
Redis 整数セットはダウングレードできませんか?なぜ?

- 醉折花枝作酒筹転載
- 2021-07-28 17:46:472364ブラウズ
redis はカプセル化されたオブジェクトを 5 つだけ外部に提供するため、整数コレクションについて聞いたことがない学生もいると思います。前回は、redis の内部構造から、redis の 3 つのデータ構造 (List、Hash、Zset) を分析しました。今日は、設定されたデータ構造が内部的にどのように保存されているかを分析します。
基本構造
src/t_set.c でそのようなコードが見つかりました
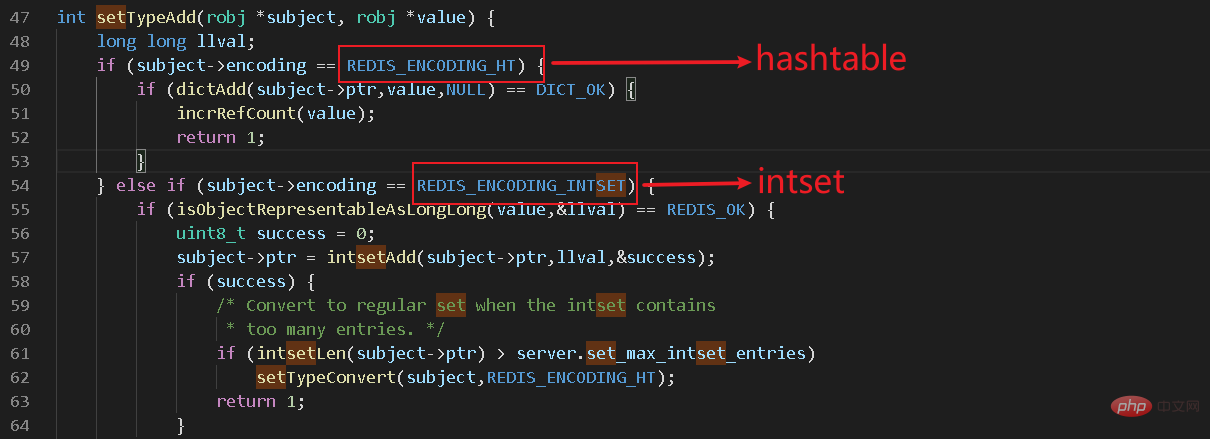
これから、set 内にあることがわかります。これは、hashtable intset という 2 つのデータ構造で構成されます。