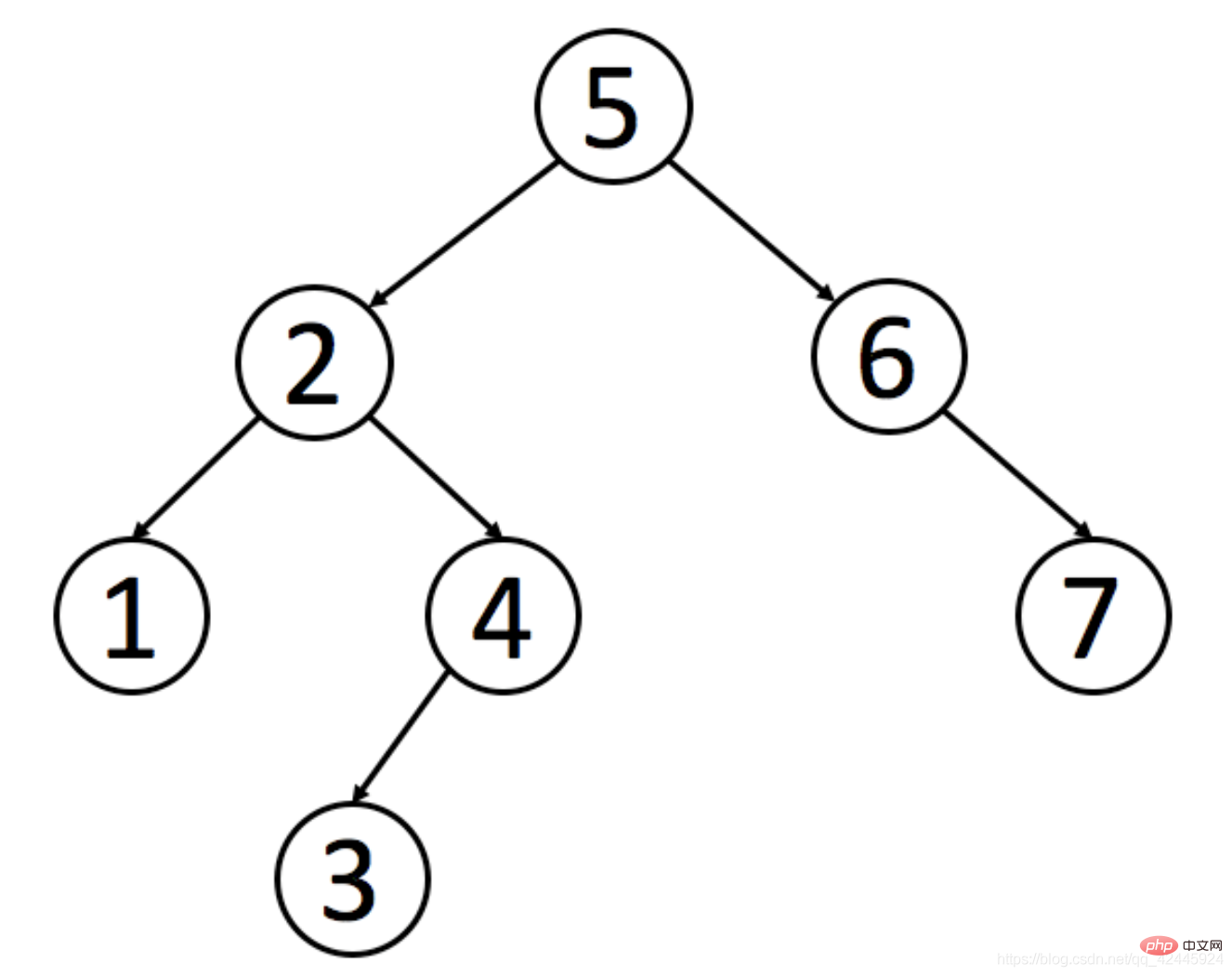 Zhang San を見つけるための要件があります。二分探索木を使用しない場合、7 回検索する必要があります。二分探索木を使用すると、必要な値を見つけるのに 4 回の検索だけで済みます。欲しい。
Zhang San を見つけるための要件があります。二分探索木を使用しない場合、7 回検索する必要があります。二分探索木を使用すると、必要な値を見つけるのに 4 回の検索だけで済みます。欲しい。 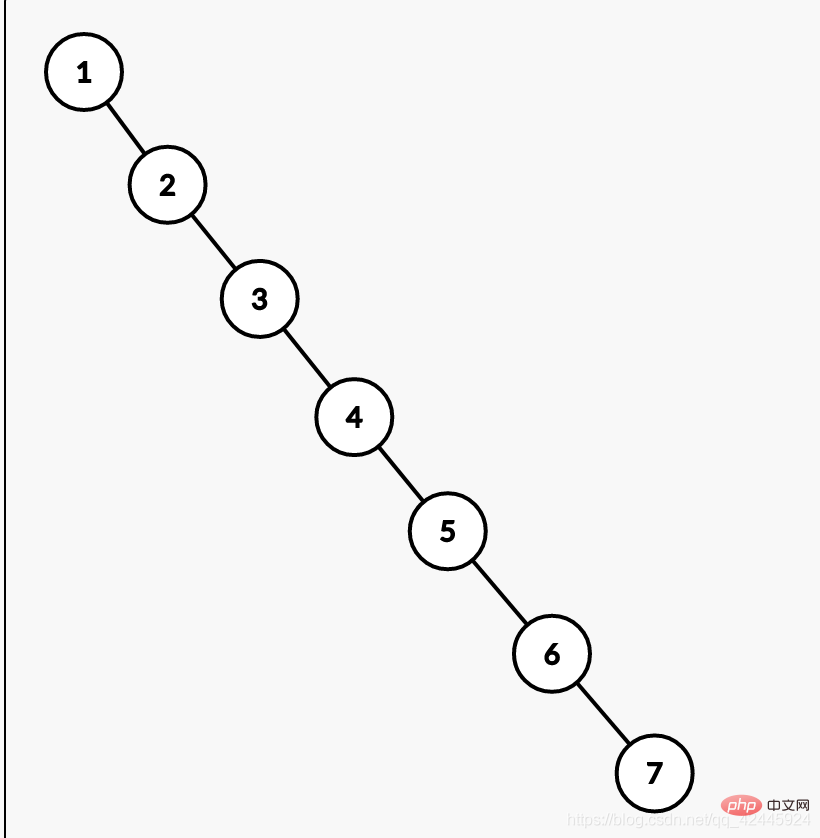
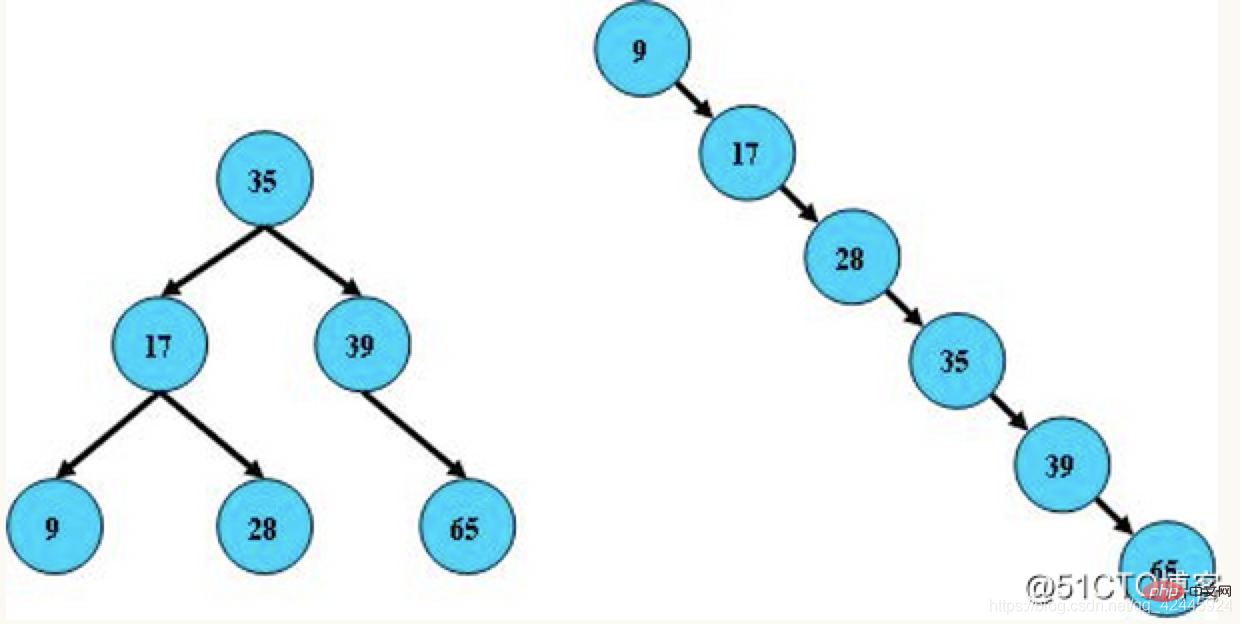 3) 赤黒の木 : 赤黒の木は、上にある木であることがわかります。