
Oracle でのインデックスの作成と使用 (概要の共有)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2021-12-31 18:53:5212042ブラウズ
この記事では、Oracle でのインデックスの作成と使用についての知識を提供します。お役に立てば幸いです。

#OLTP システム インデックスの作成
作成インデックスの役割1. 一意のインデックスを作成すると、データベース テーブル内のデータの各行の一意性が保証されます。 2. データの取得を大幅に高速化でき、これがインデックスを作成する主な理由でもあります。 3. テーブル間の接続を高速化でき、これはデータの参照整合性を実現する上で特に意味があります。 4. データの取得にグループ化句と並べ替え句を使用すると、クエリでのグループ化と並べ替えにかかる時間も大幅に短縮できます。 5. インデックスを使用すると、クエリ プロセス中に最適化非表示機能を使用してシステム パフォーマンスを向上させることができます。インデックス列の選択方法1. インデックス列を構築する必要があります。機能1) 頻繁に検索が必要な列で、検索を高速化できます;2) 主キーとして機能する列で、列の一意性を強制し、列を整理します。テーブル内のデータの配置構造;3) 接続でよく使用される列では、これらの列は主に外部キーであるため、接続を高速化できます;4)範囲に基づいて検索する必要があることがよくあります。インデックスは並べ替えられており、指定された範囲は連続しているため、列にインデックスを作成します。5) 頻繁に並べ替えが必要な列にインデックスを作成します。インデックスがソートされているため、クエリでインデックスのソートを利用できるようになり、クエリのソート時間を高速化します; 6) WHERE 句で頻繁に使用される列にインデックスを作成して、クエリを高速化します。条件の判断。 2. インデックスを作成すべきでない列の特性1) クエリでほとんど使用または参照されない列にはインデックスを作成しないでください。これは、これらの列がほとんど使用されないため、インデックスを作成してもしなくてもクエリ速度は向上しないためです。逆に、インデックスの追加により、システムのメンテナンス速度が低下し、必要なスペースが増加します。 2) データ値が少ない列のインデックスは増加させないでください。これは、クエリ結果ではこれらの列 (人事テーブルの性別列など) の値が非常に少ないため、結果セット内のデータ行がテーブル内のデータ行の大部分を占めるためです。テーブル内で検索する必要があるデータ 行の割合が膨大です。インデックスを増やしても、検索が大幅に高速化されるわけではありません。 3) BLOB データ型として定義された列にはインデックスを追加しないでください。これは、これらの列のデータ量が非常に大きいか、値が非常に少ないためです。 4) 変更パフォーマンスが検索パフォーマンスを大幅に上回る場合、インデックスを作成すべきではありません。修正性能と検索性能は相反するものだからである。インデックスを追加すると、検索パフォーマンスは向上しますが、変更パフォーマンスは低下します。インデックスを減らすと、変更パフォーマンスは向上しますが、検索パフォーマンスは低下します。したがって、変更パフォーマンスが検索パフォーマンスよりもはるかに高い場合は、インデックスを作成しないでください。 (データ量が膨大であるため、パーティション化されたインデックスの作成を検討してください) インデックス作成構文
CREATEUNIUQE | BITMAP INDEX <schema>.<index_name>
ON <schema>.<table_name>
(<column_name> | <expression> ASC | DESC,
<column_name> | <expression> ASC | DESC,...)
