
ホームページ >データベース >mysql チュートリアル >共有が高く評価されました: 本番環境に沿った MySQL 最適化のアイデア
共有が高く評価されました: 本番環境に沿った MySQL 最適化のアイデア

- 藏色散人転載
- 2021-11-05 14:16:082407ブラウズ
まえがき
この記事を書く出発点は、仕事でデータの問題に対処する中で私が蓄積した経験を記録することです。インデックスを最適化する場合、スロークエリ、Explain、およびその他の関連機能について一定の理解が必要であるなど、その他の背景知識を提供する必要があります。たとえば、Elasticsearch を導入するには、データ同期の問題を解決したり、Elasticsearch の知識を学習したりする必要があります。記事が長いため、すべてのポイントを網羅することは不可能ですが、ビデオチュートリアルのように詳細に説明されているため、私の限られた知識といくつかの一般的なポイントに基づいて要約することしかできません。とはいえ、記事がかなり長くなってしまいましたので、気になる点がございましたら、Baidu/Google などで詳細をご確認ください。
この記事は非常に長いので、興味があれば最後まで読んでいただければ幸いです。数十分を無駄にしないでください。 [推奨学習: "mysql ビデオ チュートリアル "]
考え方の視点
データベース テクノロジは、手動管理段階とファイル システム段階を経てきました。これまでのところ、データベース システムの段階です。
ソフトウェア システムが存在しなかった初期の頃、特定のビジネスの現実世界の運営は、手作業による会計処理と口頭での契約という手動の管理段階を通じても実現できました。この形式は長い間存在し、比較的非効率な計画です。次の段階では、コンピューター技術の発展に伴い、手作業による会計処理を Excel テーブルに置き換えたファイル システム段階があり、生産性がある程度向上しました。シンプル操作で高効率なデータベースシステムであるソフトウェアシステム段階では、生産性が再び向上し、現実世界の具体的な問題がデータに抽象化され、データの流れと変化によって現実世界のビジネスが表現されます。ソフトウェア システムでは、データ ストレージは通常、リレーショナル データベースと複数の非リレーショナル データベースで構成されます。
データベースはシステム ビジネスと密接に関連しています。そのため、プロダクト マネージャーはビジネスを設計する際に、データ ストレージとクエリのプロセスを理解する必要があります。設計の開始時に、ビジネスの変更がどのような影響を与えるかを明確にします。データベースに存在するかどうか、および新しいテクノロジー スタックを参照する必要があるかどうかを確認します。例えば、プロダクトマネージャーが設計した業務は、単一テーブル数が数百万にも及ぶ複数のMySQLテーブルのデータを統計分析・集計するというもので、MySQLの複数テーブルクエリをそのまま使用すると、確実にクエリの低速化が発生し、msyqlエラーの原因となります。この場合の解決策は、製品側で妥協するか、テクノロジー スタックを変更することです。
