
ホームページ >データベース >mysql チュートリアル >MySQL の原則の深い理解: バッファ プール (詳細な図とテキストの説明)
MySQL の原則の深い理解: バッファ プール (詳細な図とテキストの説明)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-01-18 16:52:203712ブラウズ
この記事では、データ ページ、キャッシュ ページのフリー リンク リスト、フラッシュ リンク リスト、LRU リンク リスト チャンクなどを含む、MySQL のバッファ プールに関する関連知識を提供します。皆様のお役に立てれば幸いです。

キャッシュの重要性
これまでの説明を通じて、ストレージ エンジンとして InnoDB を使用するテーブルについて、は、ユーザー データ (クラスタード インデックスやセカンダリ インデックスを含む) またはさまざまなシステム データを保存するために使用されるインデックスであり、これらはすべて ページ の形式で テーブル スペース に保存されます。 - テーブル スペース と呼ばれる InnoDB は、ファイル システム上の 1 つまたは複数の実際のファイルを抽象化したものにすぎません。つまり、データは結局ディスクに保存されたままです。しかし、ディスクの速度が亀のように遅いことも誰もが知っています。「風のように速く、稲妻のように速い」CPU にどうして価値があるのでしょうか?したがって、 InnoDB ストレージ エンジンがクライアントのリクエストを処理するとき、特定のページのデータにアクセスする必要がある場合、ページ全体のすべてのデータがメモリにロードされます。アクセスする必要があるのは 1 つだけです。ページのレコードの場合、最初にページ全体のデータをメモリにロードする必要があります。ページ全体をメモリにロードした後、読み取りおよび書き込みアクセスを実行できます。読み取りおよび書き込みアクセスが完了した後、ページに対応するメモリ空間を急いで解放する必要はありませんが、それを キャッシュ します。したがって、将来再びページへのアクセス要求があった場合、ディスク IO のオーバーヘッドを節約できます。
InnoDB のバッファ プール
バッファ プールとは
ページをキャッシュするために InnoDB を設計したおじさんディスク内の MySQLサーバーが起動すると、オペレーティング システムから連続メモリの一部が申請され、このメモリに バッファ プール という名前が付けられました (中国語名はバッファプール)。それで、それはどのくらいの大きさですか?これは実際にはマシンの構成に依存します。裕福で 512G のメモリがある場合は、数百 G を バッファ プール として割り当てることができます。こんなに豊富なので、小さく設定しても大丈夫です~ デフォルトでは、バッファプールのサイズはわずか128Mです。もちろん、この 128M が大きすぎたり小さすぎたりしたくない場合は、サーバーの起動時に innodb_buffer_pool_size パラメータの値を構成できます。これは、 のサイズを表します。 Buffer Pool. 次のように:
[server] innodb_buffer_pool_size = 268435456
このうち、268435456 の単位はバイト、つまり Buffer Pool のサイズを次のように指定しました。 256M。 Buffer Pool は小さすぎることはできません。最小値は 5M です (この値より小さい場合は、自動的に 5M## に設定されます) #)。
バッファ プールの内部構成
バッファ プールのデフォルトのキャッシュ ページ サイズは、ディスク上のデフォルトのページ サイズと同じです。 16KBです。 バッファ プールでこれらのキャッシュ ページをより適切に管理するために、InnoDB を設計したおじさんは、各キャッシュ ページに対していわゆる 制御情報を作成しました。テーブルスペース番号、ページ番号、ページが属するバッファプール内のキャッシュページアドレス、リンクリストノード情報、一部のロック情報およびLSN情報(ロックと)が含まれます。 LSNこれについては後で詳しく説明します。今は無視していただいても構いません)、もちろん、他にもいくつかの制御情報があります。ここではすべてについては説明しません。重要なものだけを選択してください~
コントロールブロックと呼びます コントロールブロックとキャッシュページは同様に、それらはすべてバッファ プールに保存され、制御ブロックはバッファ プールの前に保存され、キャッシュ ページはバッファ プールの後ろに保存されるため、バッファ プール全体が 対応するメモリ空間は次のようになります:
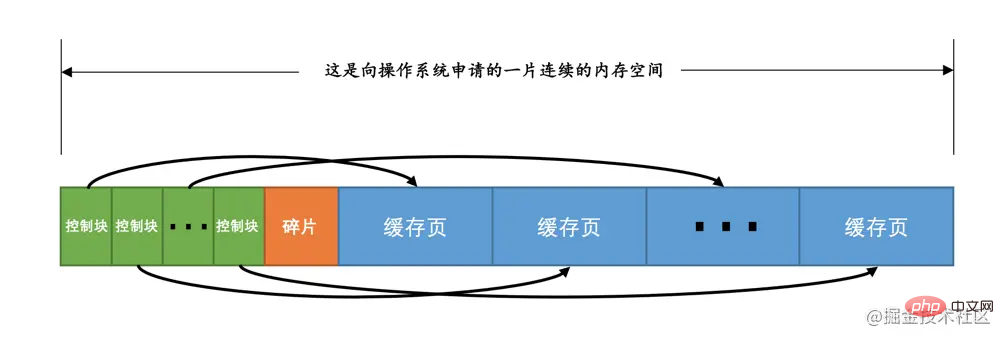