TABLESPACE <tablespace_name>
STORAGE <storage_settings>
LOGGING | NOLOGGING
COMPUTE STATISTICS
NOCOMPRESS | COMPRESS<nn>
NOSORT | REVERSE
PARTITION | GLOBAL PARTITION<partition_setting>
関連手順1) UNIQUE | BITMAP: 一意の値として UNIQUE を指定します。 BITMAP は B-Tree インデックスとして省略されたビットマップ インデックスです。 2) f4c55dd52f1b37a9debd48ac1ff8dbb5 |41256fb142f22f4bfc3f76fe922f5535 ASC | DESC: 複数の列に結合インデックスを作成できます。expression の場合、関数ベースのインデックスになります 3) TABLESPACE:インデックスが保存されるテーブルスペースを指定します (インデックスと元のテーブルが同じテーブルスペースにない場合、より効率的です)4) STORAGE: テーブルスペースのストレージパラメータをさらに設定できます。 5) LOGGING | NOLOGGING: インデックスの REDO ログを生成するかどうか (スペースを削減し、効率を向上させるために、大きなテーブルには NOLOGGING を使用するようにしてください)6) COMPUTESTATISTICS: 新しいテーブルを作成するときに統計情報を収集します。 Index7) NOCOMPRESS | COMPRESS3d7242a4fb043913c01e717913c52b04: 「キー圧縮」を使用するかどうか (キー圧縮を使用すると、キー列に出現する重複値を削除できます) 8) NOSORT | REVERSE: NOSORT はテーブル内と同じ順序でインデックスを作成することを意味し、REVERSE はその逆を意味します インデックス値を順番に格納します9) PARTITION | NOPARTITION: 作成されたインデックスはパーティション化されたテーブルでパーティション化することも、パーティション化しないこともできますテーブルインデックスの使用に関する誤解インデックスの制限インデックスの制限は、経験の浅い開発者がよく犯す間違いの 1 つです。 SQL には、一部のインデックスを使用できなくするトラップが多数あります。いくつかの一般的な問題については以下で説明します:
1. 不等演算子 (a8093152e673feb7aba1828c43532094, !=)
を使用します。 cust_rated 列のインデックス、クエリ ステートメントでは引き続きテーブル全体のスキャンが実行されます。
select cust_Id,cust_name from customers wherecust_rating<> 'aa';上記のステートメントを次のクエリ ステートメントに変更して、コストベースのオプティマイザーではなくルールベースのオプティマイザーを使用するときにインデックスが使用されるようにします (よりインテリジェントな)。
select cust_Id,cust_name fromcustomers where cust_rating<'aa' orcust_rating > 'aa';特記事項: 不等号演算子を OR 条件に変更すると、インデックスを使用してテーブル全体のスキャンを回避できます。
2. IS NULL または IS NOT NULL を使用する
ISNULL または ISNOT NULL を使用すると、インデックスの使用も制限されます。 NULL値が定義されていないためです。
在 SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。
3、使用函数
如果不使用基于函数的索引,那么在 SQL语句的 WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引)
select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
把上面的语句改成下面的语句,这样就可以通过索引进行查找。
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
4、比较不匹配的数据类型
也是比较难于发现的性能问题之一。 注意下面查询的例子,account_number是一个VARCHAR2类型,在 account_number字段上有索引。
下面的语句将执行全表扫描:
select bank_name,address,city,state,zip from banks whereaccount_number = 990354;