バランスの取れたバイナリ ツリー 赤黒ツリー このツリーは「完全なバランス」を追求するのではなく、バランス要件を部分的に達成することのみを追求し、回転要件を軽減してパフォーマンスを向上させます。さらに、その設計により、アンバランスは 3 回転以内に解決されます。赤黒ツリーでは、アルゴリズムの時間計算量は AVL と同じであり、統計的パフォーマンスにより AVL ツリーの方が高くなります。したがって、赤黒ツリーは、バランス二分木と比較して、厳密な意味でのバランス二分木ではなく、赤黒ツリーの挿入・削除効率は高く、クエリ効率は相対的に低くなります。ただし、この 2 つの間のクエリ効率の違いは、比較すると基本的に無視できるほどです。赤黒木の特徴は次のとおりです。
3) 赤黒の木 : 赤黒の木は、上にある木であることがわかります。バランスの取れたバイナリ ツリー 赤黒ツリー このツリーは「完全なバランス」を追求するのではなく、バランス要件を部分的に達成することのみを追求し、回転要件を軽減してパフォーマンスを向上させます。さらに、その設計により、アンバランスは 3 回転以内に解決されます。赤黒ツリーでは、アルゴリズムの時間計算量は AVL と同じであり、統計的パフォーマンスにより AVL ツリーの方が高くなります。したがって、赤黒ツリーは、バランス二分木と比較して、厳密な意味でのバランス二分木ではなく、赤黒ツリーの挿入・削除効率は高く、クエリ効率は相対的に低くなります。ただし、この 2 つの間のクエリ効率の違いは、比較すると基本的に無視できるほどです。赤黒木の特徴は次のとおりです。 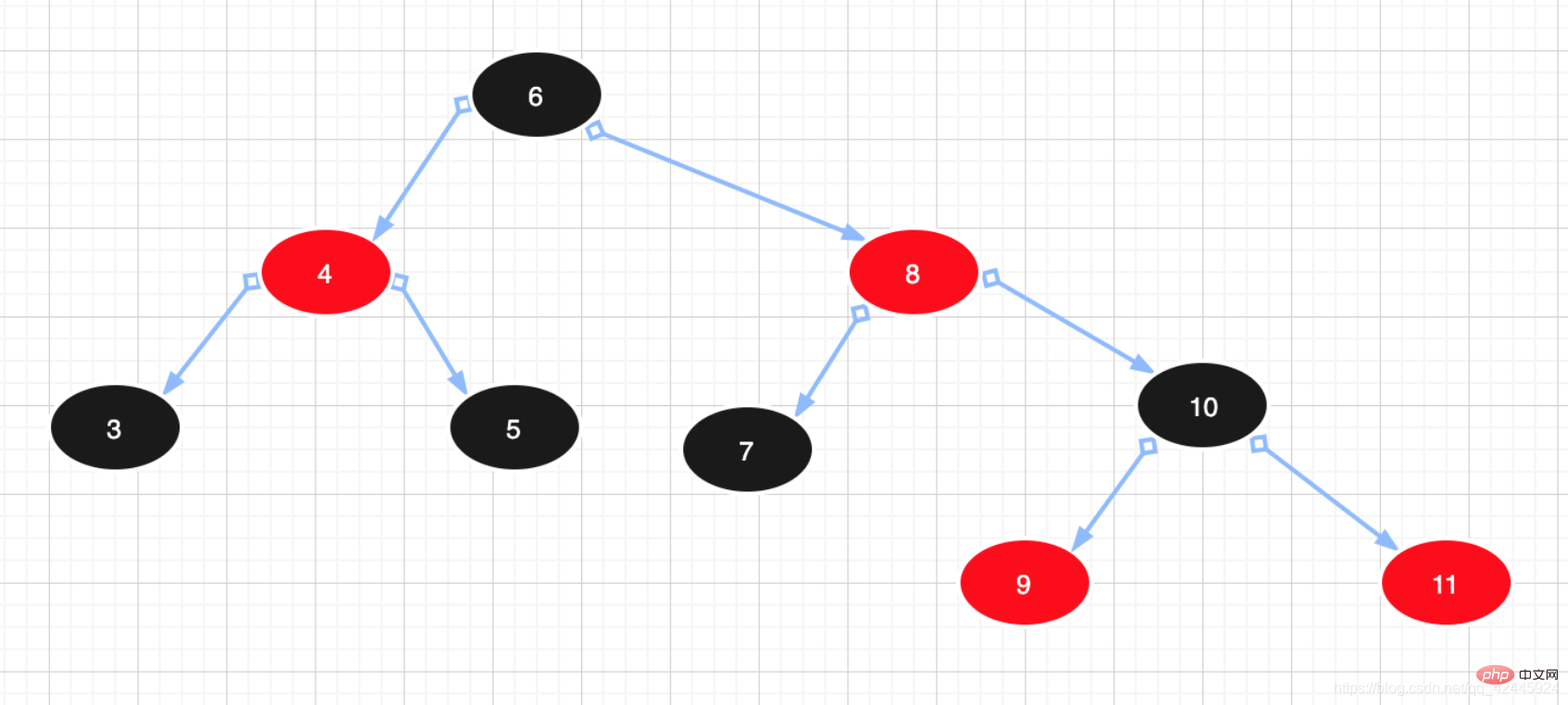