システム アーキテクチャとデータベース ソリューションでは、会社のチームの能力により適したものを選択する必要があります。システムの初期段階では、紙幣機能を備えた単純なデータベースの最適化が最もコスト効率が高くなります。解決策はありますが、mysql データベースの紙幣機能となるとどうすることもできず、重要な機能に焦点を当てたソフトウェア サービスを導入することが最も費用対効果の高いソリューションになります。問題が発生したときに適切なソリューションを選択するのは、あなたの価値観を反映します。
貧しい少年は金持ちの少女と恋に落ちます。短期的な甘さは現実の階級的不平等に匹敵するものではありません。ハッピーエンドは貧しい少年の空想と瓊瑶先生のテレビシリーズの中にのみ存在します。
限られたコストでデータ ストレージのパフォーマンスを向上させる方法が、この記事の中心的なアイデアです。
予備知識
皆さんも日々の業務で以下の内容に触れる機会が多いと思いますので、簡単にまとめておきます。
リレーショナル データベース
リレーショナル データベースは、2 次元のテーブルとそれらの間の関係で構成されるデータ組織であり、トランザクション データの一貫性を提供します。データの永続化などの機能は、ソフトウェア システムのコア ストレージ サービスです。これらは、開発や面接中に最も頻繁に接触するデータベースです。一部の小規模なアウトソーシング プロジェクトでは、1 つの MySQL ですべてのビジネス ニーズを満たすのに十分です。私たちがよく触れるものですが、実は裏技がたくさんあるので、次の章で詳しく解説していきます。
利点:
- トランザクション
- 永続性
- 比較的一般的な SQL 言語
問題
- ハードディスク I/O の要件は非常に高いです
- 大量のデータの集計クエリの効率は低いです
- インデックスのミス
- 左端インデックスの一致原理により不一致が発生する 全文検索に適している #トランザクションの使い方を誤るとロックが混雑する
- #水平展開によるさまざまな問題への対応が難しい
非リレーショナル タイプ データベース - NoSqlMySQL データベースは、リレーショナル データ ストレージ ソフトウェアとして、利点と明らかな欠点があるため、ソフトウェア システムのデータ量が増加し続けると、ソフトウェアシステムの拡張とビジネスの複雑さは増大し続けるため、MySQL データベースの機能強化だけですべての問題を解決することは期待できず、代わりに、他のストレージ ソフトウェアの導入やさまざまなタイプの NoSQL の使用がソフトウェア システムの拡張の問題を解決する必要があります。データ量とビジネスの複雑さの増大。