その他のredisの内部構造については、【redisコラム】で具体的に紹介しています。 Hashtable は今日の主役ではありませんが、今日はまず intset (一般に整数セットとして知られています) を分析します。
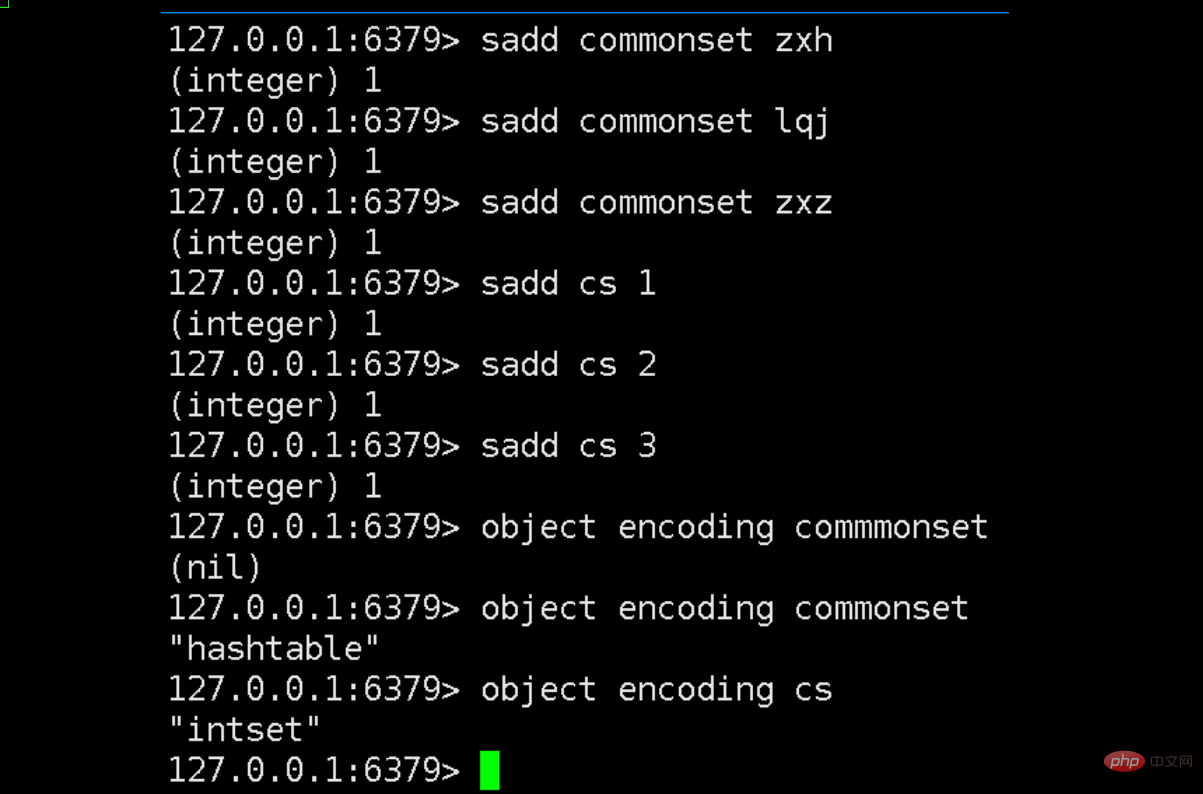
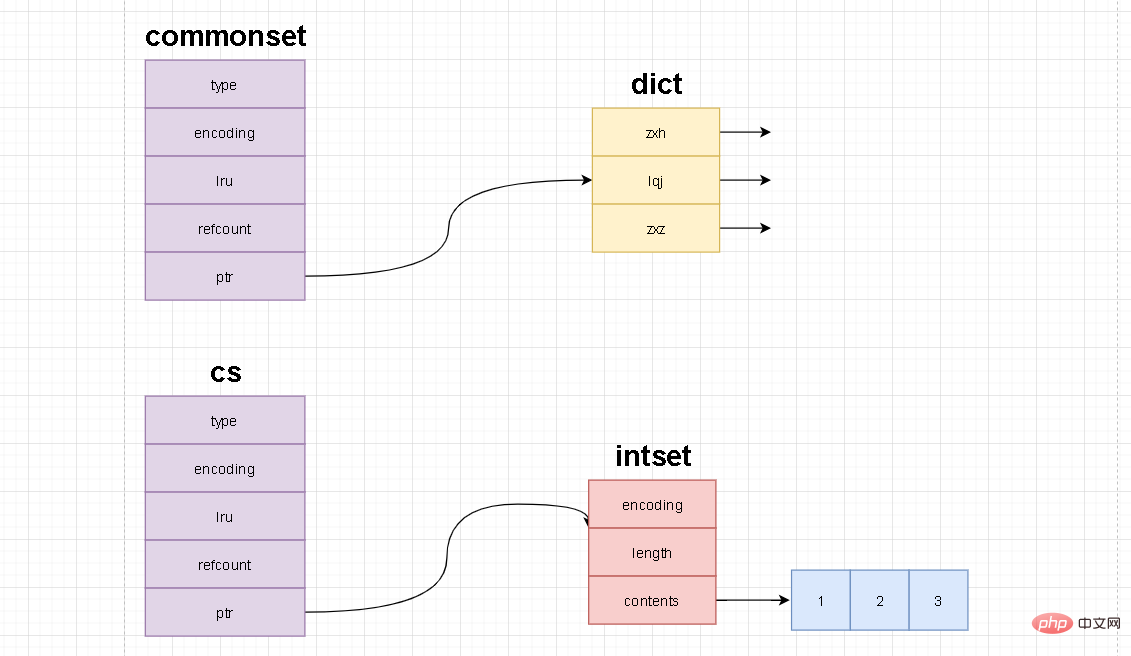
上の図からわかるように、[commonset] と [cs] という 2 つのセット コレクションを構築しました。前者は文字列を格納し、後者は数値を格納します。
次の 2 つのコレクションの基礎となるデータ構造をオブジェクト エンコード キーを通じて調べたところ、1 つはハッシュテーブルで、もう 1 つは intset であることがわかりました。これは、上記のセットの基本構造の説明も検証します。