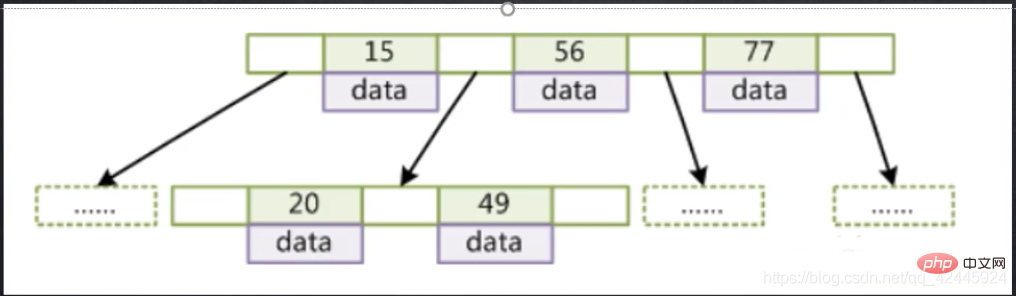 BTree:
BTree: 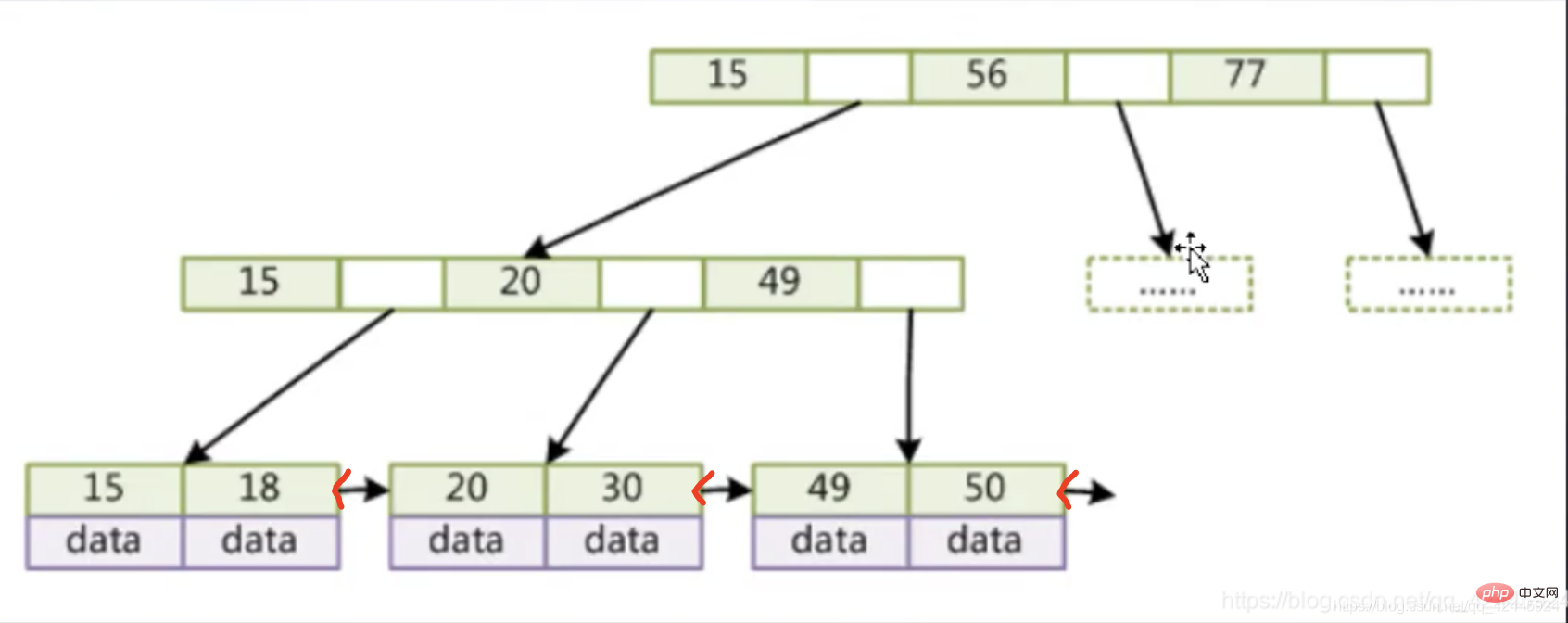
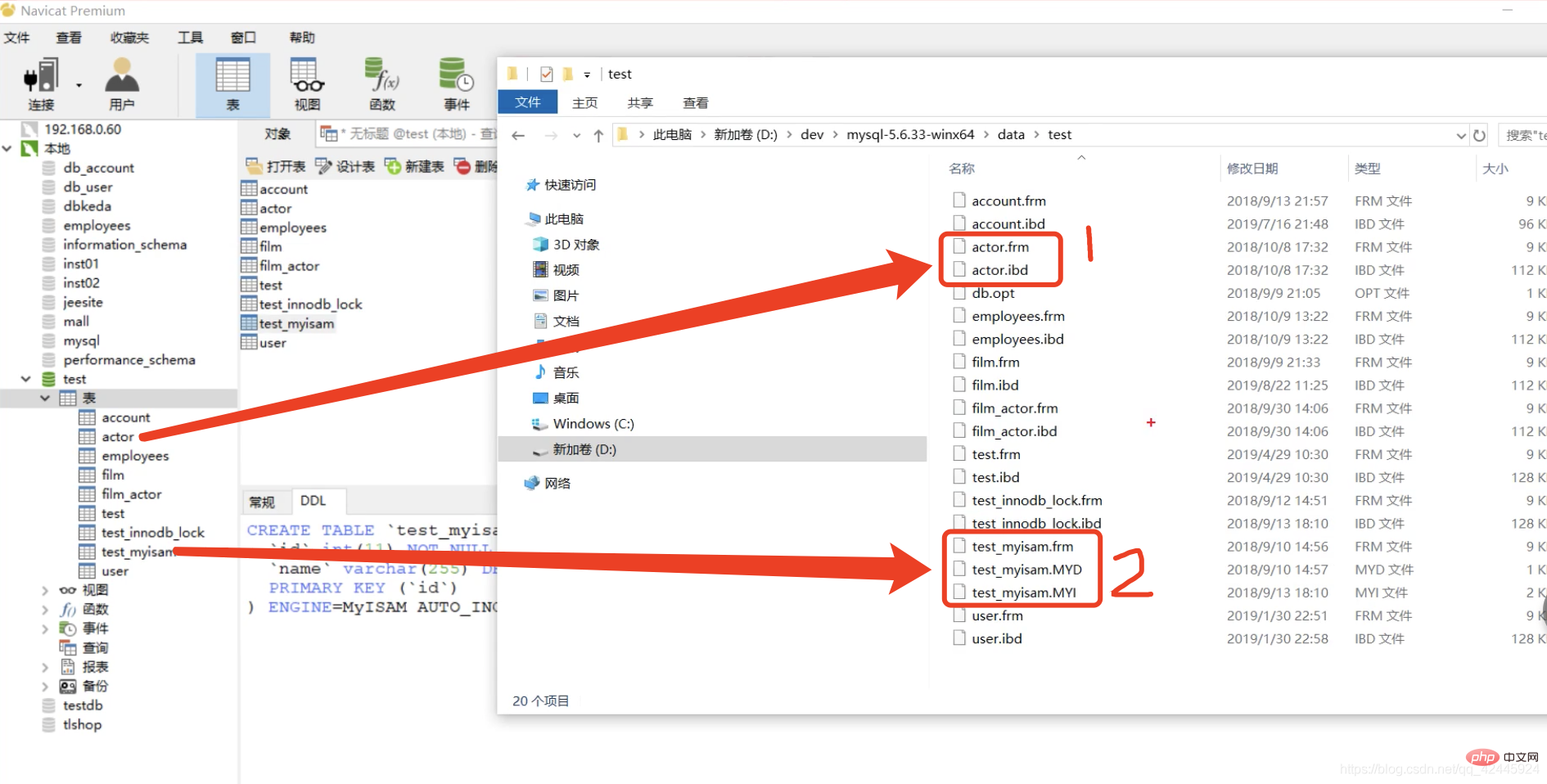 test.myisam テーブルは MyISAM ストレージ エンジンであり、アクター テーブルは InnoDB ストレージ エンジンです。MyISAM ストレージ エンジンには 3 つのストレージ エンジンがあることがわかります。ファイル、つまりfrmとMYD、MYIはfrm-frameの略で分かりやすい テーブルの構造を格納する