フラグメント は何ですか?考えてみると、各制御ブロックは 1 つのキャッシュ ページに対応しており、十分な制御ブロックとキャッシュ ページを割り当てても、残りの領域は制御ブロックとキャッシュ ページのペアに十分ではないため、当然使用されません。使用されていないわずかなメモリ空間は fragment と呼ばれます。もちろん、Buffer Pool のサイズを適切に設定すると、 フラグメント~ が生成されなくなる可能性があります。
ヒント: 各制御ブロックはキャッシュ ページ サイズの約 5% を占めます。MySQL 5.7.21 のバージョンでは、各制御ブロックのサイズは 808 バイトです。設定した innodb_buffer_pool_size には、制御ブロックのこの部分が占有するメモリ領域は含まれていません。つまり、InnoDB がバッファ プール用にオペレーティング システムから連続メモリ領域を申請する場合、この連続メモリ領域は通常、 innodb_buffer_pool_size の値。%about。
無料リンク リストの管理
最初に MySQL サーバーを起動するときは、バッファ プールを完了する必要があります の初期化プロセスは、最初に バッファ プール のメモリ空間をオペレーティング システムに適用し、次にそれを制御ブロックとキャッシュ ページのいくつかのペアに分割します。ただし、現時点では実際のディスク ページは バッファ プール にキャッシュされていません (まだ使用されていないため)。後でプログラムが実行されると、ディスク上のページは引き続き にキャッシュされます。バッファプール内。そこで問題は、ページをディスクから バッファ プールに読み取るときに、そのページをキャッシュ ページのどこに配置する必要があるかということです。あるいは、バッファ プール内のどのキャッシュ ページが空いていて、どのキャッシュ ページが使用されているかを区別するにはどうすればよいでしょうか?バッファ プール内のどのキャッシュ ページがどこかで利用可能であるかを記録しておいたほうがよいでしょう。このとき、キャッシュ ページに対応する control ブロック が役に立ちます。コントロールに対応するすべての空きキャッシュ ページを置くことができます。ブロックはリンク リストのノードとして配置されます。このリンク リストは、フリー リンク リスト (またはフリー リンク リスト) とも呼ばれます。初期化されたばかりの バッファ プール 内のすべてのキャッシュ ページは空きであるため、 と仮定すると、各キャッシュ ページに対応する制御ブロックが 空きリンク リスト に追加されます。バッファ プール に収容できるキャッシュ ページの数は n であるため、フリー リンク リスト を追加する効果は次のようになります。
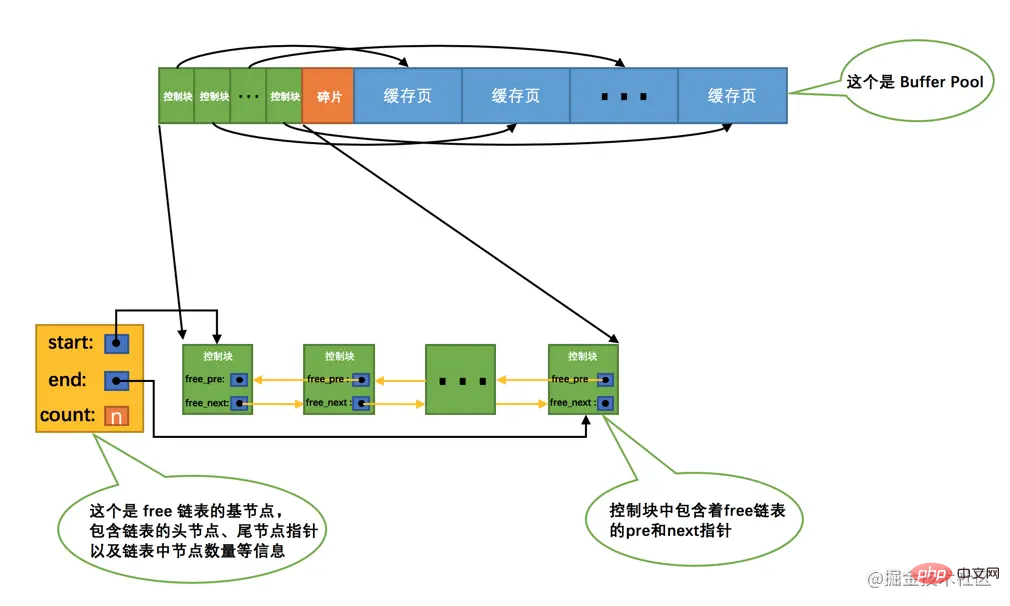
図からわかるように、この 無料リンク リスト を管理するために、このリンク リストの ベース ノード を特別に定義しました。リンクリストの先頭ノードのアドレス、末尾ノードのアドレス、現在のリンクリストのノード数、その他の情報。ここで注意する必要があるのは、リンク リストのベース ノードが占有するメモリ空間は、バッファ プールに適用される大きな連続メモリ空間には含まれず、バッファ プール
ヒント: リンク リストのベース ノードが占有するメモリ空間は大きくなく、MySQL5.7.21 のバージョンでは、各ベース ノードは 40 バイトしか占有しません。後でさまざまなリンク リストを紹介しますが、そのベース ノードとフリー リンク リストのベース ノードのメモリ割り当て方法は同じです。これらはすべて個別に 40 バイトのメモリ空間に適用されます。バッファ プール: 大きな連続メモリ空間内にあるプール。
この 無料リンク リスト を使用すると、処理が簡単になります。ディスクから バッファ プール にページをロードする必要があるときはいつでも、単に Take 無料リンク・リストから空きキャッシュ・ページを選択し、そのキャッシュ・ページに対応する情報(つまり、ページが配置されている表スペース、ページ番号、などの情報)、キャッシュ ページに対応する free linked list ノードをリンク リストから削除し、キャッシュ ページが使用されていることを示します~
のハッシュ処理キャッシュ ページ
特定のページ内のデータにアクセスする必要がある場合、そのページはディスクからバッファ プールにロードされると前に述べました。はすでに バッファプール にあり、直接使用できます。次に、ページが バッファ プール にあるかどうかをどのようにして知ることができるのかという疑問が生じます。 バッファプールの各キャッシュページを順番に走査する必要がありますか? バッファ プール内の非常に多くのキャッシュ ページを走査するのは大変ではないでしょうか?
