
ホームページ >バックエンド開発 >Python チュートリアル >Python クローラー: Baidu の写真を好きなようにクロールします
Python クローラー: Baidu の写真を好きなようにクロールします

- coldplay.xixi転載
- 2021-03-05 10:04:576245ブラウズ

#記事ディレクトリ
- 1. 序文
- 2. 必要なライブラリ
- #3. 実装プロセス
- #1. ダウンロード リンクの分析
- #2. コード分析
- 3 、完全なコード
4. ブロガーのスピーチ
(無料学習の推奨事項:
python ビデオ チュートリアル)1. はじめに
たくさんクロールしましたWeb ページのコンテンツには、小説、写真などが含まれます。今日は動的 Web ページをクロールしてみます。ご存知のとおり、Baidu Pictures は動的な Web ページです。それなら、急げ!急ぐ! !急ぐ! ! !
2. インポートする必要があるライブラリ
import requestsimport jsonimport os3. 実装プロセス
1. ダウンロード リンクの分析
まず、Baidu を開いてコンテンツを検索します。ここでの検索は男神 (自身
) ——Peng Yuyan です。次に、パケット キャプチャ ツールを開き、
XHR オプションを選択し、
オプションを選択し、
Ctrl R を押します。マウスをスライドさせると、右側にデータ パケットが次々と表示されることがわかります。 。
(ここではあまりスライドはありません。スライドが多すぎるため、最初に記録された GIF は 5M を超えていました。) 