



この記事では、MySQL のインデックスに関して遭遇する可能性のあるいくつかの問題を紹介します。インデックスはデータベースの大きな心臓とも言えます。データベースにインデックスがなければ、データベース自体の存在の意味がなくなってしまいます。大したことではありませんが、皆さんのお役に立てれば幸いです。

インデックスはデータベースの心臓部とも言えますが、データベースにインデックスがなければ、データベースの存在自体の意味はほとんどありません。通常のファイルと変わりません。したがって、データベース システムにとって、優れたインデックスは特に重要です。今日は、MySQL インデックスについて説明します。詳細と実際のビジネスの観点から、MySQL における B ツリー インデックスの利点と知識のポイントを見ていきます。インデックスを使用する場合は注意が必要です。
インデックスの合理的な使用
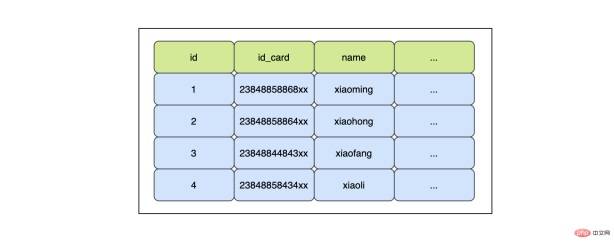
職場で、データ テーブル内のフィールドにインデックスを付ける必要があるかどうかを判断する最も直接的な方法は、次のとおりです。 ここでの状態です。マクロ的にはこのような考え方で問題ありませんが、長期的な視点で考えると、例えばこの分野だけの指標を作る必要があるのではないかなど、より詳細な考え方が必要な場合もあります。複数のフィールドの結合インデックスの方が良いでしょうか?ユーザーテーブルを例に挙げると、ユーザーテーブルのフィールドには、ユーザー名、ユーザーID番号、ユーザーの自宅住所などが含まれます。
「1. 通常のインデックスの欠点」
ユーザーの ID に基づいてユーザーの名前を検索する必要があります。このとき、最初に考えられるのは id_card にインデックスを作成することですが、ID 番号が一意である必要があるため、厳密には一意のインデックスになります。 :
SELECT name FROM user WHERE id_card=xxx
プロセスは次のようになります:
- 最初に id_card インデックス ツリーを検索し、id_card に対応する主キー ID を見つけます。
- 主キーに移動します。 ID を使用してキーのインデックスを検索し、対応する名前を見つけます。
効果の観点からは、結果は問題ありませんが、効率の観点からは、このクエリは少し高価であるようです2 つの B ツリーを取得するため、ツリーの高さが 3 であると仮定すると、2 つのツリーの高さは 6 になります。ルート ノードはメモリ内にあるため (ここでは 2 つのルート ノード)、最終的な IO 数は1 つのディスクのランダム IO に基づいて、ディスク上で 4 回実行されます。平均消費時間が 10 ミリ秒の場合、最終的には 40 ミリ秒かかります。この数値は平均的なものであり、高速ではありません。
「2. 主キーインデックスの罠」
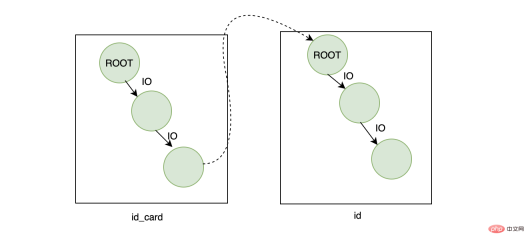
問題はテーブルリターンなので両方のツリーで検索することになります。の場合、中心的な質問は、それが 1 つのツリーのみで取得できるかどうかを確認することです。ビジネスの観点から見ると、ここでエントリ ポイントを見つけたかもしれません。ID カード番号は一意です。 なので、主キーはデフォルトの自動インクリメント ID を使用できませんか? 主キーを ID カード番号に設定します。 , そのため、テーブル全体に必要なインデックスは 1 つだけであり、名前を含むすべての必要なデータは ID 番号を通じて見つけることができます。単純に考えると合理的です。データを挿入するたびに、 ID は ID 番号ですが、よく考えてみると問題があるようです。
ここでB-treeの特徴についてお話します。B-treeのデータはリーフノードに格納され、データはページ単位で管理されます。1ページは16Kです。これは何を意味しますか?現在 1 行のデータがあるとしても、それは 16K データ ページを占有します。データ ページがいっぱいになった場合にのみ、新しいデータ ページに書き込まれます。新しいデータ ページと古いデータ ページは物理的に分離されています は必ずしも連続しているわけではなく、非常に重要なことが 1 つあります。データ ページは物理的には不連続ですが、データは論理的には 連続しています。