Oracle 可以自动把 where子句变成to_number(account_number)=990354,这样就限
制了索引的使用,改成下面的查询就可以使用索引:
select bank_name,address,city,state,zip from banks where account_number='990354';
特别注意: 不匹配的数据类型之间比较会让Oracle自动限制索引的使用,即便对这个查询执行ExplainPlan也不能让您明白为什么做了一次―全表扫描。
5、查询索引
查 询 DBA_INDEXES视 图 可 得 到 表 中 所 有 索 引 的 列表 , 注 意 只 能 通 过USER_INDEXES的方法来检索模式(schema)的索引。访问 USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。
6、 组合索引
当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表 emp 有一个组合索引键,该索引包含了 empno、 ename和 deptno。在Oracle9i之前除非在 where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。
特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引
索引分类
Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,下面就将简单的讨论每个索引选项。
在这里讨论如下的索引类型:
B树索引(默认类型)
位图索引
HASH索引
索引组织表索引
反转键(reverse key)索引
基于函数的索引
分区索引(本地和全局索引)
位图连接索引
B树索引 (默认类型)
B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。
在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。
树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)
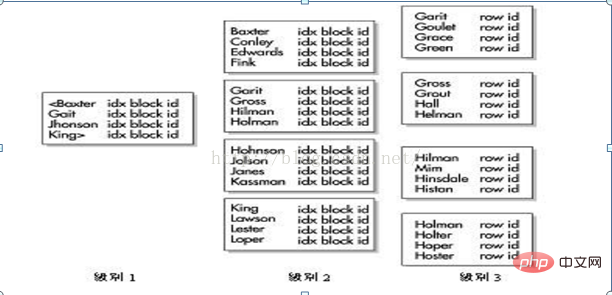
技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从中检索数据,从而减少了I/O量。
B-tree特点:
适合与大量的增、删、改(OLTP)
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
位图索引
位图索引非常适合于决策支持系统(Decision Support System,DSS)和数据仓库,它们不应该用于通过事务处理应用程序访问的表。它们可以使用较少到中等基数(不同值的数量)的列访问非常大的表。
尽管位图索引最多可达30个列,但通常它们都只用于少量的列。
例如,您的表可能包含一个称为Sex的列,它有两个可能值:男和女。这个基数只为2,如果用户频繁地根据Sex列的值查询该表,这就是位图索引的基列。当一个表内包含了多个位图索引时,您可以体会到位图索引的真正威力。如果有多个可用的位图索引,Oracle就可以合并从每个位图索引得到的结果集,快速删除不必要的数据。
Bitmapt特点:
适合与决策支持系统;做 UPDATE代价非常高
非常适合 OR操作符的查询;基数比较少的时候才能建位图索引;
技巧:对于有较低基数的列需要使用位图索引。性别列就是这样一个例子,它有两个可能值:男或女(基数仅为2)。位图对于低基数(少量的不同值)列来说非常快,这是因为索引的尺寸相对于B树索引来说小了很多。因为这些索引是低基数的 B 树索引,所以非常小,因此您可以经常检索表中超过半数的行,并且仍使用位图索引。
当大多数条目不会向位图添加新的值时,位图索引在批处理(单用户)操作中加载表(插入操作)方面通常要比B树做得好。当多个会话同时向表中插入行时不应该使用位图索引,在大多数事务处理应用程序中都会发生这种情况。
示例
下面来看一个示例表PARTICIPANT,该表包含了来自个人的调查数据。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的位图索引。 下图显示了每个直方图中的数据平衡情况,以及对访问每个位图索引的查询的执行路径。图中的执行路径显示了有多少个位图索引被合并,可以看出性能得到了显著的提高。