MYD-MYDataにデータが格納される MYI-MYIndexにインデックスが格納される インデックスとデータが格納されるInnoDB には frm と IBD のみがあり、frm も格納されるテーブルの構造は同じであり、IBD ファイルにはインデックスとデータが格納される点が InnoDB や MyISAM とは異なります。
test.myisam テーブルは MyISAM ストレージ エンジンであり、アクター テーブルは InnoDB ストレージ エンジンです。MyISAM ストレージ エンジンには 3 つのストレージ エンジンがあることがわかります。ファイル、つまりfrmとMYD、MYIはfrm-frameの略で分かりやすい テーブルの構造を格納する MYD-MYDataにデータが格納される MYI-MYIndexにインデックスが格納される インデックスとデータが格納されるInnoDB には frm と IBD のみがあり、frm も格納されるテーブルの構造は同じであり、IBD ファイルにはインデックスとデータが格納される点が InnoDB や MyISAM とは異なります。 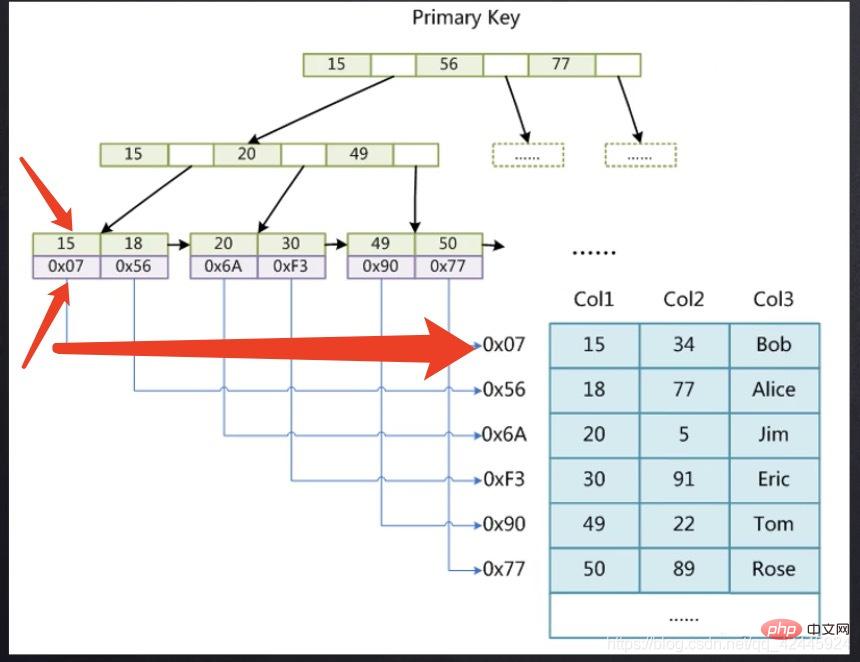 ここで、15 には主キーが格納されます。インデックス、0x07 には行レコードのディスク ファイル アドレス ポインタ 15 の場所が格納されます。たとえば、15 のデータを見つけたい場合は、まず主キー インデックス ツリーを通じて 15 に対応するポインタを見つけ、次にこのポインタを見つけてから、MyD ファイルに移動して特定のデータを見つけます。2 つの手順が必要です。このプロセスはテーブル リターン操作と呼ばれます。