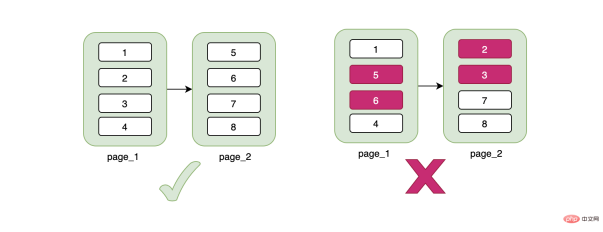
Continuous に注目してください。ID 番号が連続していません。これはどういう意味ですか?不連続なデータを挿入する場合、連続性を維持するためにデータを移動する必要があります。たとえば、ページ上の元のデータは 1->5 で、3 が挿入され、その後 5 を移動する必要があります。 3. の後は、あまりコストがかからないと思われるかもしれませんが、新しいデータ 3 によってページ A がいっぱいになった場合、その後ろのページ B にスペースがあるかどうかによって決まります。スペースがある場合、開始データはこれはページ A からはみ出したもので、対応するデータも移動する必要があります。この時点でページBに十分なスペースがない場合は、新しいページCを申請し、データの一部をこの新しいページCに移動する必要があり、ページAとページBの関係が切断されます。ページ C は、コード レベルから見ると、リンク リストを切り替えるポインタです。
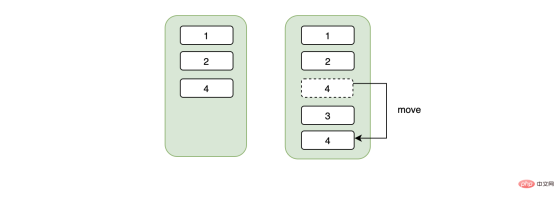
总结来说,不连续的身份证号当主键可能会造成页数据的移动、随机IO、频繁申请新页相关的开销。如果我们用的是自增的主键,那么对于id来说一定是顺序的,不会因为随机IO造成数据移动的问题,在插入方面开销一定是相对较小的。
其实不推荐用身份证号当主键的还有另外一个原因:身份证号作为数字来说太大了,得用bigint来存,正常来说一个学校的学生用int已经足够了,我们知道一页可以存放16K,当一个索引本身占用的空间越大时,会导致一页能存放的数据越少,所以在一定数据量的情况下,使用bigint要比int需要更多的页也就是更多的存储空间。
「3.联合索引的矛与盾」
由上面两条结论可以得出:
- 尽量不要去回表
- 身份证号不适合当主键索引
所以自然而然地想到了联合索引,创建一个【身份证号+姓名】的联合索引,注意联合索引的顺序,要符合最左原则。这样当我们同样执行以下sql时:
select name from user where id_card=xxx
不需要回表就可以得到我们需要的name字段,然而还是没有解决身份证号本身占用空间过大的问题,这是业务数据本身的问题,如果你要解决它的话,我们可以通过一些转换算法将原本大的数据转换成小的数据,比如crc32:
crc32.ChecksumIEEE([]byte("341124199408203232"))
可以将原本需要8个字节存储空间的身份证号用4个字节的crc码替代,因此我们的数据库需要再加个字段crc_id_card,联合索引也从【身份证号+姓名】变成了【crc32(身份证号)+姓名】,联合索引占的空间变小了。但是这种转换也是有代价的:
每次额外的crc,导致需要更多cpu资源
额外的字段,虽然让索引的空间变小了,但是本身也要占用空间
crc会存在冲突的概率,这需要我们查询出来数据后,再根据id_card过滤一下,过滤的成本根据重复数据的数量而定,重复越多,过滤越慢。
关于联合索引存储优化,这里有个小细节,假设现在有两个字段A和B,分别占用8个字节和20个字节,我们在联合索引已经是[A,B]的情况下,还要支持B的单独查询,因此自然而然我们在B上也建立个索引,那么两个索引占用的空间为 8+20+20=48,现在无论我们通过A还是通过B查询都可以用到索引,如果在业务允许的条件下,我们是否可以建立[B,A]和A索引,这样的话,不仅满足单独通过A或者B查询数据用到索引,还可以占用更小的空间:20+8+8=36。
「4.前缀索引的短小精悍」
有时候我们需要索引的字段是字符串类型的,并且这个字符串很长,我们希望这个字段加上索引,但是我们又不希望这个索引占用太多的空间,这时可以考虑建立个前缀索引,以这个字段的前一部分字符建立个索引,这样既可以享受索引,又可以节省空间,这里需要注意的是在前缀重复度较高的情况下,前缀索引和普通索引的速度应该是有差距的。