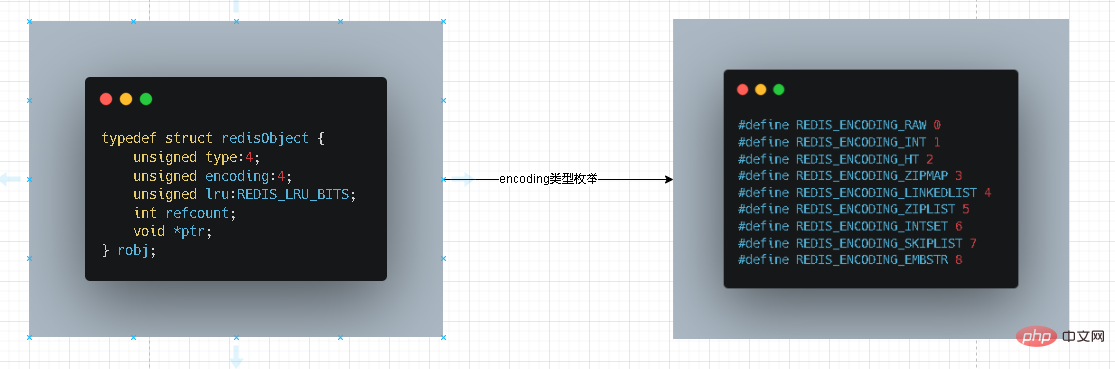
redis で外部的に提供される 5 つの主要な型は、実際には redisobject と呼ばれる redis の抽象オブジェクトです。 Redis の内部データ構造は内部的にマップされます
 intset を使用する場合
intset を使用する場合
#数値である限り、intset 構造体を使用して格納されると単純に考えてください。顔。実際には、そうではありません。
#次の 2 つの条件を同時に満たす必要があります:
intset
画像はそれを非常に明確に示しています. intset のエンコーディングには、コンテンツ ストレージのデータ型を表す 3 つの値があります。ここで疑問に思う人もいるかもしれませんが、コンテンツの型は int8_t ではないでしょうか?