ここで、15 には主キーが格納されます。インデックス、0x07 には行レコードのディスク ファイル アドレス ポインタ 15 の場所が格納されます。たとえば、15 のデータを見つけたい場合は、まず主キー インデックス ツリーを通じて 15 に対応するポインタを見つけ、次にこのポインタを見つけてから、MyD ファイルに移動して特定のデータを見つけます。2 つの手順が必要です。このプロセスはテーブル リターン操作と呼ばれます。 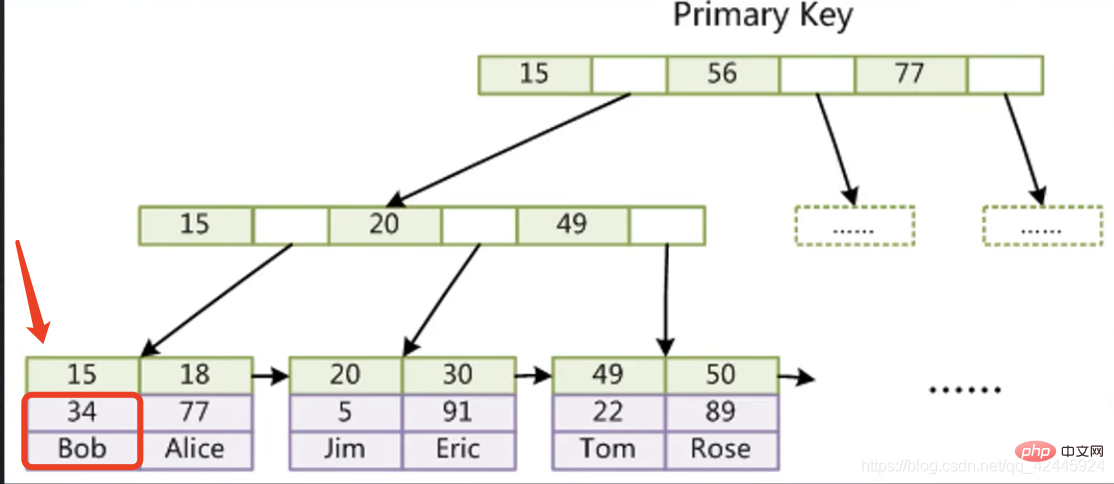 InnoDB ストレージ エンジン サブノードは、まず行 15 にインデックスを格納し、15 より下の列にはインデックスが配置されている行の他のすべてのフィールドを格納します。