alter table xx add index(name(7));#name前7个字符建立索引 select xx from xx where name="JamesBond"
「5.唯一索引的快与慢」
在说唯一索引之前,我们先了解下普通索引的特点,我们知道对于B+树而言,叶子节点的数据是有序的。

假设现在我们要查询2这条数据,那么在通过索引树找到2的时候,存储引擎并没有停止搜索,因为可能存在多个2,这表现为存储引擎会在叶子节点上接着向后查找,在找到第二个2之后,就停止了吗?答案是否,因为存储引擎并不知道后面还有没有更多的2,所以得接着向后查找,直至找到第一个不是2的数据,也就是3,找到3之后,停止检索,这就是普通索引的检索过程。
唯一索引就不一样了,因为唯一性,不可能存在重复的数据,所以在检索到我们的目标数据之后直接返回,不会像普通索引那样还要向后多查找一次,从这个角度来看,唯一索引是要比普通索引快的,但是当普通索引的数据都在一个页内的话,其实也并不会快多少。在数据的插入方面,唯一索引可能就稍逊色,因为唯一性,每次插入的时候,都需要将判断要插入的数据是否已经存在,而普通索引不需要这个逻辑,并且很重要的一点是唯一索引会用不到change buffer(见下文)。
「6.不要盲目加索引」
在工作中,你可能会遇到这样的情况:这个字段我需不需要加索引?。对于这个问题,我们常用的判断手段就是:查询会不会用到这个字段,如果这个字段经常在查询的条件中,我们可能会考虑加个索引。但是如果只根据这个条件判断,你可能会加了一个错误的索引。我们来看个例子:假设有张用户表,大概有100w的数据,用户表中有个性别字段表示男女,男女差不多各占一半,现在我们要统计所有男生的信息,然后我们给性别字段加了索引,并且我们这样写下了sql:
select * from user where sex="男"
如果不出意外的话,InnoDB是不会选择性别这个索引的。如果走性别索引,那么一定是需要回表的,在数据量很大的情况下,回表会造成什么样的后果?我贴一张和上面一样的图想必大家都知道了:

主要就是大量的IO,一条数据需要4次,那么50w的数据呢?结果可想而知。因此针对这种情况,MySQL的优化器大概率走全表扫描,直接扫描主键索引,因为这样性能可能会更高。
「7.索引失效那些事」
某些情况下,因为我们自己使用的不当,导致mysql用不到索引,这一般很容易发生在类型转换方面,也许你会说,mysql不是已经支持隐式转换了吗?比如现在有个整型的user_id索引字段,我们因为查询的时候没注意,写成了:
select xx from user where user_id="1234"
注意这里是字符的1234,当发生这种情况下,MySQL确实足够聪明,会把字符的1234转成数字的1234,然后愉快的使用了user_id索引。 但是如果我们有个字符型的user_id索引字段,还是因为我们查询的时候没注意,写成了:
select xx from user where user_id=1234
这时候就有问题了,会用不到索引,也许你会问,这时MySQL为什么不会转换了,把数字的1234转成字符型的1234不就行了? 这里需要解释下转换的规则了,当出现字符串和数字比较的时候,要记住:MySQL会把字符串转换成数字。也许你又会问:为什么把字符型user_id字段转换成数字就用不到索引了? 这又要说到B+树索引的结构了,我们知道B+树的索引是按照索引的值来分叉和排序的,当我们把索引字段发生类型转换时会发生值的变化,比如原来是A值,如果执行整型转换可能会对应一个B值(int(A)=B),这时这颗索引树就不能用了,因为索引树是按照A来构造的,不是B,所以会用不到索引。
索引优化
「1.change buffer」
我们知道在更新一条数据的时候,要先判断这条数据的页是否在内存里,如果在的话,直接更新对应的内存页,如果不在的话,只能去磁盘把对应的数据页读到内存中来,然后再更新,这会有什么问题呢?