なぜエンコードが必要なのでしょうか?ここでのソース コードの追跡は int8_t とは何の関係もありません。デフォルトのデータ型は int16_t です。長さについてはここで詳しく説明する必要はありませんが、コンテンツ要素の数はコンテンツ配列の長さを表すものではないことに注意してください。 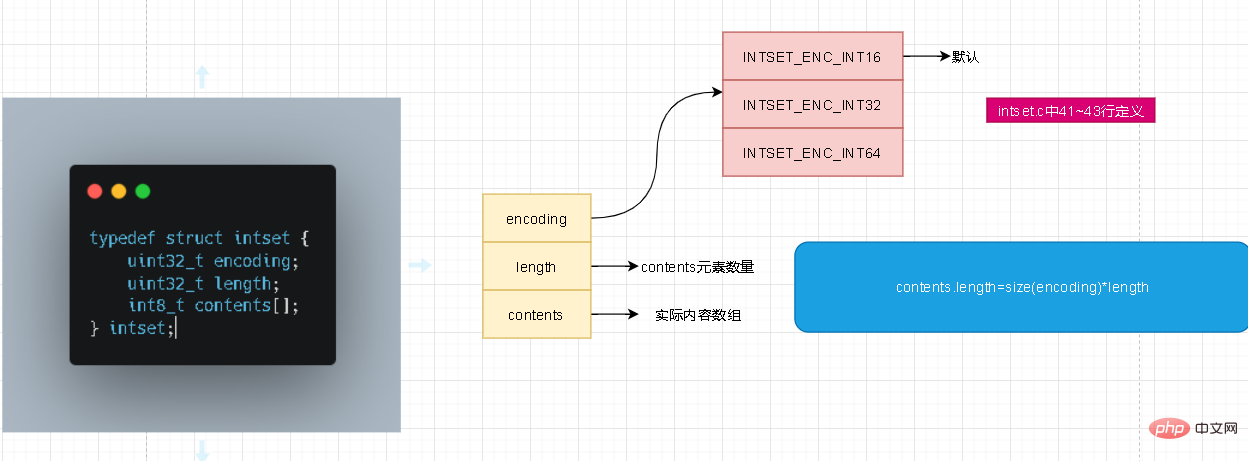
\[-2^{7} \sim 2^{7}-1 \\
つまり\\ です
-128 \sim 127
\]
要素を追加
sadd juejin -123 sadd juejin -6 sadd juejin 12 sadd juejin 56 sadd juejin 321juejin 中のキーは intset です。
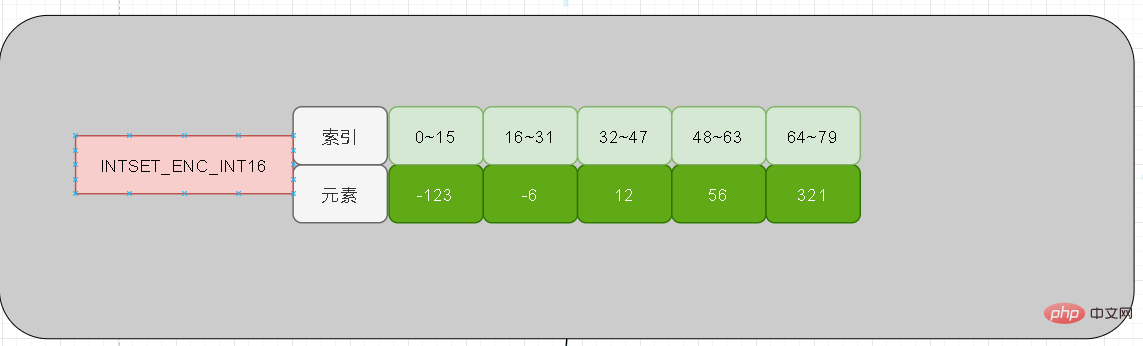