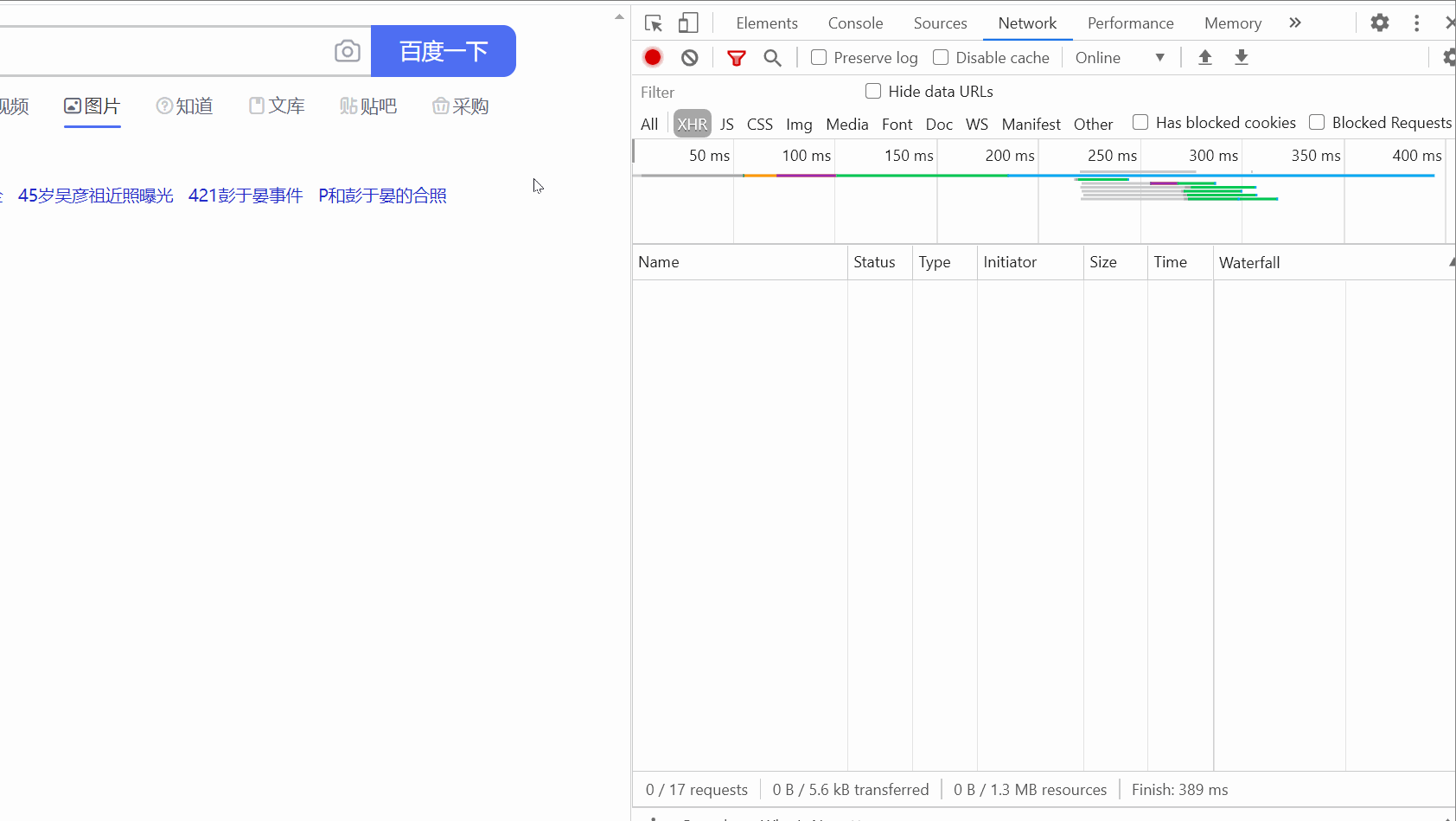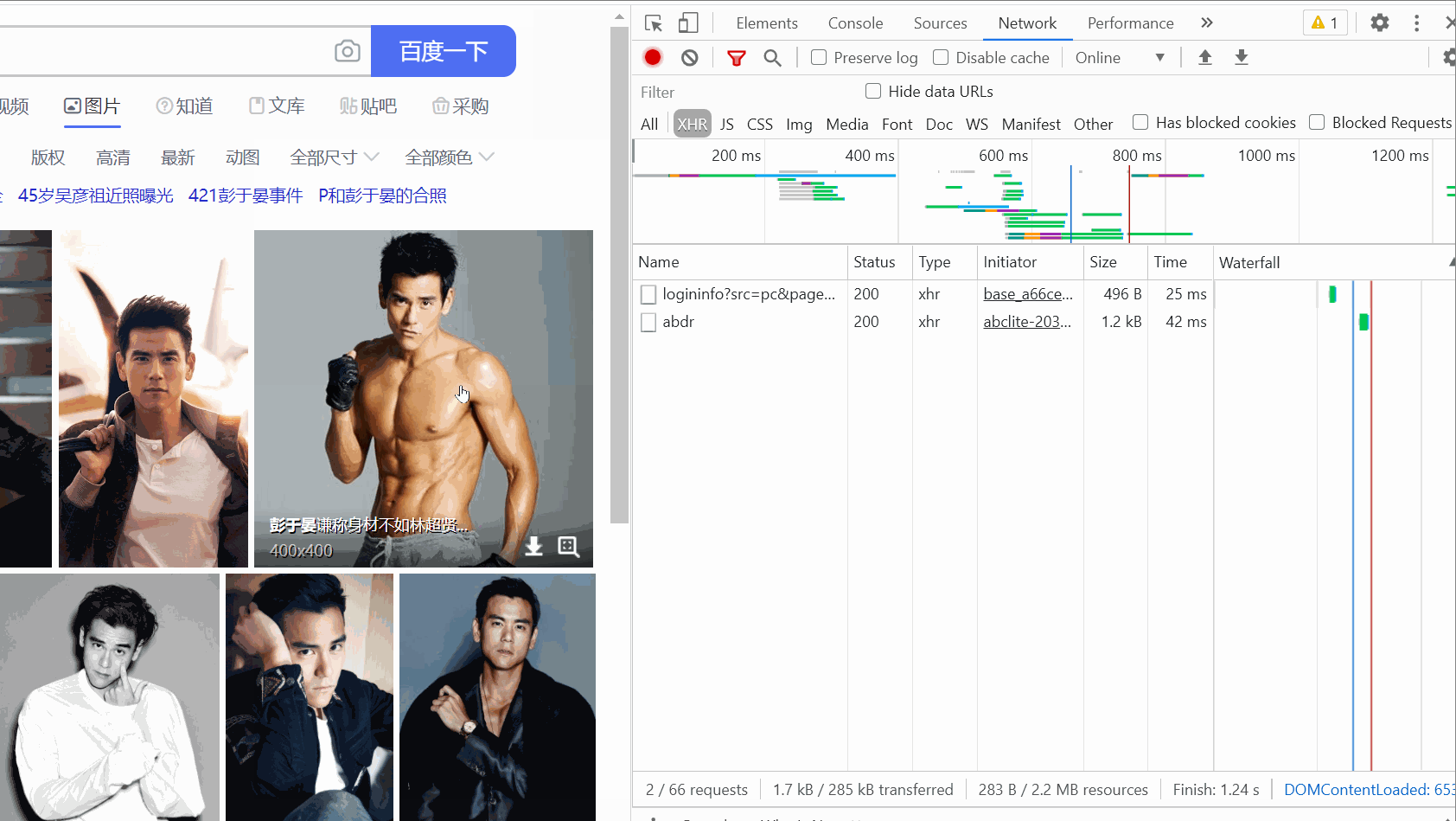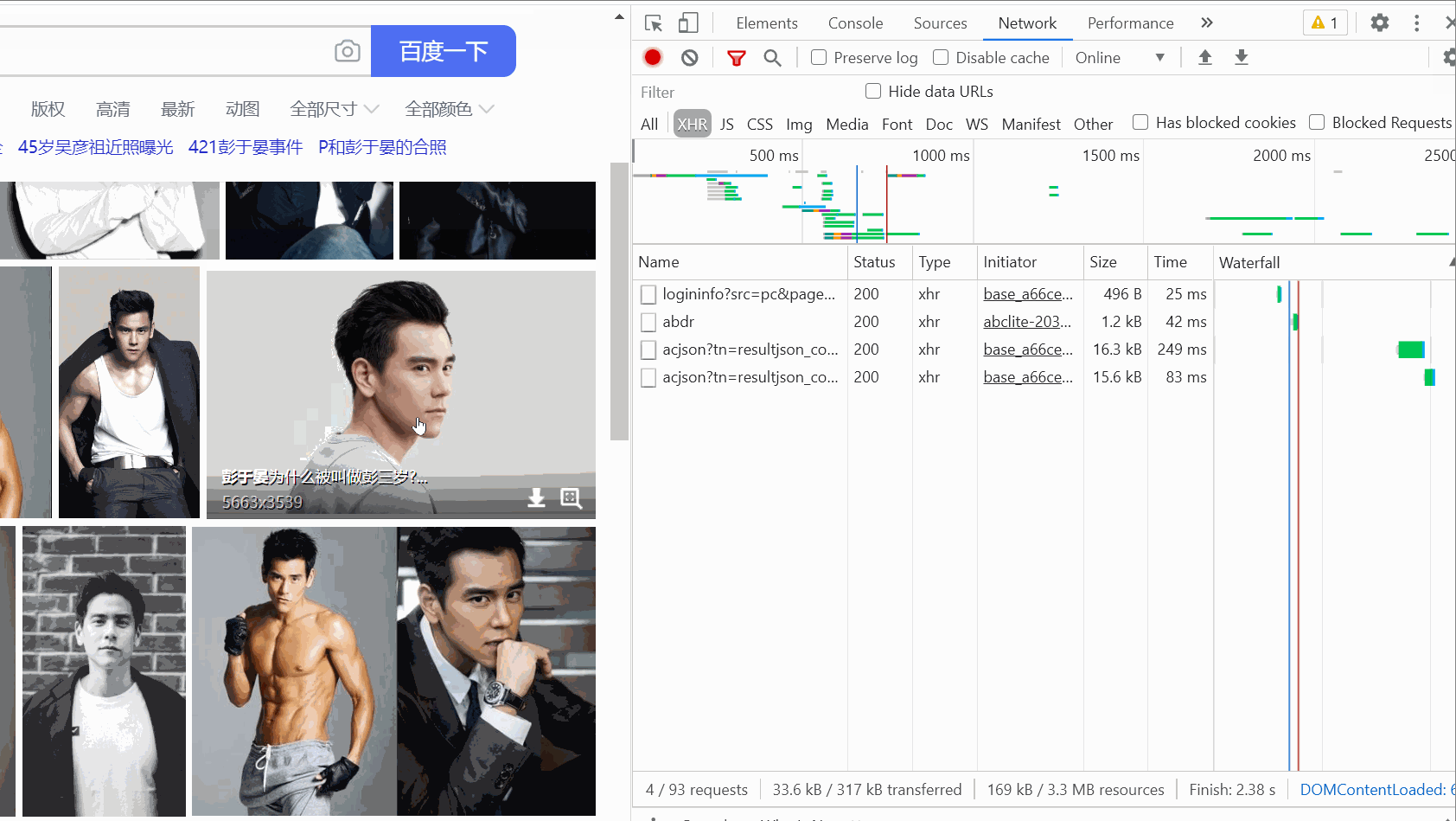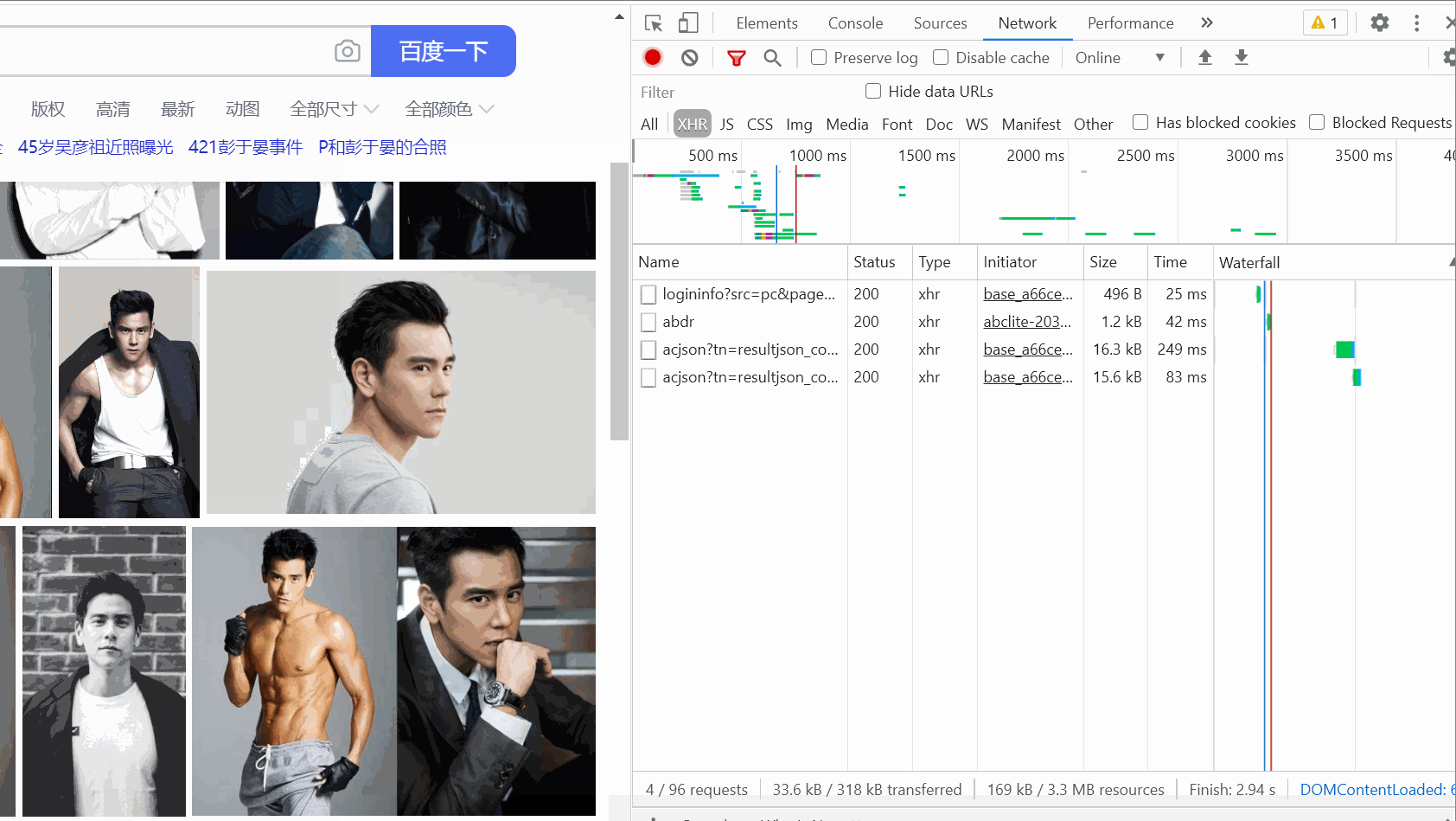
次に、パッケージを作成し、図に示すようにヘッダーを表示します。
インターセプト後、後で使用する URL としてメモ帳に貼り付けます。 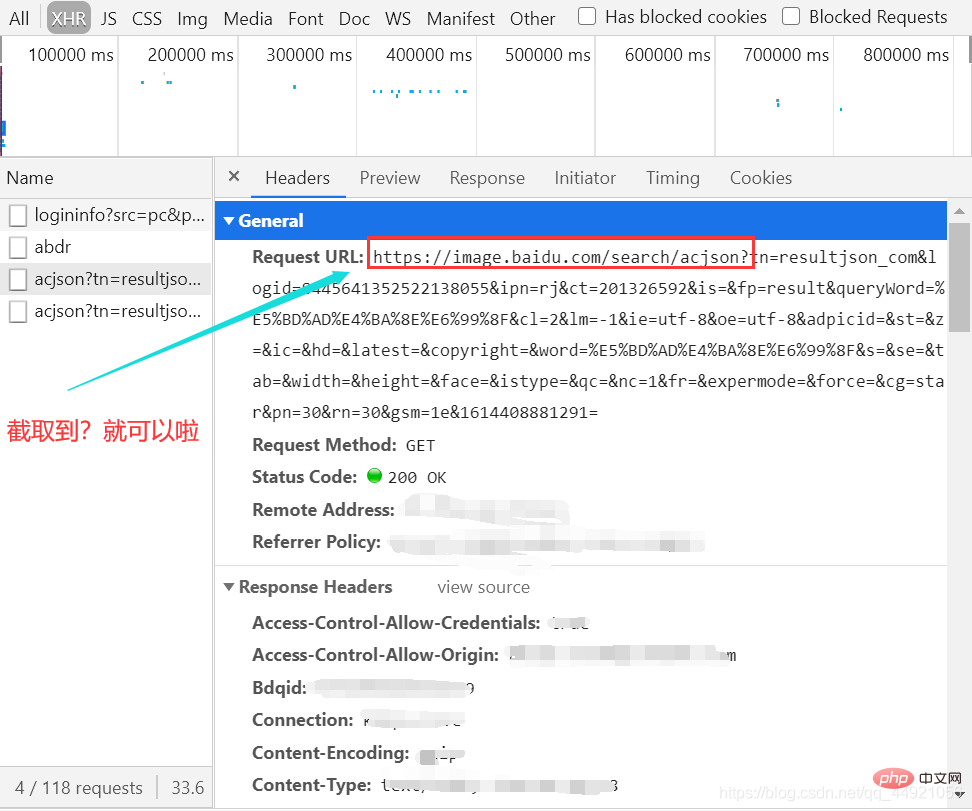
ここには非常に多くのパラメータがあり、どれを無視してよいかわかりません。次の記事でそれらをすべてコピーするだけです。詳細については、次の記事を参照してください。 
これで、直接観察できるコンテンツは終わりです。次に、コードを使って、別の世界への扉を開いてください。
以上です。
