
ホームページ >バックエンド開発 >Python チュートリアル >Python Webクローラーの手順は何ですか
Python Webクローラーの手順は何ですか

- coldplay.xixiオリジナル
- 2021-03-10 16:57:0328776ブラウズ
Python Web クローラーの手順: まず、必要なライブラリを準備してクローラー スケジューラーを作成し、次に URL マネージャーと Web ページ ダウンローダーを作成し、次に Web ページ パーサーを作成し、最後に Web ページ アウトプッターを作成します。

このチュートリアルの動作環境: Windows 7 システム、Python バージョン 3.9、DELL G3 コンピューター。
Python Web クローラーの手順
(1) 必要なライブラリを準備します
BeautifulSoup ( Web ページ解析) は、ダウンロードされた Web ページを解析するために使用されるオープン ソース ライブラリです。PyCharm コンパイル環境を使用しているため、オープン ソース ライブラリを直接ダウンロードできます。
手順は次のとおりです。
[ファイル] -> [設定] を選択します。
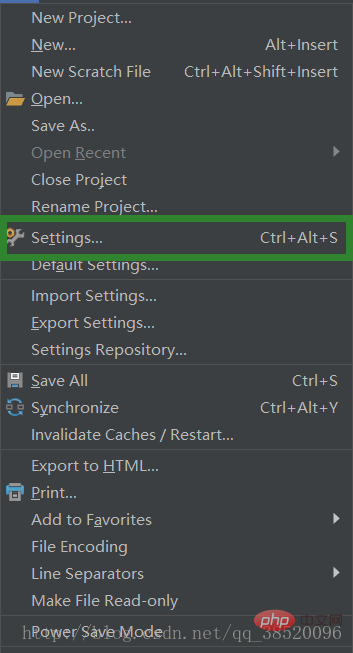
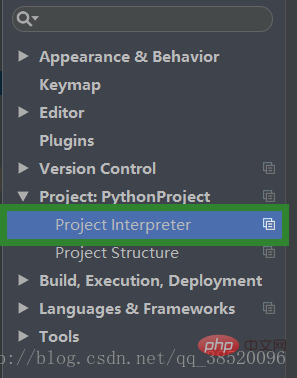
Project:PythonProject の下にあるプロジェクト インタープリタを開きます。
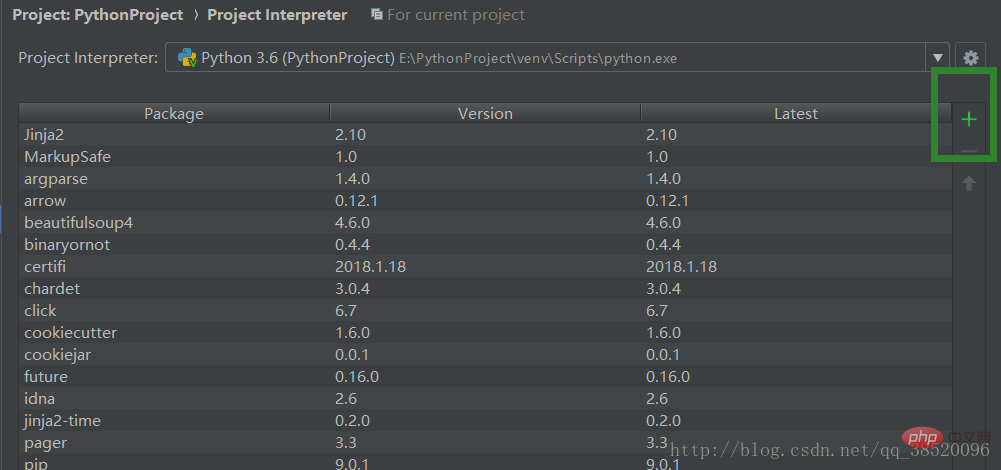
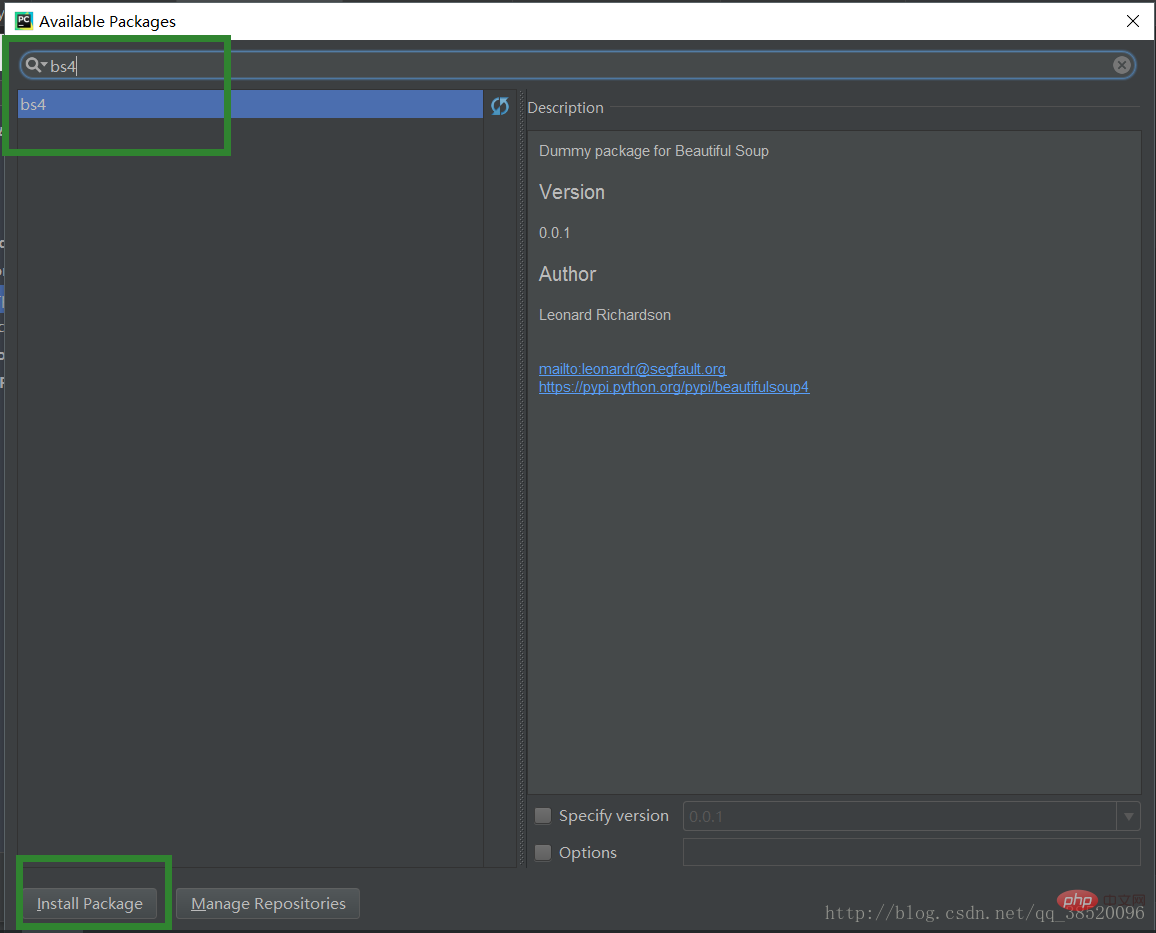
(2) クローラー スケジューラを作成する
ここでの bike_spider は、プロジェクト名によって導入された 4 つのクラスであり、次の 4 つのセクションに対応します。コード URL マネージャー、URL ダウンローダー、URL パーサー、URL 出力ツール。# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3) URL マネージャーの書き込み
クロールされた URL とクロールされていない URL を別々に保存します。繰り返します。すでにクロールされている Web ページをいくつかクロールします。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4) Web ページ ダウンローダーを作成する
ネットワーク リクエストを通じてページをダウンロードする# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5) Web ページ パーサーを作成する
Web ページを解析するときは、クエリしたいコンテンツがどのような特性を持っているかを知る必要があります。Web ページを開いて右クリックし、要素を検査して理解することができます。問い合わせているコンテンツの共通点。# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("p", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6) Web ページ出力ツールを作成する
出力形式は多数ありますが、ここでは HTML 形式で出力することを選択します。 HTMLページ。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("<html>")
fout.write("<meta charset='utf-8'>")
fout.write("<body>")
# 以表格输出
fout.write("<table>")
for data in self.datas:
# 一行
fout.write("<tr>")
# 每个单元行的内容
fout.write("<td>%s</td>" % data["url"])
fout.write("<td>%s</td>" % data["title"])
fout.write("<td>%s</td>" % data["summary"])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
# 输出完毕后一定要关闭输出器
fout.close()
関連する無料学習の推奨事項: Python ビデオ チュートリアル
以上がPython Webクローラーの手順は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。