表スペース番号ページ番号に基づいてページを見つけます。これは、表スペース番号ページ番号が キー#であることと同等です。 ##、キャッシュ ページ は対応する value です。key を通じて value をすばやく見つけるにはどうすればよいですか?はは、それはハッシュ テーブルに違いありません ~
これで、テーブルスペース番号ページ番号
をキー、キャッシュページとして使用できます。 as valueハッシュ テーブルを作成します。特定のページのデータにアクセスする必要がある場合、まず、テーブル スペース番号ページ番号#に従って、ハッシュ テーブルに対応するキャッシュ ページがあるかどうかを確認します。 ##。そうであれば、キャッシュ ページを直接使用します。そうでない場合は、無料リンク リストから空きキャッシュ ページを選択し、対応するページをディスクからキャッシュ ページの場所にロードします。 。
フラッシュ リンク リストの管理
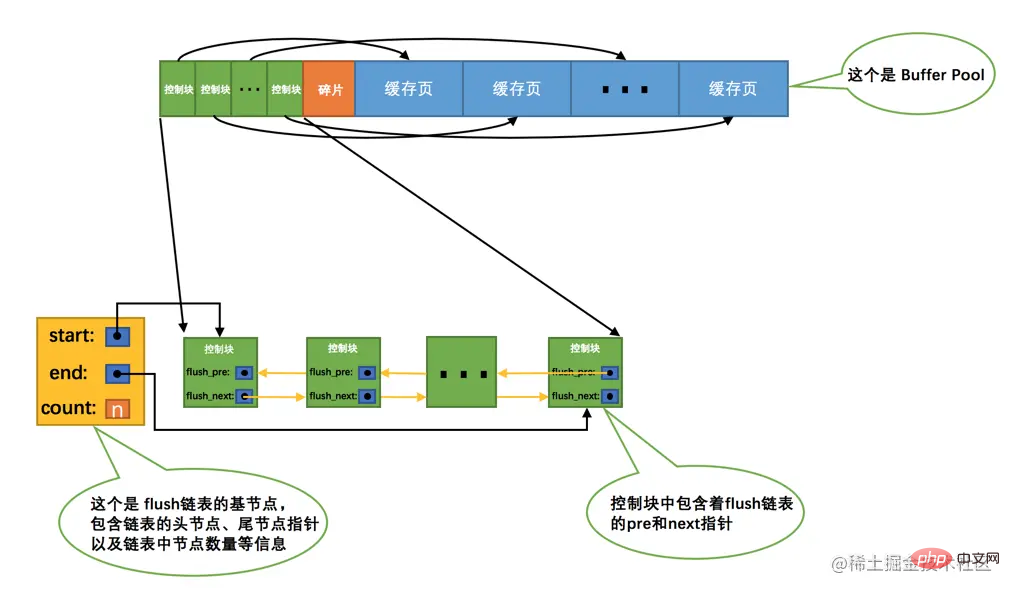
バッファ プール内のキャッシュ ページのデータを変更すると、ディスク上のページと不整合が発生します。このようなキャッシュページは、ダーティページ(英語名:dirty page)とも呼ばれます。もちろん、最も簡単な方法は、変更が発生するたびにすぐにディスク上の対応するページに同期させることですが、頻繁にデータをディスクに書き込むと、プログラムのパフォーマンスに重大な影響を及ぼします (結局のところ、ディスクは非常に遅いのです)。カメ)。したがって、キャッシュ ページを変更するたびに、その変更をすぐにディスクに同期するのではなく、将来のある時点で同期します。この同期時間については、後ほど説明しますので、行わないでください。今は心配する必要はありません。は~
しかし、すぐにディスクに同期されない場合、バッファ プール内のどのページが ダーティ ページであるかをどうやって知ることができるのでしょうか。一度も同期されていないページはどれですか? 変更されていませんか?すべてのキャッシュ ページをディスクに同期することはできません。バッファ プール が 300G などの大きなサイズに設定されている場合、非常に多くのデータを同期すると遅くなりませんか?一度?死ね!したがって、ダーティ ページを保存するために別のリンク リストを作成する必要があります。リンク リスト ノードに対応するキャッシュ ページを更新する必要があるため、変更されたキャッシュ ページに対応する制御ブロックはノードとしてリンク リストに追加されます。ディスクであるため、フラッシュ リンク リストとも呼ばれます。リンク リストの構造は フリー リンク リスト と似ています。ある時点での バッファ プール 内のダーティ ページの数が n であると仮定します。 、対応する フラッシュ リンク リスト次のようになります:
LRU リンク リスト管理
キャッシュ不足のジレンマ
バッファプール対応 結局、メモリサイズには限界があり、キャッシュする必要のあるページが占有するメモリサイズがバッファプールサイズを超える場合、つまり、 無料リンク リストには余分な無料キャッシュ ページがありません。恥ずかしくないですか?このようなことが起こったらどうすればよいですか?もちろん、古いキャッシュ ページの一部は バッファ プール から削除され、新しいページが追加されます~ そこで問題は、どのキャッシュ ページを削除する必要があるかということです。
この質問に答えるには、バッファ プールを設定するという当初の意図に戻る必要があります。ただ、#IO との対話を削減したいだけです。ページがアクセスされると、そのページは バッファ プール にキャッシュされます。合計 n 回アクセスしたと仮定すると、アクセスしたページがキャッシュ内にあった回数を n で割ったものが、いわゆる キャッシュ ヒット率になります。 , 私たちの期待は、キャッシュ ヒット率 が高ければ高いほど良いことです~ この観点から、WeChat チャット リストを思い出してください。一番上にあるものは、最近頻繁に使用されているものです。 , そして最後にあるのは、当然最近頻繁に使用したものです。めったに使用しない連絡先の場合、リストに収容できる連絡先の数が限られている場合、最近頻繁に使用したものと、ほとんど使用しないものを保持します。最近使った?ナンセンスです、もちろん、最近頻繁に使用されているものは残しておきます~
バッファ プールのキャッシュ ページには実際には同じものがあります原則、いつ バッファプールに空きキャッシュページがなくなった場合、最近ほとんど使用されていないいくつかのキャッシュページを削除する必要があります。しかし、どのキャッシュされたページが最近頻繁に使用され、どのページがほとんど使用されていないのかをどのようにして知ることができるでしょうか?はは、魔法のリンク リストがまた便利です。別のリンク リストを作成できます。このリンク リストは、最も最近使用されていないものの原則に従ってキャッシュ ページを削除するためのものであるため、# というようにこのリンク リストを呼び出すことができます##LRU リンク リスト (LRU の完全な英語名: Least Recently Used)。ページにアクセスする必要がある場合、LRU リンク リストを次のように処理できます:
- バッファ プールにない場合
- 、ページがディスクから
バッファ プール
ページがのキャッシュ ページにロードされると、キャッシュ ページに対応するコントロール ブロックがリンク リストの先頭に挿入されます。ノード。バッファ プール - にキャッシュされている場合は、そのページに対応する
コントロール ブロック
つまり、特定のキャッシュ ページを使用する限り、そのキャッシュ ページををLRU に直接移動します。リンクされたリストの先頭。LRU リンク リスト
LRU リンク リスト 末尾は最も最近使用されていないキャッシュ ページです~ したがって、バッファ プール の空きキャッシュ ページが使い果たされたら、LRU リンク リスト#の末尾に移動します## 削除するキャッシュ ページを見つけます。ラ、とても簡単です、チクチク...エリア分割用の LRU リンク リスト上記の簡単な内容はとても嬉しいです
にはそれほど時間はかかりませんでした。次の 2 つの厄介な状況があるため、問題を発見するのに時間がかかりました。
-
状況 1:
InnoDBは、一見思いやりのあるサービス -read Above(英語名:read Above) を提供します。いわゆるpre-readingは、InnoDBが現在のリクエストの実行後に特定のページが読み取られる可能性があると判断し、それらのページを事前にバッファ プールにロードすることを意味します。 。トリガー方法に応じて、先読みは次の 2 つのタイプに分類できます。-
リニア先読み
デザイン
InnoDBの叔父はシステム変数innodb_read_ahead_thresholdを提供しています。特定の領域 (extent) で連続してアクセスされるページがこのシステム変数の値を超えると、非同期次の領域にあるすべてのページをバッファ プールに読み取るように要求します。非同期読み取りは、これらの事前に読み取られたページをディスクから読み込むことには影響しないことに注意してください。現在のワーカー スレッドの通常の実行に移行します。このinnodb_read_ahead_thresholdシステム変数の値は、デフォルトで56に設定されています。このシステム変数の値は、サーバーの起動時またはサーバーの操作中に起動パラメーターを通じて直接調整できますが、これはグローバル変数です。変数。SET GLOBALコマンドを使用して変更してください。ヒント: InnoDB は非同期読み取りをどのように実装しますか? Windows または Linux プラットフォームでは、オペレーティング システムのカーネルによって提供される AIO インターフェイスを直接呼び出すことができる場合があります。他の Unix 系オペレーティング システムでは、AIO インターフェイスをシミュレートする方法が非同期読み取りを実現するために使用されます。他のスレッドに読み込ませるには 読み込む必要があるページを事前に取得します。上の段落が理解できない場合は、理解する必要はありません。このトピックとは何の関係もありません。非同期読み取りが現在の作業スレッドの通常の実行に影響を与えないことだけを知っておく必要があります。実際、このプロセスには、オペレーティング システムが IO とマルチスレッドの問題をどのように処理するかが関係しています。オペレーティング システムに関する本を探して読んでください。 OSの書き方はわかりにくいですか?関係ないので待ってください~
-
ランダム先読み
特定の領域の 13 個の連続したバッファがキャッシュされている場合
バッファ プールページは、これらのページが順次読み取られるかどうかに関係なく、この領域内の他のすべてのページをバッファ プールに読み取るための非同期リクエストをトリガーします。InnoDBを設計した叔父は、innodb_random_read_aheadシステム変数も提供しました。そのデフォルト値はOFFであり、InnoDBはランダムな値を使用しないことを意味します。先読み機能はデフォルトで有効になっています。この機能を有効にしたい場合は、起動パラメータを変更するか、SET GLOBALを直接使用して、この変数の値をONに設定できます。指示。
先読みは本来良いものですが、先読みバッファプールのページがうまく使えれば、非常に便利で、ステートメントの実行効率が大幅に向上します。しかし、使われなかったらどうなるでしょうか?これらの先読みページはLRUリンク リストの先頭に配置されますが、現時点でバッファ プールの容量がそれほど大きくなく、多くの先読みページが配置されている場合は、これにより、LRU リンク リストの末尾にある一部のキャッシュ ページがすぐに削除されます。これは、いわゆる悪いコインが良いコインを駆逐するです。キャッシュヒット率が大幅に低下します。 -
-
状況 2: 一部の友人は、テーブル全体をスキャンする必要があるクエリ ステートメント (適切なインデックスを作成しないクエリ、または WHERE 句がまったくないクエリなど) を作成する可能性があります。
