
ホームページ >ウェブフロントエンド >jsチュートリアル >JavaScript は一般的なデータ構造 (スタック、キュー、リンク リスト、ハッシュ テーブル、ツリー) を実装します。
JavaScript は一般的なデータ構造 (スタック、キュー、リンク リスト、ハッシュ テーブル、ツリー) を実装します。

- 青灯夜游転載
- 2020-12-31 17:14:296169ブラウズ
関連する推奨事項: 「JavaScript ビデオ チュートリアル 」
JavaScript では、データ構造は通常無視されるか、あまり触れられません。しかし、多くの大企業では、通常、データの管理方法を深く理解する必要があります。データ構造を理解することは、問題を解決する際の作業にも役立ちます。
この記事で説明および実装するデータ構造は次のとおりです:
- スタック
- キュー
- リンク リスト
- ハッシュ テーブル
- ツリー
スタック
最初のデータ構造はスタックです。これはキューに非常に似ており、JavaScript がイベントを処理する方法であるコール スタックについて聞いたことがあるかもしれません。 スタックは次のようになります:
スタックに保存された最後の項目が最初に削除されます。これは後入れ先出し (LIFO) と呼ばれます。 Web ブラウザの「戻る」ボタンはその好例です。表示したすべてのページがスタックに追加され、「戻る」をクリックすると、現在のページ (最後に追加されたページ) がスタックからポップされます。
理論はもう十分です。次に、いくつかのコードを見てみましょう:
class Stack {
constructor() {
// 创建栈结构,这是一个空对象
this.stack = {}
}
// 把一个值压入栈的顶部
push(value) {
}
// 弹出栈顶的值并返回
pop() {
}
// 读取栈中的最后一个值,但是不删除
peek() {
}
}上記のコードをコメントしました。今度は一緒に実装してみましょう。最初の方法は
push です。 まず、このメソッドで何を行う必要があるかを考えてください:
- そして、その値をスタックの先頭に追加します
- スタックのインデックスを知るためには、スタックの長さも追跡する必要があります。
- 最初に自分で試してみることができれば幸いです。完全な
メソッドは次のように実装されます。<pre class="brush:js;toolbar:false;">class Stack {
constructor() {
this._storage = {};
this._length = 0; // 这是栈的大小
}
push(value) {
// 将值添加到栈顶
this._storage[this._length] = value;
// 因为增加了一个值,所以也应该将长度加1
this._length++;
}
/// .....
}</pre> きっと思ったよりも簡単です。このように、実際よりもはるかに複雑に聞こえる構造がたくさんあります。
次は
pop メソッドです。 pop メソッドの目的は、スタックに追加された最後の値を削除してそれを返すことです。可能であれば、まず自分で実装してみてください: <pre class="brush:js;toolbar:false;">class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
pop() {
// we first get the last val so we have it to return
const lastVal = this._storage[--this._length]
// now remove the item which is the length - 1
delete this._storage[--this._length]
// decrement the length
this._length--;
// now return the last value
return lastVal
}
}</pre> 素晴らしいですね!ほぼ完了しました。最後の関数は
関数で、スタック上の最後の項目を調べます。これは最も単純な関数です。最後の値のみを返す必要があります。実装は次のとおりです: <pre class="brush:js;toolbar:false;">class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
/*
* Adds a new value at the end of the stack
* @param {*} value the value to push
*/
peek() {
const lastVal = this._storage[--this._length]
return lastVal
}
}</pre> したがって、これは
メソッドと非常によく似ていますが、最後の項目は削除されません。 ######はい!最初のデータ構造が実装されました。次はキューです。これはスタックによく似ています。 キュー
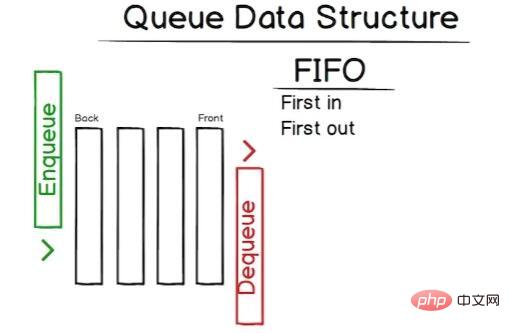
次にキューについて話しましょう。スタックはキューに非常によく似ているため、スタックがまだ頭の中にはっきりと残っていることを願っています。スタックとキューの主な違いは、キューが先入れ先出し (FIFO) であることです。
は次のようにグラフィカルに表すことができます:
したがって、2 つの主なメソッドはenqueue と
です。データはキューの最後に追加され、先頭から削除されます。それをよりよく理解するために、キューの実装を始めましょう。 コア コード構造は次のとおりです。 <pre class="brush:js;toolbar:false;">class Queue {
constructor() {
// 与前面类似,我们为数据结构提供了一个对象