如上图图所示,优化器依次使用4个单独的位图索引,这些索引的列在WHERE子句中被引用。每个位图记录指针(例如0或1),用于示表中的哪些行包含位图中的已知值。有了这些信息后,Oracle就执行BITMAP AND操作以查找将从所有4个位图中返回哪些行。该值然后被转换为ROWID值,并且查询继续完成剩余的处理工作。注意,所有4个列都有非常低的基数,使用索引可以非常快速地返回匹配的行。
技巧:在一个查询中合并多个位图索引后,可以使性能显著提高。位图索引使用固定长度的数据类型要比可变长度的数据类型好。较大尺寸的块也会提高对位图索引的存储和读取性能。
下面的查询可显示索引类型。
SQL> select index_name, index_type from user_indexes; INDEX_NAME INDEX_TYPE ------------------------------ ---------------------- TT_INDEX NORMAL IX_CUSTADDR_TP NORMAL
B 树索引作为NORMAL列出;而位图索引的类型值为BITMAP。
技巧:如果要查询位图索引列表,可以在USER_INDEXES视图中查询index_type列。
建议不要在一些联机事务处理(OLTP)应用程序中使用位图索引。B树索引的索引值中包含ROWID,这样Oracle就可以在行级别上锁定索引。位图索引存储为压缩的索引值,其中包含了一定范围的ROWID,因此Oracle必须针对一个给定值锁定所有范围内的ROWID
这种锁定类型可能在某些DML语句中造成死锁。SELECT语句不会受到这种锁定问题的影响。
位图索引的使用限制:
基于规则的优化器不会考虑位图索引。
当执行 ALTER TABLE语句并修改包含有位图索引的列时,会使位图索引失效。位图索引不包含任何列数据,并且不能用于任何类型的完整性检查。位图索引不能被声明为唯一索引。位图索引的最大长度为30。
ヒント: 負荷の高い OLTP 環境ではビットマップ インデックスを使用しないでください
HASH インデックス
HASH インデックスを使用するには、HASH クラスターを使用する必要があります。クラスターまたは HASH クラスターが確立されると、クラスターキーも定義されます。このキーは、Oracle にテーブルをクラスタに格納する方法を指示します。データを保存するとき、このクラスター キーに関連するすべての行がデータベース ブロックに保存されます。
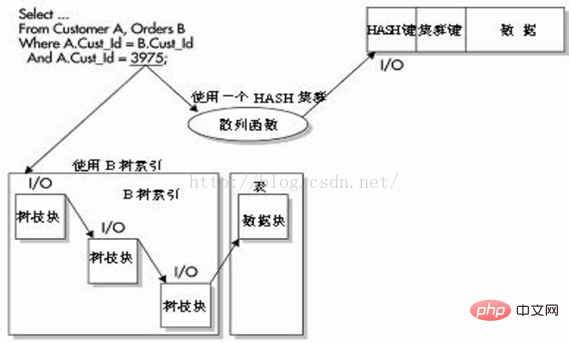
データがすべて同じデータベース ブロックに格納されており、HASH インデックスが WHERE 句の完全一致として使用されている場合、Oracle は HASH 関数と I/O を実行することによってデータにアクセスできます。バイナリ高さ 4 の B ツリー インデックスを使用してデータにアクセスするには、データの取得時に 4 つの I/O が必要です。
以下の図に示すように、クエリは同等のクエリであり、HASH 列と正確な値を一致させるために使用されます。
Oracle は、この値を使用して、HASH 関数に基づいて行の物理的な記憶場所を迅速に決定できます。
HASH インデックスはデータベース内のデータにアクセスする最も速い方法かもしれませんが、独自の欠点もあります。 HASH クラスターを作成する前に、クラスター キー上の個別の値の数を把握しておく必要があります。この値は、HASH クラスターの作成時に指定する必要があります。異なるクラスター キー値の数を過小評価すると、クラスターの競合 (同じハッシュ値を持つ 2 つのクラスター キー) が発生する可能性があります。この種の競合は非常にリソースを消費します。競合により、余分な行を格納するために使用されるバッファがオーバーフローする可能性があり、その結果、余分な I/O が発生します。異なるハッシュ値の数が過小評価されている場合は、クラスターを再構築した後にこの値を変更する必要があります。
ALTER CLUSTER コマンドでは、HASH キーの数を変更できません。 HASH クラスターもスペースを無駄にする可能性があります。クラスターキー上のすべての行を維持するために必要なスペースの量を判断できない場合、スペースを無駄にする可能性があります。クラスターの将来の成長に備えて追加のスペースを割り当てることができない場合、HASH クラスターは最良の選択ではない可能性があります。
アプリケーションがクラスター化テーブルに対してフルテーブルスキャンを頻繁に実行する場合、HASH クラスタリングは最良の選択ではない可能性があります。フルテーブルスキャンは、将来の成長に備えてクラスター内の残りのスペースを割り当てる必要があるため、非常にリソースを消費する可能性があります。
HASH クラスターを実装する前に注意してください。このオプションを実装する前に、アプリケーションを徹底的に調べて、テーブルとデータについて十分に理解していることを確認する必要があります。一般に、HASH は、順序付けされた値を含む一部の静的データに対して非常に効果的です。