上記では 5 つの要素を追加しましたが、これら 5 つの要素の長さはすべて 16 以内です。したがって、現在の intset のエンコーディング = INTSET_ENC_INT16 となります。内容的には-123が上位16位を占めています。 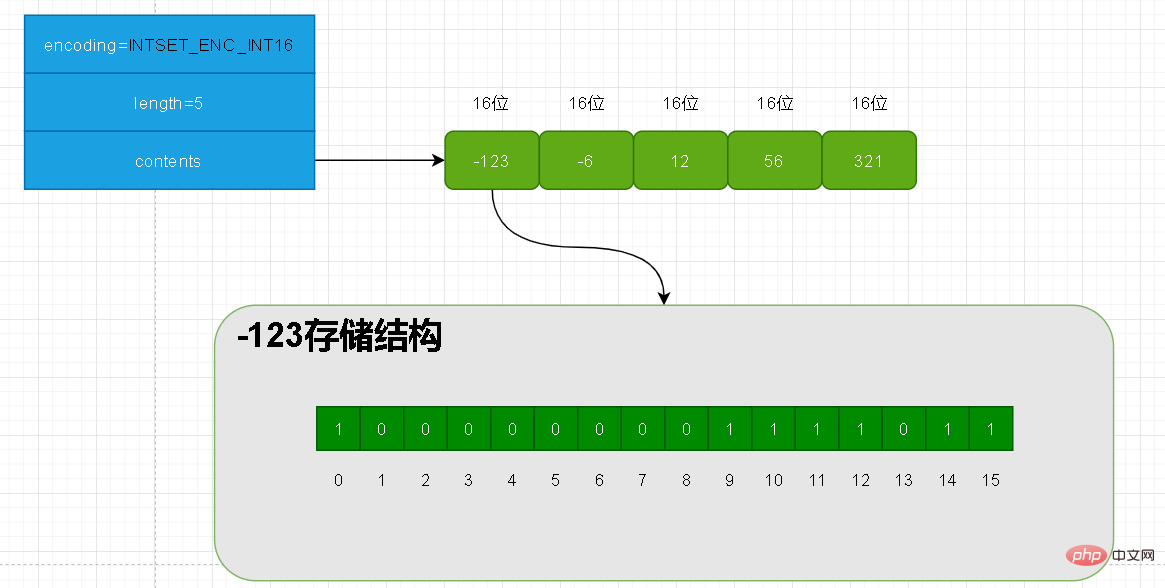
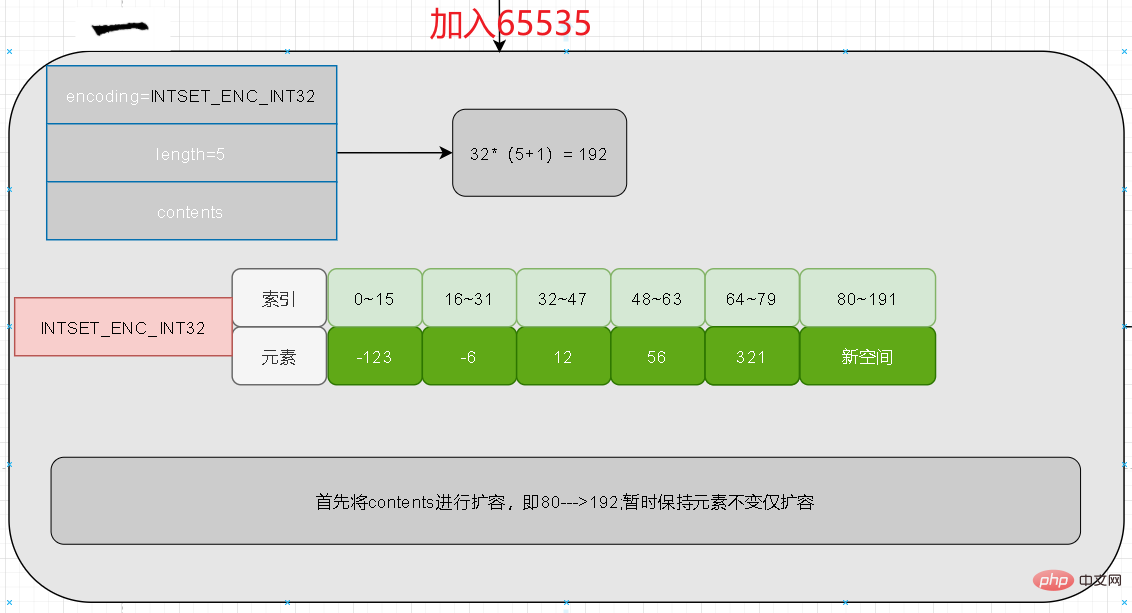
上記の質問について検討したことがあるか、遭遇したことがあるかはわかりません。 Intset のデフォルトは、上で追加した 5 つの要素と同様に int16 ビットです。このとき、追加する 6 番目の要素は 65535 (32 ビット) です。では、16 ビットの長さがストレージに十分でない場合、このとき intset は何をするのでしょうか? 