リレーショナル データベースは、リレーショナル データベースをさまざまなシナリオに最適化したものであり、何らかの NoSQL を導入すればすべてがうまくいくというわけではなく、市場にある NoSQL の種類と適用の難しさを十分に理解する必要があり、適切なシナリオで適切なストレージを選択するには、ソフトウェアが最適です。Key-Value タイプビジネスでは、特定のテーブルの内容が頻繁にクエリされますが、クエリ結果のほとんどは変更されないため、Key-Value ストレージ ソフトウェア、主に Memcached と Redis が登場し、システム内のキャッシュ モジュールで広く使用されています。 Redis は Memcached よりも多くのデータ構造と永続性を備えており、KV 型 NoSQL の中で最も広く使用されています。
検索タイプ全文検索のシナリオでは、MySQLB ツリー インデックスのクエリ最適化では、類似クエリはインデックスにヒットできず、類似キーワード クエリはすべて 1 つです。 time フルテーブルスキャンは、数万のデータを持つテーブルでサポートできますが、データが最後にあるときにクエリが遅くなります。ビジネス コードが適切に記述されておらず、トランザクション内で Like クエリが呼び出された場合、読み取りロックが発生します。が発生します。 ElasticSearch は、転置インデックスを核として、全文検索のシナリオに完璧に対応できると同時に、大規模なデータを非常によくサポートし、ドキュメントとエコロジーも非常に優れています。タイプ。
ドキュメント タイプドキュメント タイプ NoSql は、半構造化データをドキュメントとして保存する NoSql のタイプを指します。ドキュメント タイプ NoSql は通常、データを JSON または XML 形式で保存します。 , したがって、ドキュメント型 NoSql にはスキーマがありません。スキーマ機能がないため、自由にデータを保存したり読み込んだりすることができます。したがって、ドキュメント型 NoSql の登場により、リレーショナル データベースのテーブル構造の拡張の不便さの問題が解決されます。著者は、
列式を一度も使用したことがありません。特定の規模の企業の場合、ビジネスにはリアルタイムで柔軟なデータの要約が含まれることが多く、これはビジネスには適していません。このような業務は事前に計算するという解決策を使って問題を解決しましょう 事前に計算して集計するという解決策で業務を書くことができても、集計データの数が増えてくると、最終的に集計データを蓄積する作業が難しくなってしまいます。徐々に非常に遅くなります。カラムベースの NoSQL は、このシナリオの産物です。これは、ビッグ データ時代の最も代表的なテクノロジの 1 つです。最も一般的なのは HBase ですが、HBase のアプリケーションは非常に重く、多くの場合、完全なアプリケーションが必要です。実行する Hadoop エコシステムのセット 著者の会社である Alibaba Cloud の AnalyticDB (MySql クエリ ステートメントと互換性のあるカラム ストレージ ソフトウェア) が使用されています。サマリー列ストレージ ソフトウェアの強力なクエリ機能は、さまざまなリアルタイムで柔軟なデータ サマリー サービスをサポートするのに十分です。
ケース 2021 年をノードとして考えると、ほとんどのシステムは初期段階で次の計画を立てて開始します。