ヒント: HASH インデックスは制限がある場合 (値の範囲ではなく特定の値を指定する必要がある場合)
##インデックス構成テーブル
インデックス構成テーブルが変更されますテーブルの記憶構造を B ツリー構造に変換し、テーブルの主キーでソートします。この特別なテーブルは、他のタイプのテーブルと同様に、テーブル上のすべての DML ステートメントと DDL ステートメントを実行できます。テーブルの特殊な構造により、ROWID はテーブルの行に関連付けられません。
完全一致や範囲検索を含む一部のステートメントの場合、索引構成表はキーベースの高速データ・アクセス・メカニズムを提供します。行が物理的に順序付けられるため、主キー値に基づく UPDATE および DELETE ステートメントのパフォーマンスも向上します。
キー列の値がテーブルやインデックス内で重複しないため、格納に必要な領域も削減されます。主キー列に対してデータが頻繁にクエリされない場合は、索引構成表の他の列にセカンダリ索引を作成する必要があります。主キーに基づいてテーブルを頻繁にクエリしないアプリケーションでは、インデックスを使用してテーブルを編成する利点を最大限に活用できません。主キーの完全一致または範囲スキャンによって常にアクセスされるテーブルの場合は、インデックスを使用してテーブルを編成することを検討してください。
ヒント: 索引構成表にセカンダリ・インデックスを作成できます。
リバース キー インデックス
順序付けされたデータをロードする場合、インデックスは必ず I/O に関連するボトルネックに遭遇します。データのロード中に、インデックスとディスクの一部の部分が他の部分よりもはるかに頻繁に使用されることになります。この問題を解決するには、ファイルを物理的に複数のディスクに分割できるディスク アーキテクチャにインデックス テーブル スペースを保存します。
この問題を解決するために、Oracle はキー インデックスを逆にする方法も提供しています。逆キーインデックスを使用してデータが保存されている場合、データの値は元に保存されている値の逆になります。このようにして、データ 1234、1235、および 1236 は、4321、5321、および 6321 として格納されます。その結果、インデックスは新しく挿入された行ごとに異なるインデックス ブロックを更新します。
ヒント: ディスク容量が限られており、大量の順序付けされたロードを実行している場合は、逆キー インデックスを使用できます。
逆キー索引は、ビットマップ索引または索引構成表では使用できません。ビットマップ索引および索引構成表は逆キー化できないためです。
数値ベースのインデックス
テーブル内に関数ベースのインデックスを作成できます。関数ベースのインデックスがないと、列に対して関数を実行するクエリはその列のインデックスを使用できません。たとえば、次のクエリでは、関数ベースのインデックスでない限り、JOB 列のインデックスを使用できません。select * from emp where UPPER(job) = 'MGR';
下面的查询使用 JOB列上的索引,但是它将不会返回JOB列具有Mgr或mgr值的行:
select * from emp where job = 'MGR';
可以创建这样的索引,允许索引访问支持基于函数的列或数据。可以对列表达式 UPPER(job)创建索引,而不是直接在JOB列上建立索引,如:
create index EMP$UPPER_JOB on emp(UPPER(job));尽管基于函数的索引非常有用,但在建立它们之前必须先考虑下面一些问题:
能限制在这个列上使用的函数吗?如果能,能限制所有在这个列上执行的所有函数吗?是否有足够应付额外索引的存储空间?在每列上增加的索引数量会对针对该表执行的DML语句的性能带来何种影响?
基于函数的索引非常有用,但在实现时必须小心。在表上创建的索引越多,INSERT、UPDATE和DELETE语句的执行就会花费越多的时间。
注意:对于优化器所使用的基于函数的索引来说,必须把初始参数QUERY_REWRITE _ ENABLED 设定为 TRUE。
示例:
select count(*) from sample where ratio(balance,limit) >.5; Elapsed time: 20.1 minutes create index ratio_idx1 on sample (ratio(balance, limit)); select count(*) from sample where ratio(balance,limit) >.5; Elapsed time: 7 seconds!!!