テーブル全体をスキャンするとはどういう意味ですか?これは、テーブルが配置されているすべてのページがアクセスされることを意味します。このテーブルに非常に多くのレコードがあると仮定すると、テーブルは特に多数の
ページを占有することになります。これらのページにアクセスする必要がある場合、それらはすべてバッファ プール## にロードされます。 #. これは、バッファ プール内のすべてのページが一度置換されており、他のクエリ ステートメントは実行時にディスクからバッファ プールにロードする必要があることを意味します。この種のフル テーブル スキャン ステートメントの実行頻度は高くありません。実行されるたびに、Buffer Pool内のキャッシュ ページを置き換える必要があり、Buffer 内の他のクエリの使用に重大な影響を与えます。プールを使用すると、キャッシュ ヒット率が大幅に低下します。
バッファ プールを削減する可能性がある上記の 2 つの状況を要約します。
- Load into
Buffer Pages inプール
は使用できない可能性があります。 - 使用頻度の低い多数のページが同時に
バッファ プール
にロードされた場合、使用頻度が非常に高いページは ## から削除される可能性があります。 # バッファプールから削除されました。 これら 2 つの状況が存在するため、
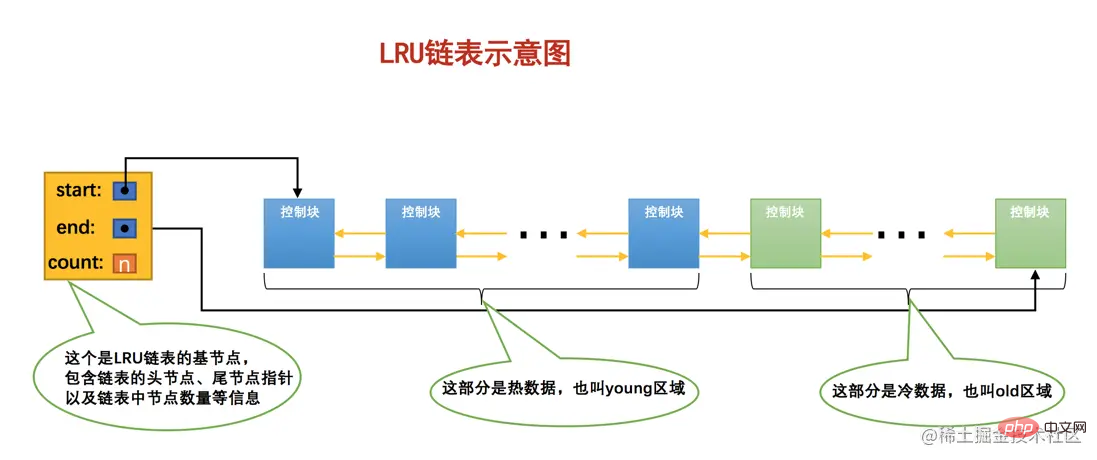
を設計したおじさんは、この LRU リンク リスト をそれぞれ一定の割合に従って 2 つの部分に分割しました。はい:
- キャッシュ ページの一部には非常に頻繁に使用されるキャッシュ ページが保存されるため、リンク リストのこの部分は
- ホット データ
または
とも呼ばれます。若いエリア。 他の部分には、あまり使用されないキャッシュ ページが格納されるため、リンク リストのこの部分は、 - コールド データ
、または
オールド エリアとも呼ばれます。。 誰もが理解しやすいように、その精神を理解できるように概略図を簡略化しました。
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server] innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成young和old区域的LRU链表之后,设计InnoDB的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
-
针对预读的页面可能不进行后续访问情况的优化
设计
InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。 -
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到
Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。有同学会想:可不可以在第一次访问该页面时不将其从old区域移动到young区域的头部,后续访问时再将其移动到young区域的头部。回答是:行不通!因为设计InnoDB的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在
old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec)
这个innodb_old_blocks_time的默认值是1000,它的单位是毫秒,也就意味着对于从磁盘上被加载到LRU链表的old区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把innodb_old_blocks_time的值设置为0,那么每次我们访问一个页面时就会把该页面放到young区域的头部。
要約すると、LRU リンク リストが young 領域と old 領域の 2 つの部分に分割され、innodb_old_blocks_time が追加されているためです。 このシステム変数は、未使用の先読みページとフルテーブルスキャンページが old 領域にのみ配置されるため、先読みメカニズムとフルテーブルスキャンによって引き起こされるキャッシュヒット率の低下の問題を抑制します。 young 領域にあるキャッシュされたページには影響を与えません。
LRU リンク リストをさらに最適化します
LRU リンク リストこれですべてですか?いや、早いですね~ young領域のキャッシュページは、アクセスするたびにLRUリンクリストの先頭に移動しなければなりません。これは高すぎませんか? まあ、結局のところ、young 領域にキャッシュされたページはホット データ、つまり頻繁にアクセスされる可能性があるため、頻繁にノードを 領域に移動するのは悪くないでしょうか。 LRU リンク リスト はこんな感じですか? ああ?はい、この問題を解決するために、実際にいくつかの最適化戦略を提案できます。たとえば、young 領域の 1/4 の後ろにあるアクセスされたキャッシュ ページのみが、次の場所に移動されます。 LRU リンク リスト ヘッダーを使用すると、LRU リンク リスト を調整する頻度が減り、パフォーマンスが向上します (つまり、キャッシュ ページに対応するノードが の場合) young 領域 1/4 では、キャッシュ ページが再度アクセスされたときに、LRU リンク リストの先頭に移動されません)。