- 去磁盘的读这个动作稍显的有点慢
- 如果同时更新很多数据,那么即有可能发生很多离散的IO
为了解决这种情况下的速度问题,change buffer出现了,首先不要被buffer这个单词误导,change buffer除了会在公共的buffer pool里之外,也是会持久化到磁盘的。当有了change buffer之后,我们更新的过程中,如果发现对应的数据页不在内存里的话,也不去磁盘读取相应的数据页了,而是把要更新的数据放入到change buffer中,那change buffer的数据何时被同步到磁盘上去?如果此时发生读动作怎么办?首先后台有个线程会定期把change buffer的数据同步到磁盘上去的,如果线程还没来得及同步,但是又发生了读操作,那么也会触发把change buffer的数据merge到磁盘的事件。

需要注意的是并不是所有的索引都能用到changer buffer,像主键索引和唯一索引就用不到,因为唯一性,所以它们在更新的时候要判断数据存不存在,如果数据页不在内存中,就必须去磁盘上把对应的数据页读到内存里,而普通索引就没关系了,不需要校验唯一性。change buffer越大,理论收益就越大,这是因为首先离散的读IO变少了,其次当一个数据页上发生多次变更,只需merge一次到磁盘上。当然并不是所有的场景都适合changer buffer,如果你的业务是更新之后,需要立马去读,changer buffer会适得其反,因为需要不停地触发merge动作,导致随机IO的次数不会变少,反而增加了维护changer buffer的开销。
「2.索引下推」
前面我们说了联合索引,联合索引要满足最左原则,即在联合索引是[A,B]的情况下,我们可以通过以下的sql用到索引:
select * from table where A="xx" select * from table where A="xx" AND B="xx"
其实联合索引也可以使用最左前缀的原则,即:
select * from table where A like "赵%" AND B="上海市"
但是这里需要注意的是,因为使用了A的一部分,在MySQL5.6之前,上面的sql在检索出所有A是“赵”开头的数据之后,就立马回表(使用的select *),然后再对比B是不是“上海市”这个判断,这里是不是有点懵?为什么B这个判断不直接在联合索引上判断,这样的话回表的次数不就少了吗?造成这个问题的原因还是因为使用了最左前缀的问题,导致索引虽然能使用部分A,但是完全用不到B,看起来是有点“傻”,于是在MySQL5.6之后,就出现了索引下推这个优化(Index Condition Pushdown),有了这个功能以后,虽然使用的是最左前缀,但是也可以在联合索引上搜索出符合A%的同时也过滤非B的数据,大大减少了回表的次数。
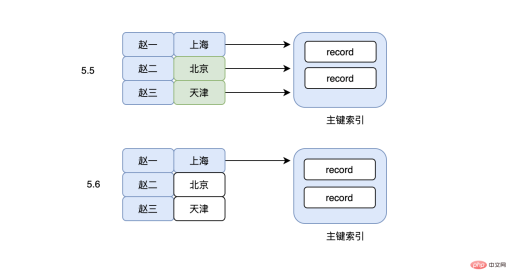
「3.刷新邻接页」
在说刷新邻接页之前,我们先说下脏页,我们知道在更新一条数据的时候,得先判断这条数据所在的页是否在内存中,如果不在的话,需要把这个数据页先读到内存中,然后再更新内存中的数据,这时会发现内存中的页有最新的数据,但是磁盘上的页却依然是老数据,那么此时这条数据所在的内存中的页就是脏页,需要刷到磁盘上来保持一致。所以问题来了,何时刷?每次刷多少脏页才合适?如果每次变更就刷,那么性能会很差,如果很久才刷,脏页就会堆积很多,造成内存池中可用的页变少,进而影响正常的功能。所以刷的速度不能太快但要及时,MySQL有个清理线程会定期执行,保证了不会太快,当脏页太多或者redo log已经快满了,也会立刻触发刷盘,保证了及时。

在脏页刷盘的过程中,InnoDB这里有个优化:如果要刷的脏页的邻居页也脏了,那么就顺带一起刷,这样的好处就是可以减少随机IO,在机械磁盘的情况下,优化应该挺大,但是这里可能会有坑,如果当前脏页的邻居脏页在被一起刷入后,邻居页立马因为数据的变更又变脏了,那此时是不是有种多此一举的感觉,并且反而浪费了时间和开销。更糟糕的是如果邻居页的邻居也是脏页...,那么这个连锁反应可能会出现短暂的性能问题。
「4.MRR」
在实际业务中,我们可能会被告知尽量使用覆盖索引,不要回表,因为回表需要更多IO,耗时更长,但是有时候我们又不得不回表,回表不仅仅会造成过多的IO,更严重的是过多的离散IO。