 #ハードウェアのアップグレードによってもたらされるメリットは、時間の経過とともに減少します。時間と人員が限られている場合、これが最速の最適化ソリューションです。ソフトウェアの最適化によってもたらされるメリットは将来的にはさらに大きくなりますが、必要な技術人材のレベルも将来的には高くなるため、時間と人員が許せば、最も費用対効果の高い最適化ソリューションとなります。ハードウェアとソフトウェアの最適化は相互に排他的ではなく、必要に応じて、両方を同時に MYSQL パフォーマンスの上限に近づけることができます。
#ハードウェアのアップグレードによってもたらされるメリットは、時間の経過とともに減少します。時間と人員が限られている場合、これが最速の最適化ソリューションです。ソフトウェアの最適化によってもたらされるメリットは将来的にはさらに大きくなりますが、必要な技術人材のレベルも将来的には高くなるため、時間と人員が許せば、最も費用対効果の高い最適化ソリューションとなります。ハードウェアとソフトウェアの最適化は相互に排他的ではなく、必要に応じて、両方を同時に MYSQL パフォーマンスの上限に近づけることができます。
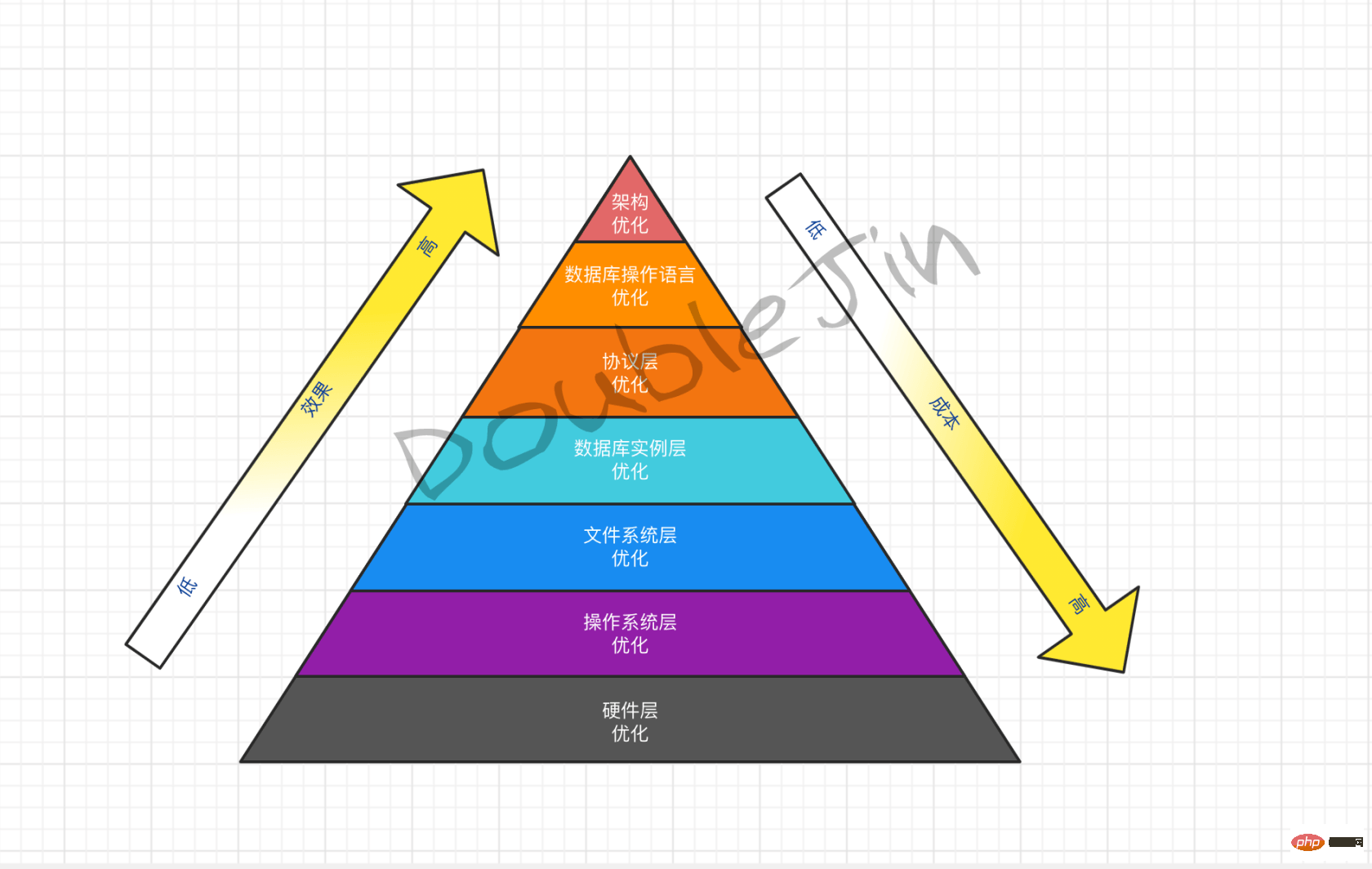
ハード最適化 - 資金能力
- フェーズ 1
-
改善ディスク I/O については、SSD ディスクを使用してみてください (品質の向上)
- メモリを増やし、クエリ キャッシュ スペースを増やします
- CPU コアの数を増やし、実行スレッドを増やします
フェーズ 2 -
自己構築の mysql をサービス プロバイダーの mysql service に置き換えます
- 組み込みの読み取りと書き込みの分離機能を有効にする
フェーズ 3 - サービス プロバイダーの mysql サービスは、クラウドネイティブの分散データベースに置き換えられます
- 組み込みの読み取りと書き込みの分離機能を有効にする
- 組み込みのサブテーブルを有効にするfunction
ソフト最適化 - クエリ - OLTP
OLTP は主に、次のような特定の種類のビジネス イベントの発生を記録するために使用されます。ユーザーの行動として、その行動が発生すると、システムはユーザーがいつ、どこで何かをしたかを記録し、そのようなデータの行 (または複数の行) が追加、削除、変更の形でデータベース内で更新されます。これには次のことが必要です。高いリアルタイム パフォーマンス、強力な安定性、データがタイムリーに正常に更新されることを保証する一般的なビジネス システムはすべて OLTP に属し、使用されるデータベースは MySlq、Oracle などのトランザクション データベースです。 OLTP の場合、クエリ速度とサービスの安定性の向上が最適化の核心です
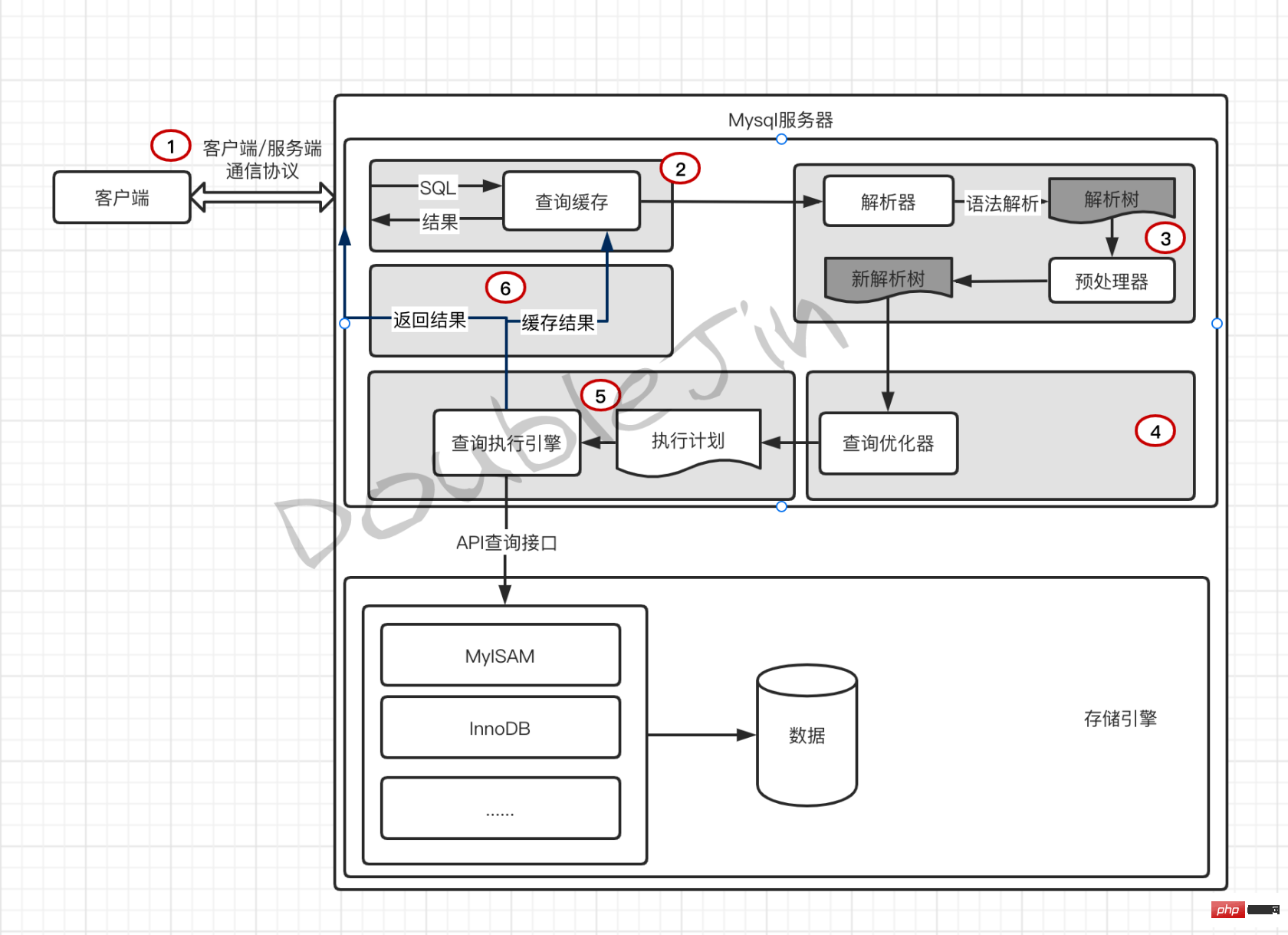
- スロー クエリ
- スロー クエリ ログを通じて効率の問題を伴う SQL を発見する
- 問題 SQL のトラブルシューティングの方向
- インデックス設計に問題があります