2. コード分析まず、上記の「その他のパラメータ
」をグループ化します。自分で行う場合は、独自の「その他のパラメータ
」をコピーすることをお勧めします。その後、まず抽出を試み、エンコード形式を 'utf-8'
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '彭于晏',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '彭于晏',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': '30',
'rn': '30',
'gsm': '1e',
}
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text print(response)
に変更します。実行結果は次のとおりです。 かなり乱雑ですね。大丈夫です。まとめましょう。  上記を踏まえて追記:
上記を踏まえて追記:
# 把字符串转换成json数据 data_s = json.loads(response) print(data_s)実行結果は以下の通り:
上記と比べるとかなり分かりやすくなりましたが、なぜ毛織物なのか?なぜなら、その印刷形式は私たちが見るのに不便だからです。 
これには 2 つの解決策があります。
#①pprint ライブラリをインポートし、
pprint.pprint(data_s) と入力すると、以下に示すように印刷できます
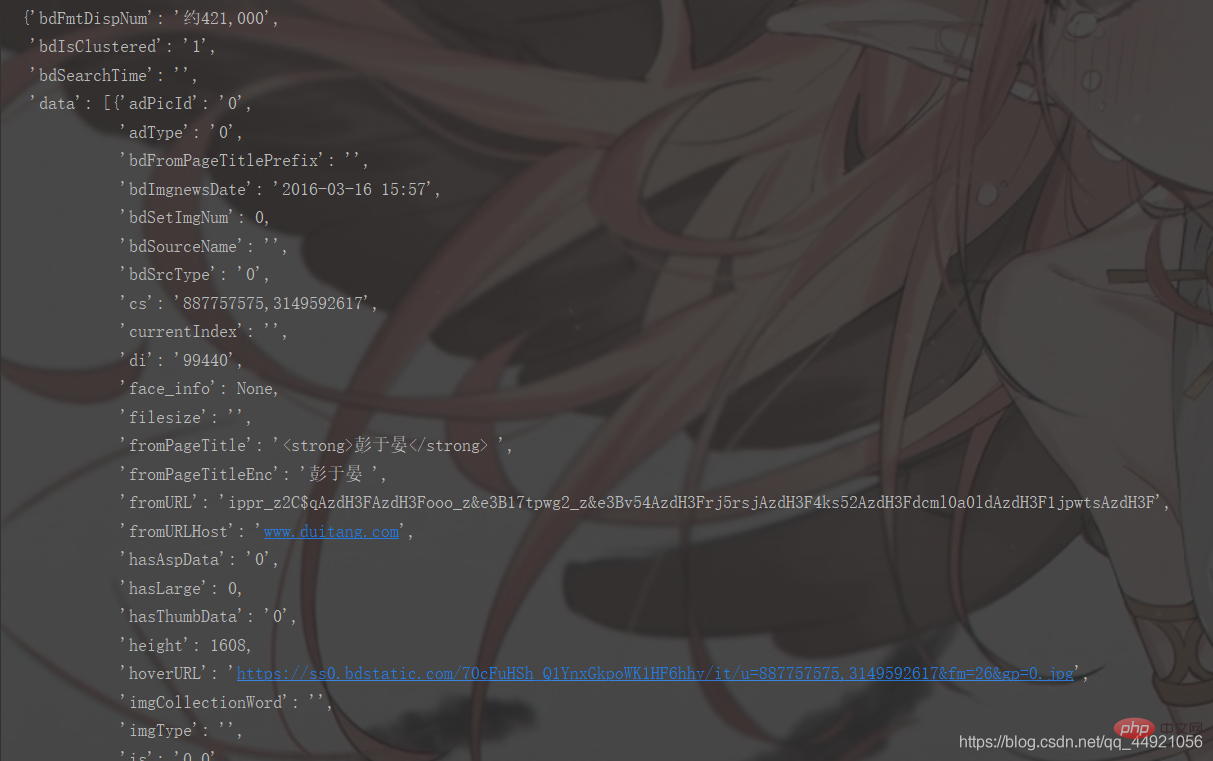
前の手順を解決すると、必要なデータが得られることがわかります。すべては
data 内部にあります!
内部にあります!