分区索引
分区索引就是简单地把一个索引分成多个片断。通过把一个索引分成多个片断,可以访问更小的片断(也更快),并且可以把这些片断分别存放在不同的磁盘驱动器上(避免I/O问题)。
B树和位图索引都可以被分区,而HASH索引不可以被分区。可以有好几种分区方法:表被分区而索引未被分区;表未被分区而索引被分区;表和索引都被分区。
不管采用哪种方法,都必须使用基于成本的优化器。分区能够提供更多可以提高性能和可维护性的可能性有两种类型的分区索引:本地分区索引和全局分区索引。
每个类型都有两个子类型,有前缀索引和无前缀索引。表各列上的索引可以有各种类型索引的组合。如果使用了位图索引,就必须是本地索引。
把索引分区最主要的原因是可以减少所需读取的索引的大小,另外把分区放在不同的表空间中可以提高分区的可用性和可靠性。在使用分区后的表和索引时,Oracle还支持并行查询和并行DML。这样就可以同时执行多个进程,从而加快处理这条语句。
本地分区索引(通常使用的索引)
可以使用与表相同的分区键和范围界限来对本地索引分区。每个本地索引的分区只包含了它所关联的表分区的键和ROWID。本地索引可以是B树或位图索引。如果是 B树索引,它可以是唯一或不唯一的索引。
这种类型的索引支持分区独立性,这就意味着对于单独的分区,可以进行增加、截取、删除、分割、脱机等处理,而不用同时删除或重建索引。Oracle自动维护这些本地索引。本地索引分区还可以被单独重建,而其他分区不会受到影响。
(1) 有前缀的索引
有前缀的索引包含了来自分区键的键,并把它们作为索引的前导。例如,让我们再次回顾 participant表。在创建该表后,使用survey_id和survey_date这两个列进行范围分区,然后在survey_id列上建立一个有前缀的本地索引,如下图所示。这个索引的所有分区都被等价划分,就是说索引的分区都使用表的相同范围界限来创建。
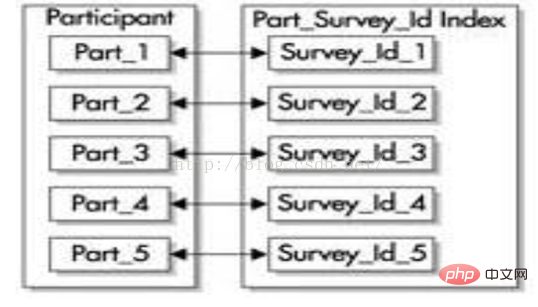
技巧:本地的有前缀索引可以让Oracle快速剔除一些不必要的分区。也就是说
没有包含 WHERE条件子句中任何值的分区将不会被访问,这样也提高了语句
的性能。
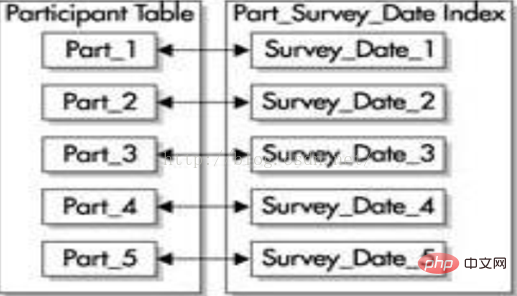
(2) 接頭辞なしのインデックス
接頭辞なしのインデックスは、パーティション キーの先頭列をインデックスの先頭列として使用しません。同じパーティション キー (survey_id と Survey_date) を持つ同じパーティション テーブルを使用する場合、次の図に示すように、survey_date 列に構築されるインデックスは接頭辞のないローカル インデックスになります。接頭辞のないローカルの
インデックスはテーブルの任意の列に作成できますが、インデックスの各パーティションには、テーブルの対応するパーティションのキー値のみが含まれます。
#接頭辞のないインデックスを一意のインデックスとして設定する場合は、インデックスにパーティション キーのサブセットが含まれている必要があります。
この例では、survey と ## を含める必要があります。 #( または ) 調査 ID 列は結合されます (As long
#survey_id# はインデックスの最初の列ではなく、接頭辞付きのインデックスです。 )。
ヒント: プレフィックスのない一意のインデックスの場合、次の内容が含まれている必要があります。パーティションキーのサブセット。
グローバル パーティション インデックス
#グローバル パーティション インデックスには、1 つのインデックス パーティションに複数のテーブル パーティションのキーが含まれています。グローバル パーティション インデックスのパーティション キーは、パーティション テーブル内の個別の値または指定された範囲の値です。グローバルパーティションインデックスを作成するときは、パーティションキーの範囲と値を定義する必要があります。