- SQL ステートメントに問題があります
- データベースのインデックス選択が間違っています
- 単一テーブルが大きいです
##具体的な分析の説明 -
- SQL実行比較率の表示
- #インデックスヒット状況の確認(要点)
- オプティマイザがインデックスを選択すると、インデックスのカーディナリティが参照されます。
- カーディナリティは MySQL によって自動的に維持および推定されるため、正確ではない可能性があります
- インデックスがヒットしない場合または、間違ったインデックスが使用されている場合は、オプティマイザ ステップに問題があります
- analyze でインデックス情報を再カウントし、ベース番号を再計算できます
- ##強制インデックス
force キーワードは、インデックスの使用を強制し、ビジネス コードにインデックスを強制的に指定できます - カバード インデックス - 最も理想的なヒット インデックス
カバード インデックスとは、次のことを意味します。クエリ ステートメントの実行から返される結果まで、同じインデックス (一意、通常、結合インデックスなど) が使用されます-
- カバリング インデックスによりバック テーブル クエリを削減できます
- データ クエリの場合複数のインデックスを使用しています。カバー インデックスではありません
- SQL ステートメントを最適化するか、結合インデックスを最適化できます。カバー インデックスを使用します
- #count() 関数
##count(index field) - インデックスを上書きできますが、フィールドが null かどうかを毎回判断する必要がありますtime - count (主キー) - 上記と同じ
- count(1) - インデックス ツリーのみをスキャンします。データ行を解析するプロセスはなく、理論的には高速ですが、それでも1 が null かどうかを判断します
- count(*) - MySQL は特に count(*) 関数を最適化し、インデックス ツリー内のデータ数を直接返すようにします。最適
- ORDER BY
- 追加の並べ替えを最小限に抑え、where 条件を指定します
where ステートメントと ORDER BY ステートメントの組み合わせは、左端のプレフィックスを満たします - 最も効率的 - インデックス カバレッジ (少数のシナリオ、遭遇する可能性は低い)
- インデックス カバレッジでは、中間結果セットの生成をスキップし、クエリ結果を直接出力できます
- ORDER フィールドにはインデックスが付けられ、WHERE 条件および出力と一致している必要があります。内容は次のとおりです。すべて同じインデックス内にある
- ページング クエリ
まずインデックスをカバーする方法を見つけます
必要なものを見つけます最初のデータの ID。テーブルに戻って最終結果セットを取得します。-
- インデックス プッシュダウン
- KEY
( - store_id)
- ,
- guide_id