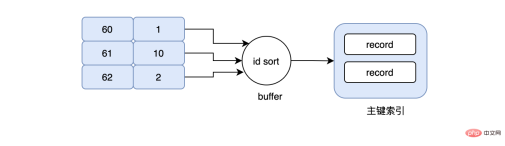
select * from user where grade between 60 and 70
现在要查询成绩在60-70之间的用户信息,于是我们的sql写成上面的那样,当然我们的grade字段是有索引的,按照常理来说,会先在grade索引上找到grade=60这条数据,然后再根据grade=60这条数据对应的id去主键索引上找,最后再次回到grade索引上,不停的重复同样的动作..., 假设现在grade=60对应的id=1,数据是在page_no_1上,grade=61对应的id=10,数据是在page_no_2上,grade=62对应的id=2,数据是在page_no_1上,所以真实的情况就是先在page_no_1上找数据,然后切到page_no_2,最后又切回page_no_1上,但其实id=1和id=2完全可以合并,读一次page_no_1即可,不仅节省了IO,同时避免了随机IO,这就是MRR。当使用MRR之后,辅助索引不会立即去回表,而是将得到的主键id,放在一个buffer中,然后再对其排序,排序后再去顺序读主键索引,大大减少了离散的IO。
推荐学习:mysql视频教程
以上がMySQL インデックスの落とし穴を理解する必要があるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 MySQLはSQLiteとどのように違いますか?Apr 24, 2025 am 12:12 AM
MySQLはSQLiteとどのように違いますか?Apr 24, 2025 am 12:12 AMMySQLとSQLiteの主な違いは、設計コンセプトと使用法のシナリオです。1。MySQLは、大規模なアプリケーションとエンタープライズレベルのソリューションに適しており、高性能と高い並行性をサポートしています。 2。SQLiteは、モバイルアプリケーションとデスクトップソフトウェアに適しており、軽量で埋め込みやすいです。
 MySQLのインデックスとは何ですか?また、パフォーマンスをどのように改善しますか?Apr 24, 2025 am 12:09 AM
MySQLのインデックスとは何ですか?また、パフォーマンスをどのように改善しますか?Apr 24, 2025 am 12:09 AMMySQLのインデックスは、データの取得をスピードアップするために使用されるデータベーステーブル内の1つ以上の列の順序付けられた構造です。 1)インデックスは、スキャンされたデータの量を減らすことにより、クエリ速度を改善します。 2)B-Tree Indexは、バランスの取れたツリー構造を使用します。これは、範囲クエリとソートに適しています。 3)CreateIndexステートメントを使用して、createIndexidx_customer_idonorders(customer_id)などのインデックスを作成します。 4)Composite Indexesは、createIndexIDX_CUSTOMER_ORDERONORDERS(Customer_Id、Order_date)などのマルチコラムクエリを最適化できます。 5)説明を使用してクエリ計画を分析し、回避します
 データの一貫性を確保するために、MySQLでトランザクションを使用する方法を説明します。Apr 24, 2025 am 12:09 AM
データの一貫性を確保するために、MySQLでトランザクションを使用する方法を説明します。Apr 24, 2025 am 12:09 AMMySQLでトランザクションを使用すると、データの一貫性が保証されます。 1)StartTransactionを介してトランザクションを開始し、SQL操作を実行して、コミットまたはロールバックで送信します。 2)SavePointを使用してSave Pointを設定して、部分的なロールバックを許可します。 3)パフォーマンスの最適化の提案には、トランザクション時間の短縮、大規模なクエリの回避、分離レベルの使用が合理的に含まれます。
 どのシナリオでMySQLよりもPostgreSQLを選択できますか?Apr 24, 2025 am 12:07 AM