// 并且还有一个变量来保存长度
this.queue = {}
this.length = 0
// 这是一个跟踪头部的新变量
this.head = 0
}
enqueue(value) {
}
dequeue() {
}
peek() {
}
}</pre>最初に
メソッドを実装します。その目的は、キューの最後に項目を追加することです。
enqueue(value) {
// 使用 value 参数将 length + head 的键添加到对象
this.queue[this.length + this.head] = value;
this.length++
}これはキューの末尾に値を追加する非常に簡単な方法ですが、this.queue[this.length this.head] = value; と混乱するかもしれません。困惑した。
キューが {14: 'randomVal'} のようになっているとします。このコンテンツを追加する場合、次に必要な値は
であるため、length(1) head(14)、つまり 15 となる必要があります。 次に実装するのは dequeue:
dequeue() {
// 获取第一个值的引用,以便将其返回
const firstVal = this.queue[this.head]
// 现在将其从队列中删除
delete this.queue[this.head]
this.length--;
// 最终增加我们的头成为下一个节点
this.head++;
}最後に実装するのは peek メソッドです。これは非常に簡単です。
peek() {
// 只需要把值返回即可
return this.queue[this.head];
}キューの実装が完了しました。 リンク リスト
まず、強力なリンク リストについて説明します。これは上記の構造よりもはるかに複雑です。
最初の疑問は、なぜリンク リストを使用するのかということでしょう。リンク リストは主に、動的にサイズ変更される配列を持たない言語で使用されます。リンク リストでは、項目が順番に編成され、1 つの項目が次の項目を指します。
リンクされたリストの各ノードには、
data値と
next 値があります。以下の図では、5 は data 値であり、next 値は次のノード (値 10 を持つノード) を指します。 。 視覚的には次のようになります:
LinkedList は次のようになります
は次のようになります
1 を実装します。") の
の
値が null であることがわかります。 LinkedListの終わり。 それでは、どうすればそれを達成できるのでしょうか? 値
、
2、37 を使用して LinkedList を作成しましょう。 <pre class="brush:js;toolbar:false;">const myLinkedList = {
head: {
value: 1
next: {
value: 2
next: {
value: 37
next: null
}
}
}
};</pre><p>现在我们知道了该怎样手动创建 <code>LinkedList,但是还需要编码实现 LinkedList 的方法。
首先要注意的是,LinkedList 只是一堆嵌套对象!
当构造一个 LinkedList 时,我们需要一个 head 和一个 tail,它们最初都会指向头部(因为 head 是第一个也是最后一个)。
class LinkedList {
constructor(value) {
this.head = {value, next: null}
this.tail = this.head
}
}第一个要实现的方法是 insert ,该方法用来在链表的末尾插入一个值。
// insert 将添加到链接列表的末尾
insert(value) {
/* 创建一个节点 */
const node = {value, next: null}
/* 把 tail 的 next 属性设置为新节点的引用 */
this.tail.next = node;
/* 新节点现在是尾节点 */
this.tail = node;
}上面最混乱的一行可能是 this.tail.next = node。之所以这样做,是因为当添加一个新节点时,我们还希望当前的 tail 指向新的 node,该节点将成为新的 tail。第一次插入 node 时,头部的 next 指针将指向新节点,就像在构造函数中那样,在其中设置了 this.tail = this.head。
你还可以到这个网站来查看图形化的演示,这将帮你了解插入的过程(按 esc 摆脱烦人的弹出窗口)。
下一个方法是删除节点。我们首先要决定参数是值( value) 还是对节点(node)的引用(在面试中,最好先问问面试官)。我们的代码中传递了一个“值”。按值从列表中删除节点是一个缓慢的过程,因为必须要遍历整个列表才能找到值。
我这样做是这样的:
removeNode(val) {
/* 从 head 开始 */
let currentNode = this.head
/* 我们需要保留对上一个节点的引用 */
let previousNode
/* 当存在一个节点时,意味着没有到达尾部 */
while(currentNode) {
/* 如果发现自己想要的那个值,那么就退出循环 */
if(currentNode.value === val) {
break;
}
/* 没有找到值就将 currentNode 设置为 previousNode */
previousNode = currentNode
/* 得到下一个节点并将其分配给currentNode */
currentNode = currentNode.next
}
/* 返回undefined,因为没有找到具有该值的节点 */
if (currentNode=== null) {
return false;
}
// 如果节点是 head ,那么将 head 设置为下一个值
头节点的
if (currentNode === this.head) {