グローバル インデックスは B ツリー インデックスのみにすることができます。 Oracle はデフォルトではグローバル・パーティション索引を維持しません。パーティションが切り捨て、追加、分割、削除などされた場合、テーブルの変更時に ALTER TABLE コマンドの UPDATE GLOBAL INDEXES 句が指定されていない限り、グローバル パーティション インデックスを再構築する必要があります。
(2) 接頭辞付きインデックス 通常、グローバル接頭辞付きインデックスは、基礎となるテーブル内でピア パーティション化されません。 インデックスのピア パーティショニングを制限するものはありませんが、Oracle はクエリ プランの生成やパーティション メンテナンス操作の実行時にピア パーティショニングを最大限に活用できません。索引がピア・パーティション化されている場合は、次の図に示すように、Oracle が索引を維持し、それを使用して不要なパーティションを削除できるように、索引をローカル索引として作成する必要があります。この図では、3 つのインデックス パーティションのそれぞれに、複数のテーブル パーティション内の行を指すインデックス エントリが含まれています。
分区的、全局有前缀索引
( 2) 无前缀的索引
位图连接索引是基于两个表的连接的位图索引,在数据仓库环境中使用这种索引改进连接维度表和事实表的查询的性能。创建位图连接索引时,标准方法是 连接索引中常用的维度表和事实表。当用户在一次查询中结合查询事实表和维度表时,就不需要执行连接,因为在位图连接索引中已经有可用的连接结果。通过压缩位图连接索引中的ROWID进一步改进性能,并且减少访问数据所需的I/O数量。 创建位图连接索引时,指定涉及的两个表。相应的语法应该遵循如下模式: 位图连接的语法比较特别,其中包含 FROM子句和WHERE子句,并且引用两个单独的表。索引列通常是维度表中的描述列——就是说,如果维度是 CUSTOMER,并且它的主键是CUSTOMER_ID,则通常索引Customer_Name 这样的列。如果事实表名为 SALES,可以使用如下的命令创建索引: 如果用户接下来使用指定 Customer_Name列值的WHERE子句查询 SALES和CUSTOMER表,优化器就可以使用位图连接索引快速返回匹配连接 条件和 Customer_Name条件的行。 位图连接索引的使用一般会受到限制: 1) 只可以索引维度表中的列。 2) 用于连接的列必须是维度表中的主键或唯一约束;如果是复合主键,则 必须使用连接中的每一列。 3) 不可以对索引组织表创建位图连接索引,并且适用于常规位图索引的限 制也适用于位图连接索引。
注意:以上总结是对oracle数据库中索引创建的一些知识的介绍和关键点。需要读懂理解之后结合系统业务情况合理创建索引,以求达到预期性能。 本文部分内容摘自《Oracle超详细讲解.pdf》 推荐教程:《Oracle教程》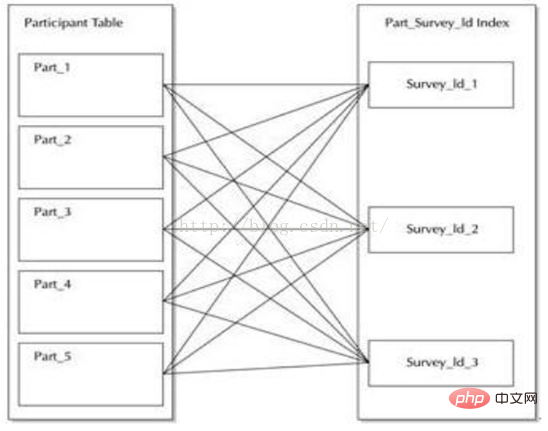 #
#
技巧:如果一个全局索引将被对等分区,就必须把它创建为一个本地索引,
这样 Oracle可以维护这个索引,并使用它来删除不必要的分区。
Oracle不支持无前缀的全局索引。位图连接索引
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from
FACT, DIM where FACT.JoinCol = DIM.JoinCol;
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
以上がOracle でのインデックスの作成と使用 (概要の共有)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。