必要に応じて、2 回目のツリー検索を行わずに、15 のデータを直接見つけることができます。
InnoDB ストレージ エンジン サブノードは、まず行 15 にインデックスを格納し、15 より下の列にはインデックスが配置されている行の他のすべてのフィールドを格納します。必要に応じて、2 回目のツリー検索を行わずに、15 のデータを直接見つけることができます。 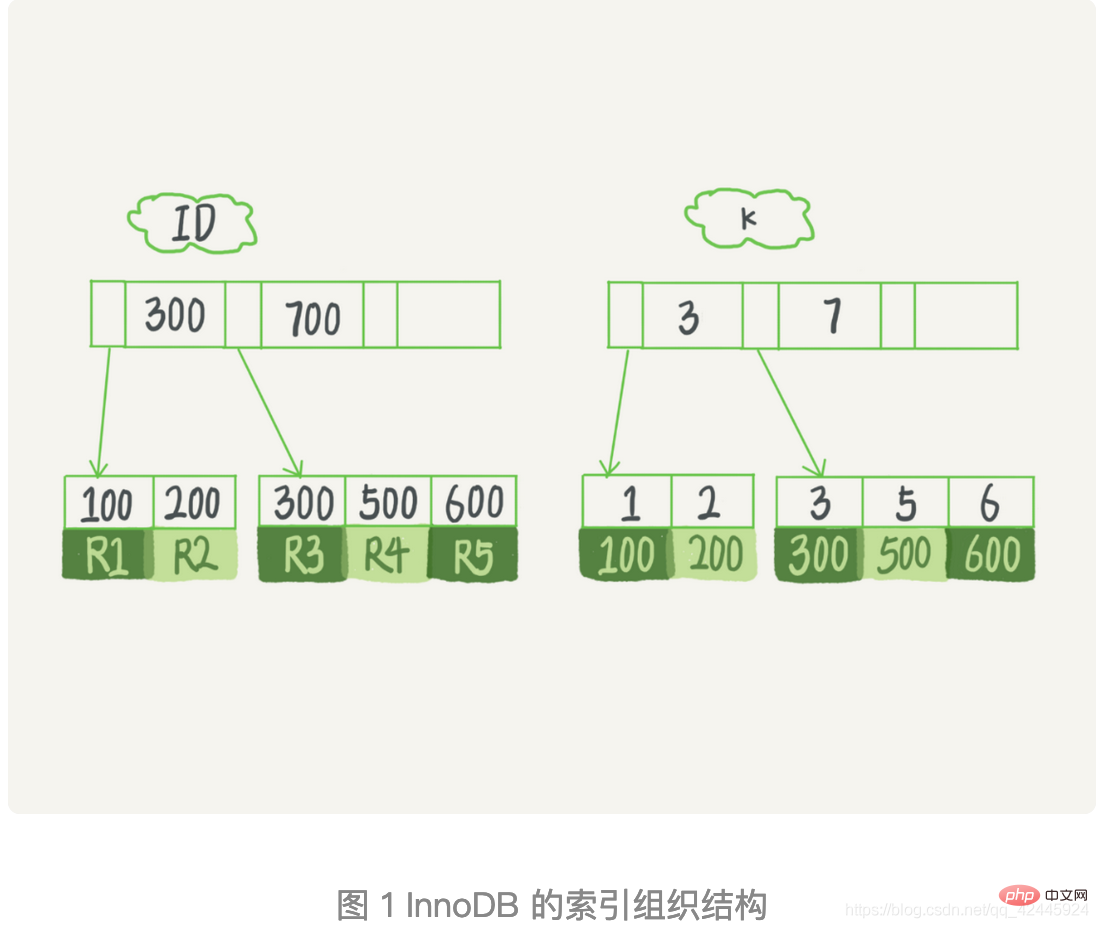






以上がMySQL インデックスの最下層と最適化について話しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。