どのシナリオでMySQLよりもPostgreSQLを選択できますか?Apr 24, 2025 am 12:07 AMMySQLの代わりにPostgreSQLが選択されるシナリオには、1)複雑なクエリと高度なSQL関数、2)厳格なデータの整合性と酸コンプライアンス、3)高度な空間関数が必要、4)大規模なデータセットを処理するときに高いパフォーマンスが必要です。 PostgreSQLは、これらの側面でうまく機能し、複雑なデータ処理と高いデータの整合性を必要とするプロジェクトに適しています。
 MySQLデータベースをどのように保護できますか?Apr 24, 2025 am 12:04 AM
MySQLデータベースをどのように保護できますか?Apr 24, 2025 am 12:04 AMMySQLデータベースのセキュリティは、以下の測定を通じて達成できます。1。ユーザー許可管理:CreateUSERおよびGrantコマンドを通じてアクセス権を厳密に制御します。 2。暗号化された送信:SSL/TLSを構成して、データ送信セキュリティを確保します。 3.データベースのバックアップとリカバリ:MySQLDUMPまたはMySQLPumpを使用して、定期的にデータをバックアップします。 4.高度なセキュリティポリシー:ファイアウォールを使用してアクセスを制限し、監査ロギング操作を有効にします。 5。パフォーマンスの最適化とベストプラクティス:インデックス作成とクエリの最適化と定期的なメンテナンスを通じて、安全性とパフォーマンスの両方を考慮に入れます。
 MySQLのパフォーマンスを監視するために使用できるツールは何ですか?Apr 23, 2025 am 12:21 AM
MySQLのパフォーマンスを監視するために使用できるツールは何ですか?Apr 23, 2025 am 12:21 AMMySQLのパフォーマンスを効果的に監視する方法は? MySqladmin、ShowGlobalStatus、PerconAmonitoring and Management(PMM)、MySQL EnterpriseMonitorなどのツールを使用します。 1. mysqladminを使用して、接続の数を表示します。 2。showglobalstatusを使用して、クエリ番号を表示します。 3.PMMは、詳細なパフォーマンスデータとグラフィカルインターフェイスを提供します。 4.mysqlenterprisemonitorは、豊富な監視機能とアラームメカニズムを提供します。
 MySQLはSQL Serverとどのように違いますか?Apr 23, 2025 am 12:20 AM
MySQLはSQL Serverとどのように違いますか?Apr 23, 2025 am 12:20 AMMySQLとSQLServerの違いは次のとおりです。1)MySQLはオープンソースであり、Webおよび埋め込みシステムに適しています。2)SQLServerはMicrosoftの商用製品であり、エンタープライズレベルのアプリケーションに適しています。ストレージエンジン、パフォーマンスの最適化、アプリケーションシナリオの2つには大きな違いがあります。選択するときは、プロジェクトのサイズと将来のスケーラビリティを考慮する必要があります。
 どのシナリオでMySQLよりもSQL Serverを選択できますか?Apr 23, 2025 am 12:20 AM
どのシナリオでMySQLよりもSQL Serverを選択できますか?Apr 23, 2025 am 12:20 AM高可用性、高度なセキュリティ、優れた統合を必要とするエンタープライズレベルのアプリケーションシナリオでは、MySQLの代わりにSQLServerを選択する必要があります。 1)SQLServerは、高可用性や高度なセキュリティなどのエンタープライズレベルの機能を提供します。 2)VisualStudioやPowerbiなどのMicrosoftエコシステムと密接に統合されています。 3)SQLSERVERは、パフォーマンスの最適化に優れた機能を果たし、メモリが最適化されたテーブルと列ストレージインデックスをサポートします。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