ヒント: 以前にランダム先読みを紹介したとき、バッファ プールの特定の領域に連続 13 ページがある場合、ランダム先読みがトリガーされると言いましたが、実際にはそうではありません。 (残念ながら、これは MySQL ドキュメントに記載されている内容です [手を見せてください])。実際、これら 13 ページも非常にホットなページである必要があります。いわゆる非常にホットとは、これらのページが最初の 1/4 にあることを指します。若いエリア全体の。
LRU リンク リスト に対する他の最適化手段はありますか?もちろんあります、しっかり勉強すれば論文や本を書くのは問題ありませんが、所詮は MySQL の基礎知識を紹介する記事です。長すぎると耐えられなくなり、全員に影響を及ぼします。読書経験があるので、十分で十分です。最適化の知識をさらに知りたい場合は、自分でソース コードにアクセスするか、LRU リンク リストについて詳しく学習してください~ただし、どのように最適化しても、バッファ プールのキャッシュ ヒット率を効率的に向上させるために最善を尽くすという初心を忘れないでください。
その他のリンク リスト
バッファ プールのキャッシュ ページをより適切に管理するために、上記のいくつかの対策に加えて、を設計しました。 InnoDB の叔父は、解凍されたページを管理するための unzip LRU リンク リスト 、解凍されていないページを管理するための zip clean リンク リスト など、他のいくつかの リンク リスト も紹介しました。ページ 圧縮されたページ。zip フリー配列 の各要素はリンク リストを表し、いわゆる パートナー システム を形成して、圧縮ページなどにメモリ スペースを提供します。この Buffer Pool では、さまざまなリンク リストやその他のデータ構造が紹介されています。具体的な使用方法は難しくありません。さらに詳しく知りたい場合は、より詳細な書籍を見つけるか、ソース コードを読むことができます。 ~
ヒント: InnoDB の圧縮ページについては、まったく詳しく説明していません。上記のリンクされたリストは、完全を期すために言及されているだけです。あなたは「理解する」を読んでいません、そして落ち込まないでください、なぜなら私はそれらをあなたに紹介するつもりはまったくないからです。
ダーティ ページをディスクに更新する
バックグラウンドには、ダーティ ページを時々ディスクに更新する役割を担う特別なスレッドがあるため、ユーザースレッドによる通常のリクエストの処理。主なリフレッシュ パスは 2 つあります。
-
LRU リンク リストのコールド データからディスクにあるページの一部をリフレッシュします。バックグラウンド スレッドは、
LRU リンク リストの末尾から開始していくつかのページを定期的にスキャンします。スキャンされるページの数は、システム変数innodb_lru_scan_ Depthで指定できます。ダーティ ページが 内で見つかった場合、 はそれらをディスクにフラッシュします。ページを更新するこのメソッドはBUF_FLUSH_LRUと呼ばれます。 -
フラッシュ リンク リストからページの一部をディスクに更新します。バックグラウンド スレッドは、
フラッシュ リンク リストから一部のページをディスクに定期的に更新します。リフレッシュ レートは、その時点でシステムが非常にビジーであるかどうかによって異なります。ページを更新するこのメソッドは、BUF_FLUSH_LISTと呼ばれます。
バックグラウンド スレッドによるダーティ ページの更新が遅く、ディスク ページを バッファ プール にロードする準備をしているときにユーザー スレッドに利用可能なキャッシュ ページがなくなることがあります。 LRU リンク リスト の最後に、直接解放できる未変更のページがあるかどうかを確認します。そうでない場合は、LRU リンク リスト の最後にダーティ ページが表示されます。同期的にディスクにフラッシュする必要があります (ディスクとの対話が非常に遅いため、ユーザー要求の処理が遅くなります)。単一ページをディスクにフラッシュするこのフラッシュ メソッドは、BUF_FLUSH_SINGLE_PAGE と呼ばれます。
当然,有时候系统特别繁忙时,也可能出现用户线程批量的从flush链表中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨redo日志的checkpoint时说了。
多个Buffer Pool实例
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,比方说这样:
[server] innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool实例,示意图就是这样:
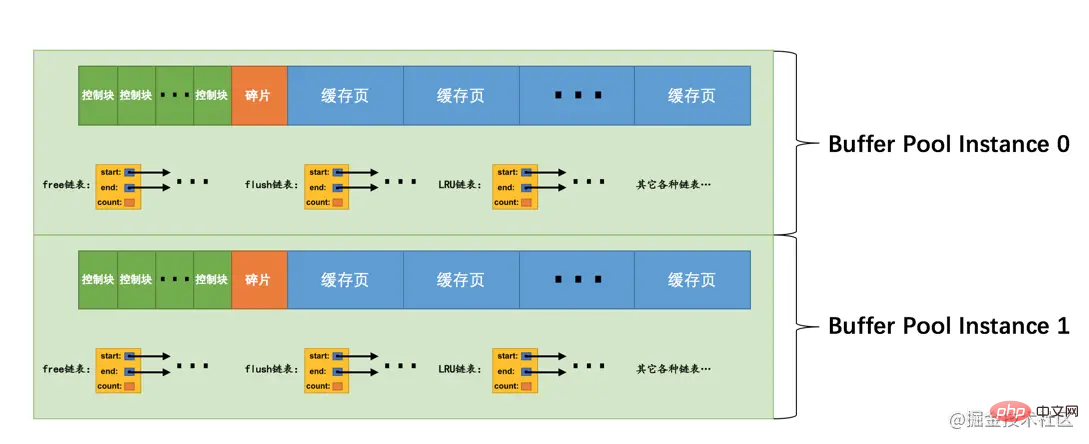
小贴士: 为了简便,我只把各个链表的基节点画出来了,大家应该心里清楚这些链表的节点其实就是每个缓存页对应的控制块!