答えは絶対に不可能です。まず第一に、直接追加では配列要素の順序を保証できません。次に、最初の 5 つがそれぞれ 16 ビットで、6 つ目が 32 ビットの場合、intset 構造体にはマークする追加のフィールドはありません。つまり、解析中に 16 ビットと 32 ビットのどちらを解析するべきかを判断することはできません。これは、最初にコンテンツ全体を展開し、次にデータ
を追加することを意味します。要素数は 6、各占有数は 32 なので、コンテンツの長さは 32*6=192 となります。現時点では、コンテンツの最初の 80 ビットは変更されません。
十分なスペースが確保された後、古いデータは移動されます。ここでは元の配列の末尾から移動を開始します。移動する前に、新しい配列のソート位置を明確にする必要があります。
今回は、まず 321 を比較して、新しい配列でのランキングが 5 位であることを確認し、その後、新しいコンテンツで 128 ~ 159 の範囲を占めることになります。
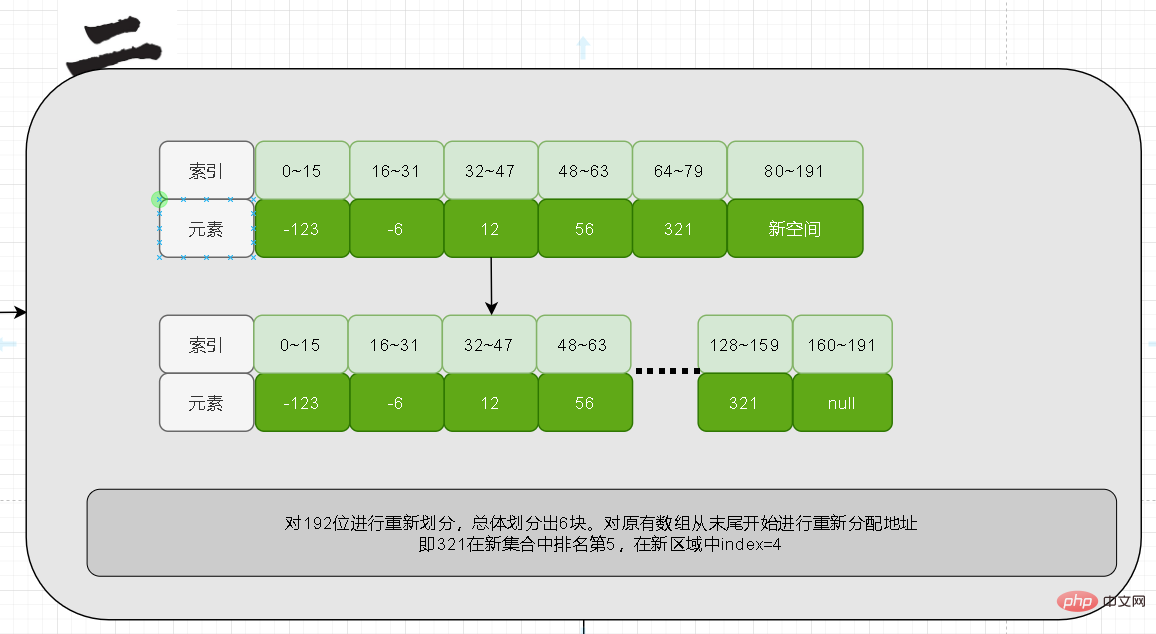 最後に、最初の 5 つの要素が移動されます。
最後に、最初の 5 つの要素が移動されます。
#最後に、新しく追加した要素を入力します。アップグレードが発生する場合は、新しい要素の長さが元の長さよりも長いことが原因であるはずです。その場合、その値は新しい配列の両端になければなりません。負の数値は左端、正の数値は右端です。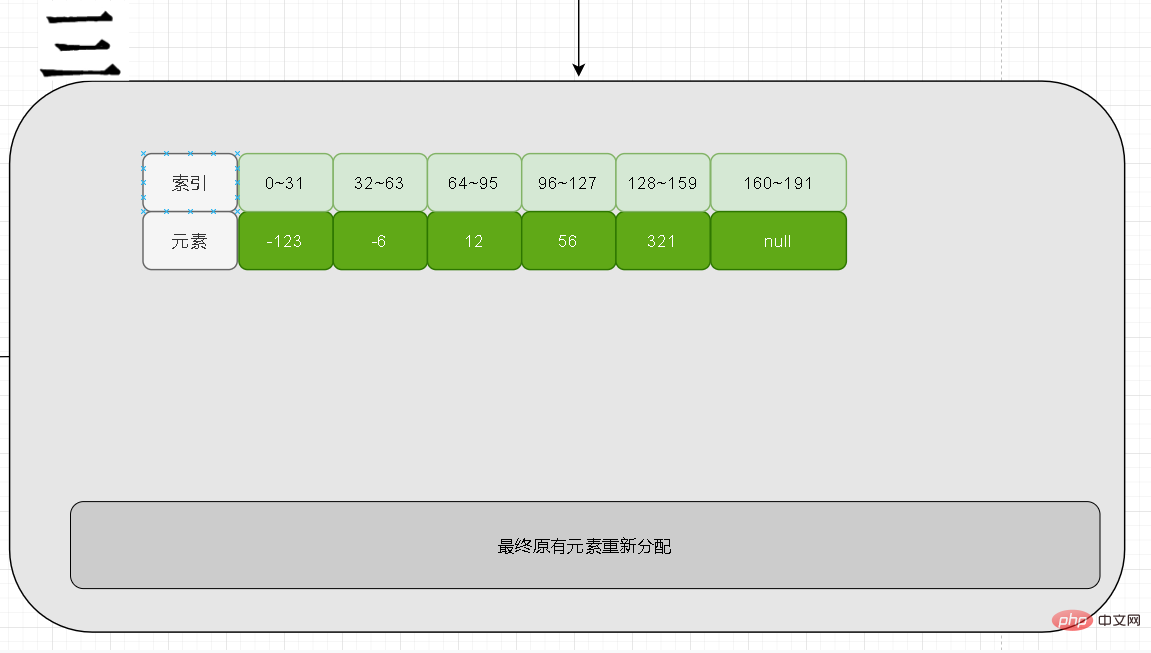
ダウングレード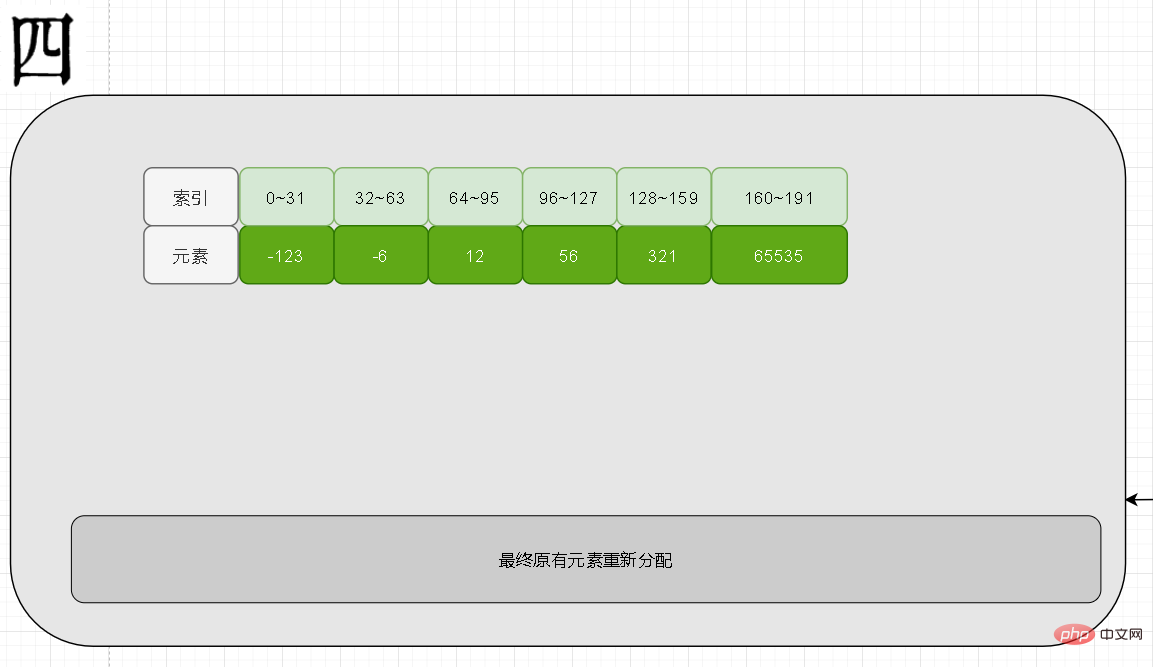

以上がRedis 整数セットはダウングレードできませんか?なぜ?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。