) BTREEEselect * from table where store_id in (1,2) and guide_id = 3;MySQL5.6 より前では、次のことが必要です。インデックスを使用して (1,2) の store_id をクエリし、すべてのテーブルを追加して film_id = 3MySQL5.6 を確認します。インデックスで読み取れる場合は、インデックス フィルタリング - # を直接使用します。
- ##緩いインデックス スキャン
- KEY store_id_guide_id
store_id - guide_id
- ,
- guide_id
- ) BTREE
を使用select film_id from table where guide_id = 3緩やかなインデックス スキャンは「左手の原則」を破り、主要な兄弟を失う問題を解決できます - 結合インデックスの効率よりも効率が低くなります
- 関数操作
- インデックス フィールドに対して関数操作を実行すると、オプティマイザはインデックスを放棄します。
- ) BTREE
- mysql 関数を置き換えるためにサーバー側ロジックの使用を最適化します
- #単一テーブルのサイズが大きすぎます
- mysql をアップグレードすると、異なる mysql ソフトウェアがサポートできる単一テーブルのサイズが異なります。私の現在の経験に基づくと、単一テーブルの場合にヒット インデックスをクエリするのは問題ありません。 Alibaba Cloudのテーブルのpolardbクラスタバージョンは2億(高優先)
- データ決済 - パイプラインデータなどの決済が可能 ある時点での決済により最新の値を取得し、決済されたフローをバックアップテーブル(中優先度)
ホットデータとコールドデータの分離 - クエリの頻度に応じて決着できないデータを区別し、頻度が低い クエリを別のテーブルに転送し、エントリを区別するビジネス上のクエリのポイント (優先度中) - 分散データベースのテーブル分割 - オーダーによる分散データベースのテーブル分割機能を有効にし、分散データベース コンポーネントの管理はテーブル分割後の挿入とクエリ (中)
- テーブル分割を実装するコード - PHP や GO のほとんどのフレームワーク ORM で分割した後、特定のルールに従って 1 つのテーブルを複数のテーブルに分割しますフレームワーク ORM に特定の変更を加える必要があります。 JAVA にはネイティブ サポートがあります。プロジェクトの初期段階で検討することをお勧めします。後ほど難しくなります (優先度が低くなります)
- ソフト最適化 - 書き込み更新削除
ロック
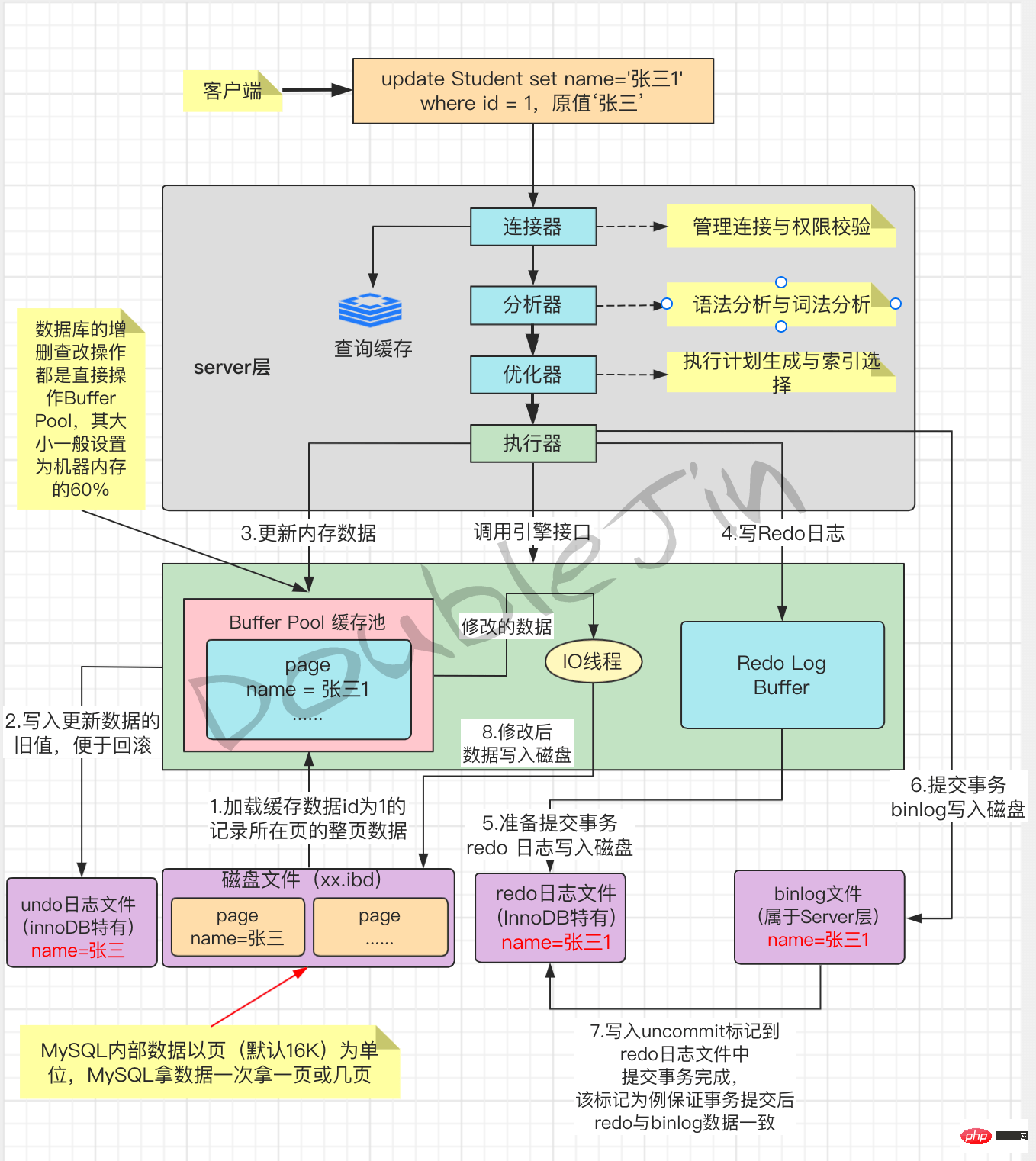
- ##グローバル ロック##fromgoogle/baidu
- ##テーブル レベルのロックは、テーブル ロック (データ ロック) とメタデータ ロックに分けられます
-
テーブル ロック
- autogoogle/baidu
メタデータ ロック -
自google/baidu
- ##行ロックはデータ行をロックし、共有ロックと排他ロックに分けられます