それから抽出してください! <pre class="brush:php;toolbar:false"> a = data_s["data"]
for i in range(len(a)-1): # -1是为了去掉上面那个空数据
data = a[i].get("thumbURL", "not exist")
print(data)</pre>結果は次のとおりです:
3. 完全なコード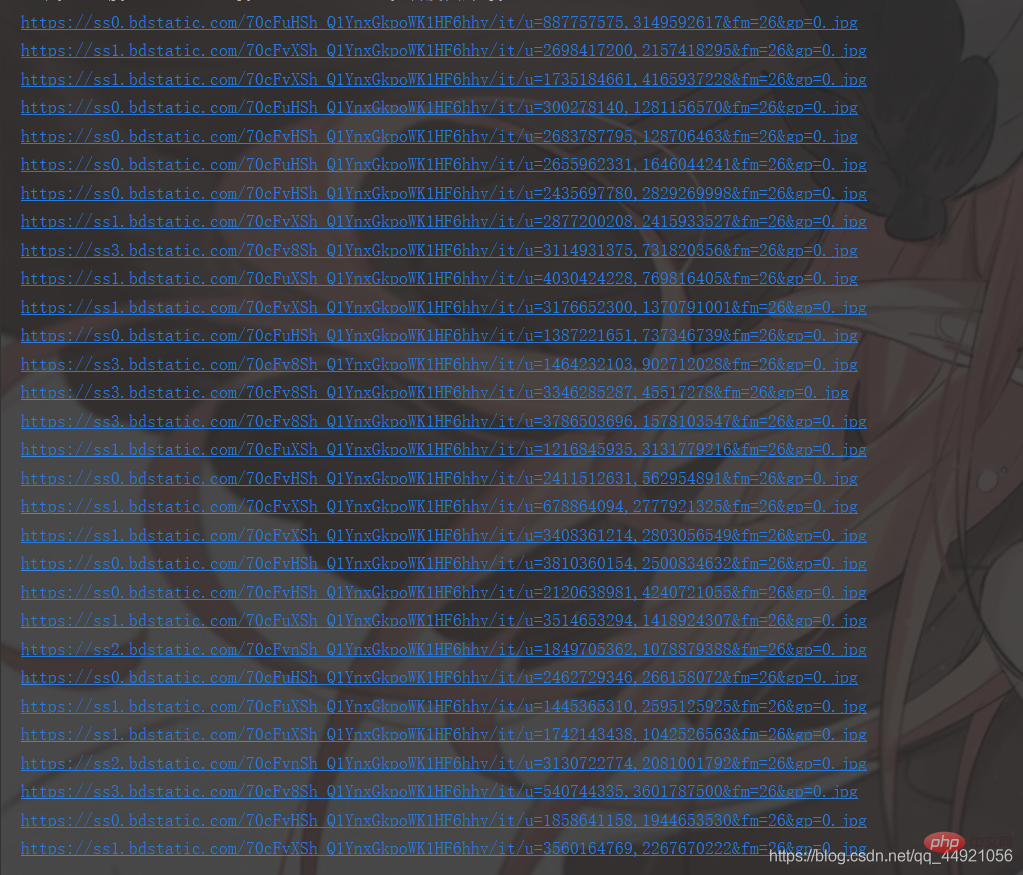
この部分は上記とは少し異なりますが、注意深く見てみると見つかります。
# -*- coding: UTF-8 -*-"""
@Author :远方的星
@Time : 2021/2/27 17:49
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/user/8320044