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实例。
innodb_buffer_pool_chunk_size
在MySQL 5.7.5之前,Buffer Pool的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计MySQL的大叔在5.7.5以及之后的版本中支持了在服务器运行过程中调整Buffer Pool大小的功能,但是有一个问题,就是每次当我们要重新调整Buffer Pool大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的Buffer Pool中的内容复制到这一块新空间,这是极其耗时的。所以设计MySQL的大叔们决定不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个所谓的chunk为单位向操作系统申请空间。也就是说一个Buffer Pool实例其实是由若干个chunk组成的,一个chunk就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
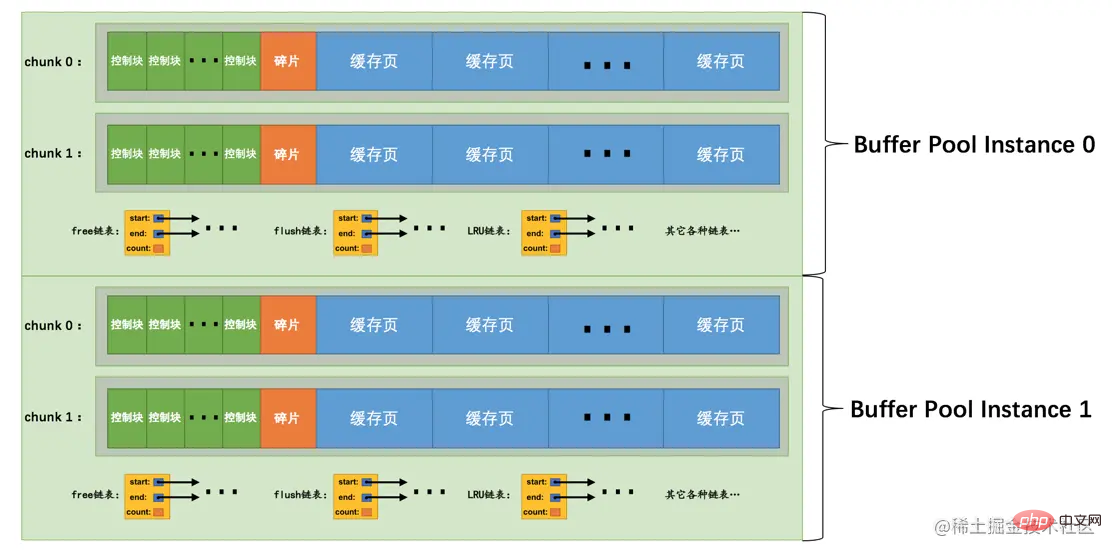
上图代表的Buffer Pool就是由2个实例组成的,每个实例中又包含2个chunk。
正是因为发明了这个chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的chunk的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
小贴士: 为什么不允许在服务器运行过程中修改innodb_buffer_pool_chunk_size的值?还不是因为innodb_buffer_pool_chunk_size的值代表InnoDB向操作系统申请的一片连续的内存空间的大小,如果你在服务器运行过程中修改了该值,就意味着要重新向操作系统申请连续的内存空间并且将原先的缓存页和它们对应的控制块复制到这个新的内存空间中,这是十分耗时的操作! 另外,这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
配置Buffer Pool时的注意事项
-
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。假设我们指定的
innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说innodb_buffer_pool_size的值必须是2G或者2G的整数倍。比方说我们在启动MySQL服务器是这样指定启动参数的:mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的
innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者2G的整数倍,上边例子中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的8G(8589934592字节):mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row in set (0.00 sec)
如果我们指定的
innodb_buffer_pool_size大于2G并且不是2G的整数倍,那么服务器会自动的把innodb_buffer_pool_size的值调整为2G的整数倍,比方说我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会自动把
innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row in set (0.01 sec)
-
如果在服务器启动时,
innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经大于innodb_buffer_pool_size的值,那么innodb_buffer_pool_chunk_size的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。比方说我们在启动服务器时指定的
innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值为256M:mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于
256M × 16 = 4G,而4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 2147483648 | +-------------------------+------------+ 1 row in set (0.01 sec) mysql> show variables like 'innodb_buffer_pool_chunk_size'; +-------------------------------+-----------+ | Variable_name | Value | +-------------------------------+-----------+ | innodb_buffer_pool_chunk_size | 134217728 | +-------------------------------+-----------+ 1 row in set (0.00 sec)
Buffer Pool中存储的其它信息
Buffer Pool的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
查看Buffer Pool的状态信息
设计MySQL的大叔贴心的给我们提供了SHOW ENGINE INNODB STATUS语句来查看关于InnoDB存储引擎运行过程中的一些状态信息,其中就包括Buffer Pool的一些信息,我们看一下(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
mysql> SHOW ENGINE INNODB STATUS\G (...省略前边的许多状态) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 956 / 1000, young-making rate 30 / 1000 not 605 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) mysql>
我们来详细看一下这里边的每个值都代表什么意思:
Total memory allocated:代表Buffer Pool向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。Dictionary memory allocated:为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。Buffer pool size:代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!Free buffers:代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。データベース ページ:youngとold## を含む、LRUリンク リスト内のページ数を表します。 # リージョン内のノードの数。古いデータベース ページ
:#LRUリンク リストold領域内のノードの数を表します。変更されたデータベース ページ
: ダーティ ページの数を表します。これは、フラッシュ リンク リスト内のノードの数です。-
保留中の読み取り
ディスクからページをロードする準備をするとき、キャッシュ ページとそれに対応する制御ブロックが: ディスクからバッファ プールにロードされるのを待機しているページの数。バッファ プール
内のこのページに割り当てられ、この制御ブロックがヘッダーに追加されます。LRUのold領域の1.保留中の書き込み LRU - :
#LRU
リンク リストからディスクにフラッシュされるページの数。保留中の書き込みフラッシュ リスト - :
flush
リンク リストからディスクにフラッシュされるページの数。単一ページの書き込み保留中 - : 単一ページとしてディスクにフラッシュされるページの数。
- :
LRU
領域からリンク リストがold領域からに移動したことを表します。 young領域の先頭にあるノードの数。ここで注意すべき点は、ノードがoldyoung
の先頭に移動した場合にのみPages made youngになるということです。つまり、ノードがもともとyoungエリアにある場合、そのノードはyoungの 1/4 の後ろにあるという要件を満たしているため、値は 1 増加します。youngエリアの先頭に移動しますが、このプロセスによってPages made youngの値が変更されることはありません。 1ずつ増加します。ページが若くありません - :
innodb_old_blocks_time
youngが 0 より大きい値に設定されている場合、場所への最初の訪問またはその後の訪問はold領域のノードが時間間隔の制限を満たしていないためにyoung領域の先頭に移動できない場合、Page の値は young# ではありません## が 1 増加します。ここで注意すべき点は、youngエリアにあるノードの場合、エリアの 1/4 であるため ## に移動しない場合です。 #young
:エリアヘッダーの場合、このようなアクセスによってPage made not youngの値が 1 増加することはありません。youngs/sold - 領域から
young
: 時間が制限されているため、の先頭に移動されたノードの数を表します。 1秒あたりの面積。non-youngs/sold - 領域から
young# に移動できないすべての秒を表します。制限が満たされていません。##領域の先頭にあるノードの数。
createdPages read、 、 - writing
: 読み取り、作成、書き込みされたページの数を表します。次に、読み取り、作成、書き込みの速度が続きます。
バッファ プールにキャッシュされた回数を示します。 .バッファ プール ヒット率: 過去の期間の平均 1,000 回のページ訪問でページが 。 -
若い若手化率: 過去の一定期間に、そのページが平均 1,000 回アクセスされ、何回のアクセスが移動したかを示します。 地域の責任者へのページ。 -
誰もが注意する必要があるのは、ここでカウントされる
エリア ヘッドがyoung領域にページを移動するヘッダーの数には、old## からの移動だけが含まれるわけではないということです。 # エリアからyoung への回数young
地域の責任者にページを移動しませんでした。エリアからyoungエリア ヘッドに移動した回数も含まれます (youngエリア内のノードは、そのノードがyoungエリアの 1/4 後ろにある場合、youngエリアの先頭に移動されます。 )。not (若手育成率): 過去の一定期間に、ページが平均 1,000 回アクセスされたことを示します。多くの訪問者がyoung - 誰もが注意する必要があるのは、ここでカウントされている
young
young領域にページが移動されないヘッダー回数は、# の設定だけが原因ではないということです。 ##innodb_old_blocks_timeシステム変数oldエリア内のノードがエリアに移動せずにアクセスされた回数 (ノードが最初の 1/4 にあったことも含む)
youngエリアの先頭に移動されなかった回数。#LRU len:#LRU リンク リスト内のノードの数を表します。unzip_LRU - :
unzip_LRU リンク リスト
内のノードの数を表します (このリンク リストについては具体的に説明していないため、その値は現在は無視できます)。I/O sum - : 過去 50 秒間に読み取られたディスク ページの合計数。
: 現在読み取られているディスク ページの数。I/O cur -
: 過去 50 秒間に解凍されたページの数。I/O unzip sum -
: 解凍されるページの数。I/O unzip cur
总结
磁盘太慢,用内存作为缓存很有必要。
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。InnoDB使用了许多链表来管理Buffer Pool。free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。为了快速定位某个页是否被加载到
Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。在
Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。我们可以通过指定
innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。自
MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。-
可以用下边的命令查看
Buffer Pool的状态信息:SHOW ENGINE INNODB STATUS\G
推荐学习:mysql视频教程
以上がMySQL の原則の深い理解: バッファ プール (詳細な図とテキストの説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。