- Google/baidu
デッドロックの解決策 - パラメータ構成
- innodb_lock_wait_timeout パラメータを調整します
- デフォルトは 50 秒です。つまり、50 秒待機してもロックが取得されない場合、現在のステートメントがレポートします。エラー
- 待機時間が長くなった場合は、このパラメータを適切に短くすることができます
- アクティブなデッドロック検出: innodb_deadlock_detect
- コストの低いトランザクションをロールバックします。デッドロックが見つかりました
- デフォルトで有効になります
- innodb_lock_wait_timeout パラメータを調整します
- 必要ない場合はトランザクションを開かないでください
- 配置してみてくださいロックされた行の数を減らすために、トランザクションの外でクエリを実行します。
- トランザクション時間が長すぎるため、トランザクション内で http リクエストをトリガーしないでください。 #トランザクション ステータスを積極的に確認してください。
- パラメータ構成
検索ビジネス
- 検索行数は 100,000 未満 - mysql を運ぶのは難しい
- mysql の CPU、IO、およびメモリ ハードウェア
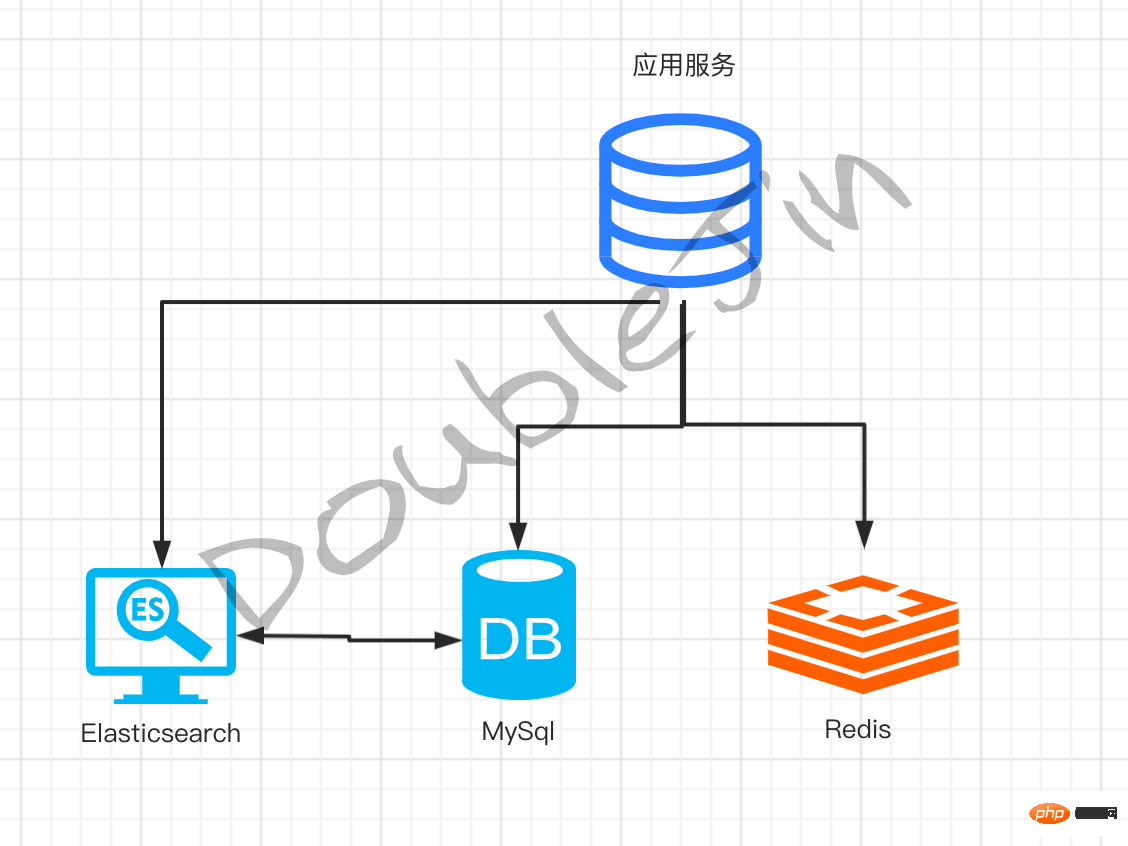
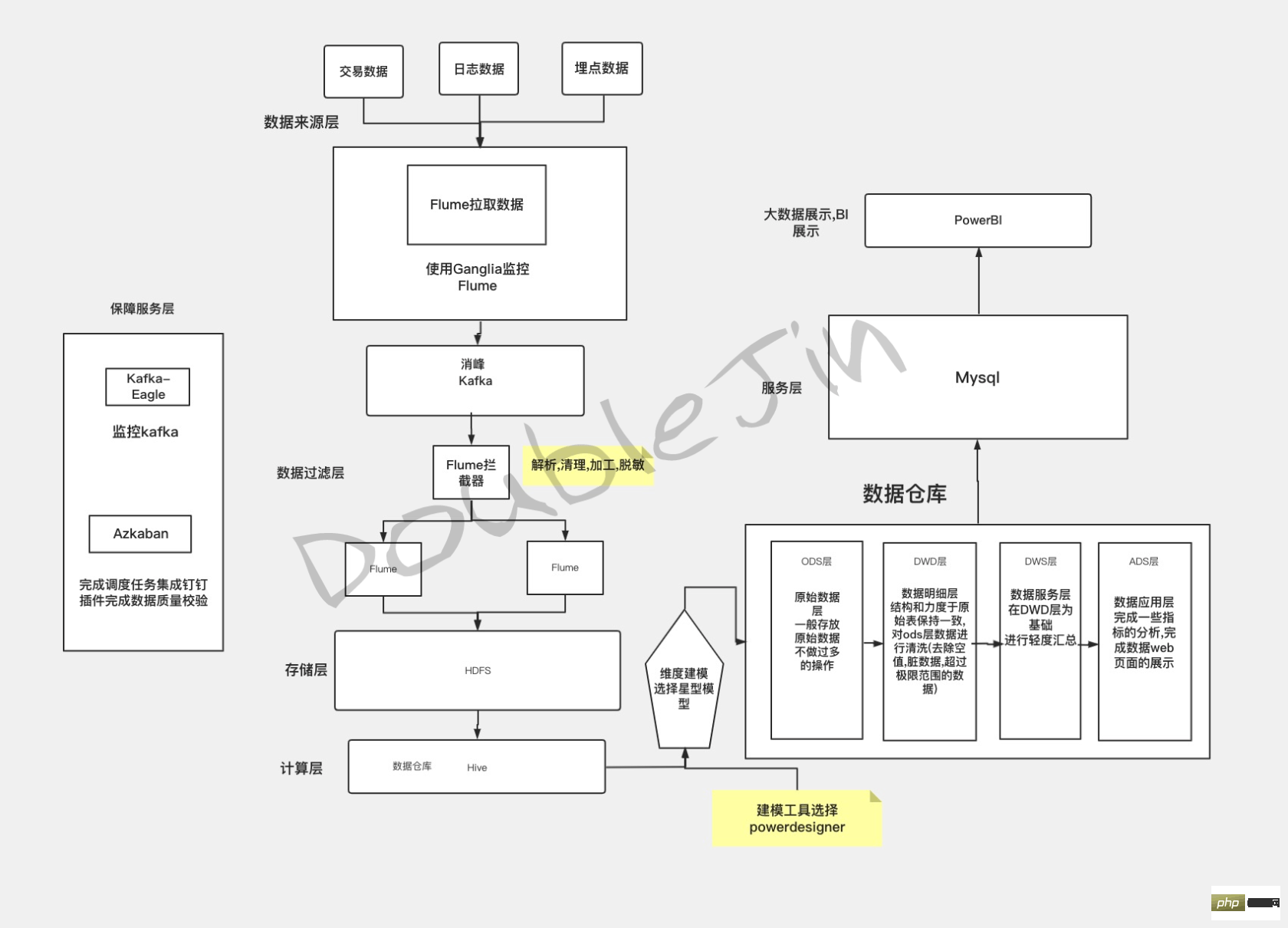
検索行数は 100,000 以上 - Elasticsearch の概要
Elasticsearchの転置インデックスは全文検索に適していますが、データ構造の柔軟性に欠けます。 #データ同期
- ビジネス コードがデータを変更すると、同時に Elasticsearch に同期されます
- Canel サブスクリプションの mysql ログが同期をトリガーします
- は、同じフィールドを持つドキュメントのリストで構成されます。mysql のテーブルに似ています。
- フィールド タイプが設定されると、変更は禁止され、新しいものになります。フィールドは許可されます
- Specific このメソッドは独自の google/baidu
- es に保存されたユーザーのデータ ドキュメント - 次のようなものです。 mysql
- の行はメタデータと Json オブジェクトの構成で構成されます
- メタデータと Json オブジェクトの詳細は google/baidu
- by Google/baidu
- fromgoogle/baidu
- ##Elasticsearch - 集計分析
自google/baidu
OLAP を使用OLTP トランザクション処理シナリオに関連したデータの意思決定分析用です。これはビッグ データ分析で使用されるオフライン データ ウェアハウスのアイデアであり、特定のテクノロジ スタックではありません。ソリューションが OLAP 分析と処理のアイデアを具体化できる場合、解決策はOLAPです。
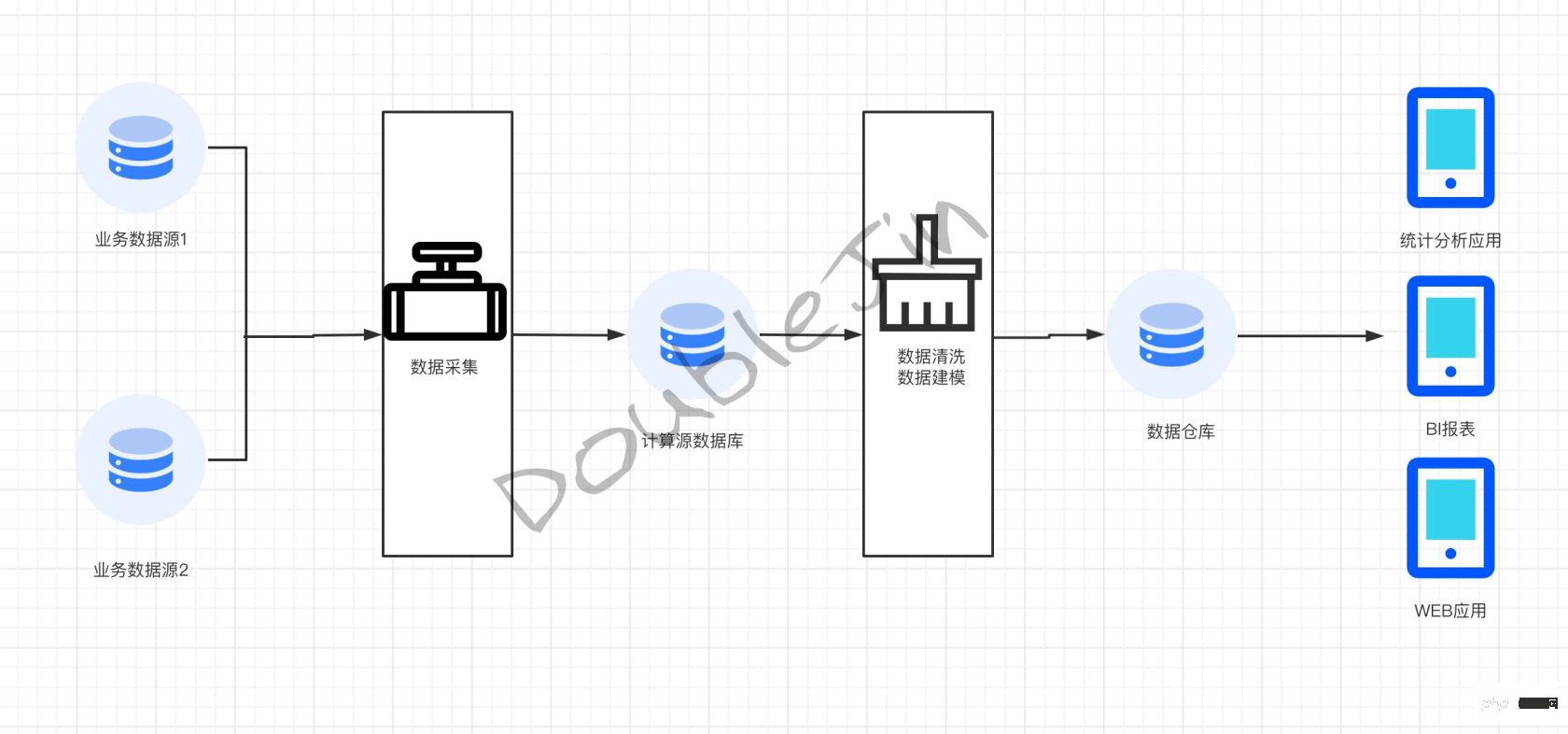