"""import requestsimport jsonimport osimport pprint# 创建一个文件夹path = 'D:/百度图片'if not os.path.exists(path):
os.mkdir(path)# 导入一个请求头header = {
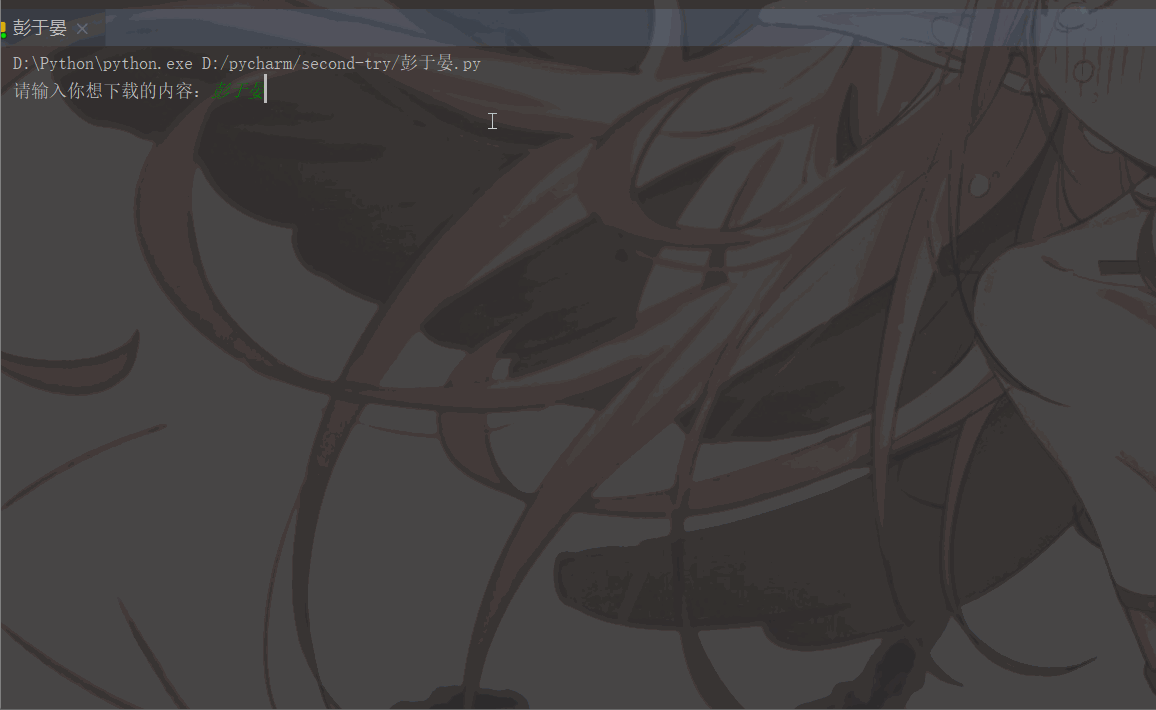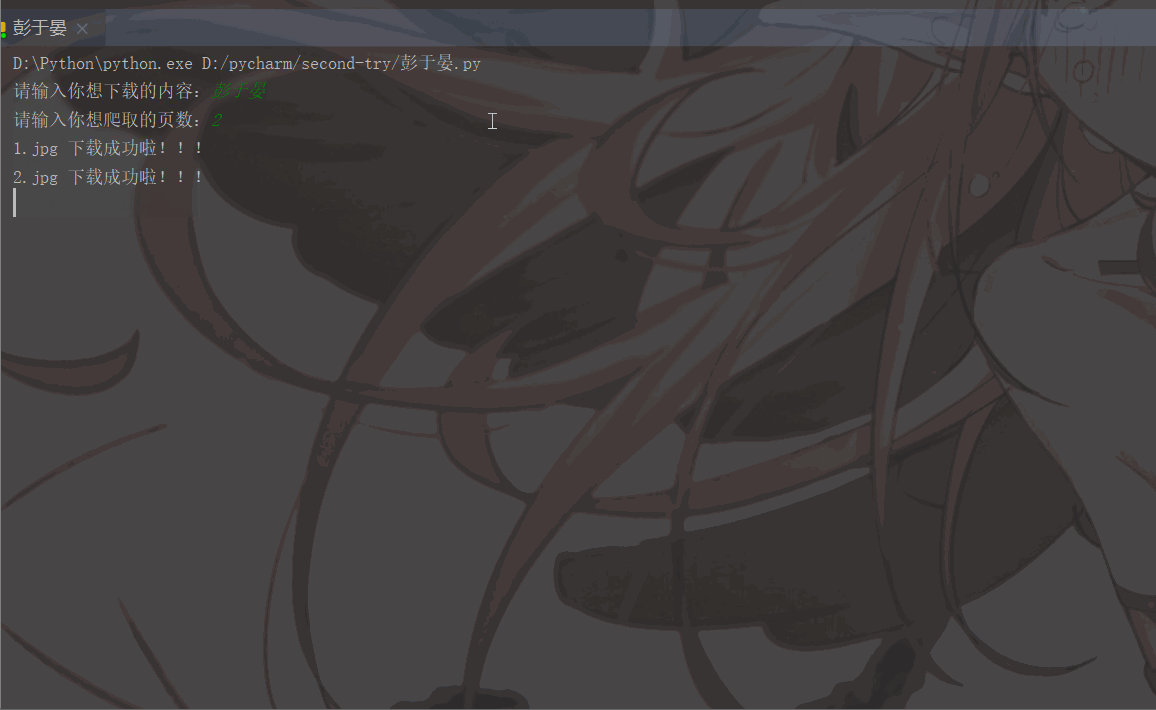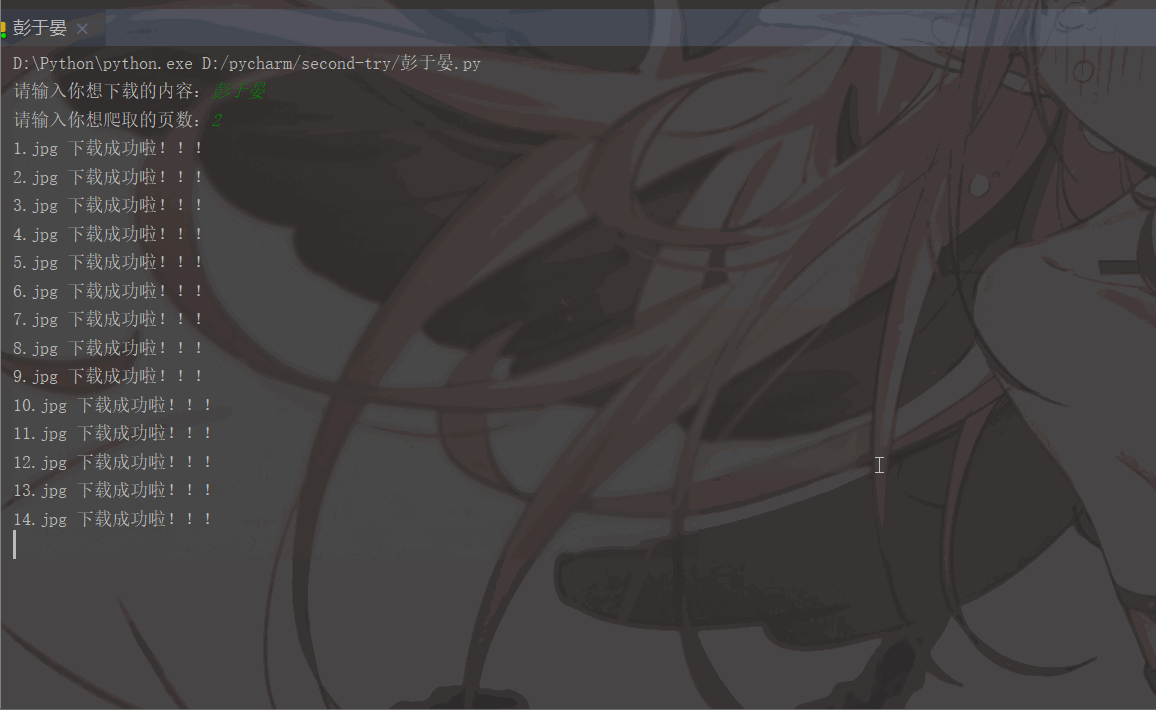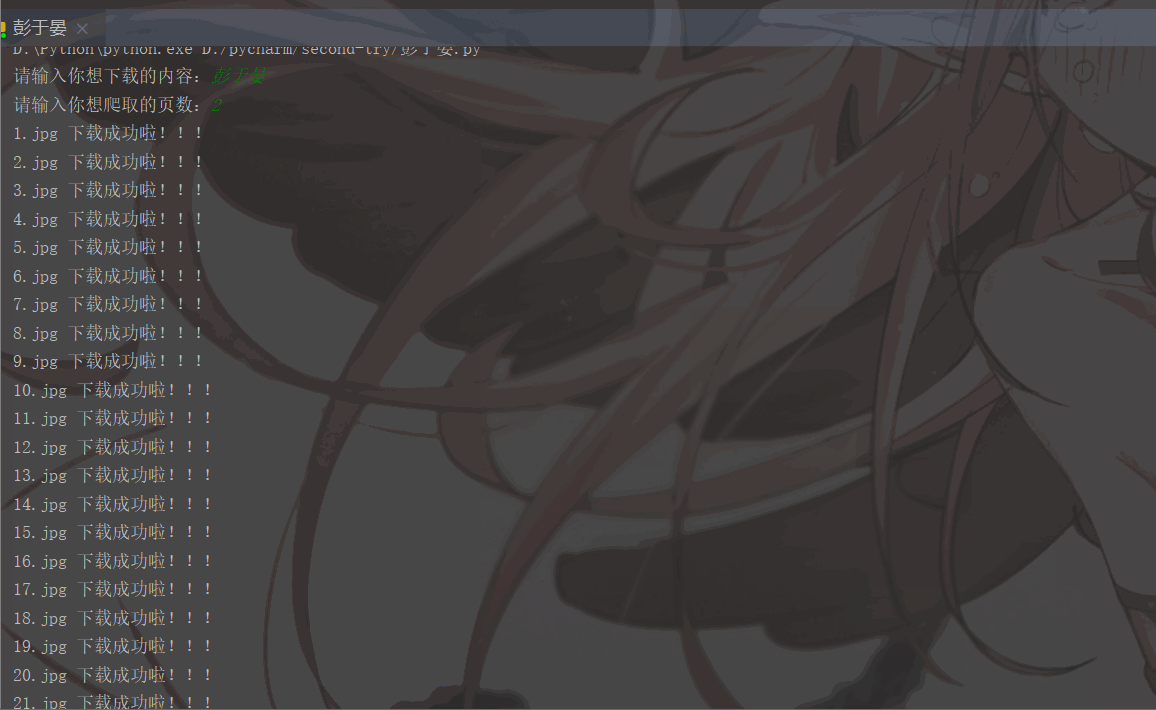
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 用户(自己)输入信息指令keyword = input('请输入你想下载的内容:')page = input('请输入你想爬取的页数:')page = int(page) + 1n = 0pn = 1# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text # 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29
実行結果は次のとおりです:
 フレンドリマインダー
フレンドリマインダー
:  ①: 1 ページは 30 枚の写真です
①: 1 ページは 30 枚の写真です
②: 入力内容はさまざまです: 橋、月、太陽、胡歌、趙立英など。
4.ブロガーのスピーチ
3回連続でいいね、フォロー、集めて応援していただけると嬉しいです! #無料の学習に関する推奨事項が多数あります。Python チュートリアル#(ビデオ)## をご覧ください。 #
以上がPython クローラー: Baidu の写真を好きなようにクロールしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。