初期のデータ ウェアハウス構築とは、主に、意思決定分析の要件に従って、ERP、CRM、SCM、その他のデータなどのエンタープライズ ビジネス データベースをモデル化し、データ ウェアハウス エンジンに要約することを指します。そのアプリケーションは主にレポート作成です。経営者や事業担当者の意思決定(中長期的な戦略的意思決定)を支援することを目的としています。 IT技術のインターネット化やモビリティ化に伴い、データソースはますます豊富になり、Webサイトのログ、IoTデバイスのデータ、APPの埋め込みデータなど、元のビジネスデータベースを基にした非構造化データが出現します。これは、以前の構造化データよりも数桁大きくなっています。 OLAP が直面するビジネスがどのように変化しても、分析フィールドの決定 -> ビジネス データをコンピューティング ライブラリに同期 -> データ クリーニング モデリング -> データベースとの同期データ ウェアハウス - > 外部への公開計算元データベースはデータ クリーニングに特化して使用されており、データ クリーニング中に業務データベースのパフォーマンスへの影響を避けることが目的です。業務やディメンションに応じて計算元データベース内のデータをクリーンアップすることで、データの有用性と再利用性が向上し、最終的なリアルタイムの詳細データが取得され、データ ウェアハウスに転送され、データ ウェアハウスが提供する最終的な意思決定の分析データ。 デモプラン本番プラン
各リンクのソフトウェアは同じ機能を使用できますソフトウェアがチームの最も信頼できるソフトウェア実装ソリューションに置き換えられる場合、そのソリューションは OLAP です。
概要最適化は、能力を段階的に蓄積し、複数回の繰り返しを行う、現実的なものでなければならず、一夜にして達成できるものではありません。独自の基盤、ビジネス シナリオ、将来の開発の期待に基づいて、複数回の反復を実施します。
反復の原則は、まず単一のソフトウェア サービスのソフト最適化とハード最適化を通じてソフトウェアの効率を向上させることです。将来の開発期待に基づいて、最適化コストが利益よりも低い場合は、成熟したサービスを参照してください。市場にあるソリューションを参照し、そのソリューションに従う 組み合わせたイノベーションのために必要に応じて新しいソフトウェアを導入し、ブラインドコピーを避ける 有機的な統合を通じてのみ、1 1>2、2 1>3 の効果を達成できる 参照されたソフトウェアがボトルネックに遭遇した場合、このプロセスを繰り返します。 お読みいただきありがとうございます。以上が記事の内容です。内容で提案されている最適化ポイントや解決策は、必ずしも最適解であるとは限りません。個人の業務におけるベストプラクティスです。さまざまな意見がありますが、それについて話し合うことは歓迎です。
以上が共有が高く評価されました: 本番環境に沿った MySQL 最適化のアイデアの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。