this.head = this.head.next;
return;
}
/* 通过将节点设置为前面的节点来删除节点 */
previousNode.next = currentNode.next
}removeNode 方法使我们对 LinkedList 的工作方式有了很好的了解。
所以再次说明一下,首先将变量 currentNode 设置为 LinkedList 的 head,因为这是第一个节点。然后创建一个名为 previousNode 的占位符变量,该变量将在 while 循环中使用。从条件 currentNode 开始 while 循环,只要存在 currentNode,就会一直运行。
在 while 循环中第一步是检查是否有值。如果不是,则将 previousNode 设置为 currentNode,并将 currentNode 设置为列表中的下一个节点。继续进行此过程,直到找到我需要找的值或遍历完节点为止。
在 while 循环之后,如果没有 currentNode,则返回 false,这意味着没有找到任何节点。如果确实存在一个 currentNode,则检查的 currentNode 是否为 head。如果是的话就把 LinkedList 的 head 设置为第二个节点,它将成为 head。
最后,如果 currentNode 不是头,就把 previousNode 设置为指向 currentNode 前面的 node,这将会从对象中删除 currentNode。
另一个常用的方法(面试官可能还会问你)是 removeTail 。这个方法如其所言,只是去掉了 LinkedList 的尾节点。这比上面的方法容易得多,但工作原理类似。
我建议你先自己尝试一下,然后再看下面的代码(为了使其更复杂一点,我们在构造函数中不使用 tail):
removeTail() {
let currentNode = this.head;
let previousNode;
while (currentNode) {
/* 尾部是唯一没有下一个值的节点,所以如果不存在下一个值,那么该节点就是尾部 */
if (!currentNode.next) {
break;
}
// 获取先前节点的引用
previousNode = currentNode;
// 移至下一个节点
currentNode = currentNode.next;
}
// 要删除尾部,将 previousNode.next 设置为 null
previousNode.next = null;
}这些就是 LinkedList 的一些主要方法。链表还有各种方法,但是利用以上学到的知识,你应该能够自己实现它们。
哈希表
接下来是强大的哈希表。
哈希表是一种实现关联数组的数据结构,这意味着它把键映射到值。 JavaScript 对象就是一个“哈希表”,因为它存储键值对。
在视觉上,可以这样表示:
在讨论如何实现哈希表之前,需要讨论讨论哈希函数的重要性。哈希函数的核心概念是它接受任意大小的输入并返回固定长度的哈希值。
hashThis('i want to hash this') => 7
哈希函数可能非常复杂或直接。 GitHub 上的每个文件都经过了哈希处理,这使得每个文件的查找都非常快。哈希函数背后的核心思想是,给定相同的输入将返回相同的输出。
在介绍了哈希功能之后,该讨论一下如何实现哈希表了。
将要讨论的三个操作是 insert、get最后是 remove。
实现哈希表的核心代码如下:
class HashTable {
constructor(size) {
// 定义哈希表的大小,将在哈希函数中使用
this.size = size;
this.storage = [];
}
insert(key, value) { }
get() {}
remove() {}
// 这是计算散列密钥的方式
myHashingFunction(str, n) {
let sum = 0;
for (let i = 0; i < str.length; i++) {
sum += str.charCodeAt(i) * 3;
}
return sum % n;
}
}现在解决第一个方法,即 insert。insert 到哈希表中的代码如下(为简单起见,此方法将简单的处理冲突问题):
insert(key, value) {
// 得到数组中的索引
const index = this.myHashingFunction(key, this.size);
// 处理冲突 - 如果哈希函数为不同的键返回相同的索引,
// 在复杂的哈希函数中,很可能发生冲突
if (!this.storage[index]) {
this.storage[index] = [];
}
// push 新的键值对
this.storage[index].push([key, value]);
}像这样调用 insert 方法:
const myHT = new HashTable(5);
myHT.insert("a", 1);
myHT.insert("b", 2);你认为我们的哈希表会是什么样的?
你可以看到键值对已插入到表中的索引 1 和 4 处。
现在实现从哈希表中删除
remove(key) {
// 首先要获取 key 的索引,请记住,
// 哈希函数将始终为同一 key 返回相同的索引
const index = this.myHashingFunction(key, this.size);
// 记住我们在一个索引处可以有多个数组(不太可能)
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
// 遍历该索引处的所有数组
for (let i = 0; i < arrayAtIndex.length; i++) {
// get the pair (a, 1)
let pair = arrayAtIndex[i];
// 检查 key 是否与参数 key 匹配
if (pair[0] === key) {
delete arrayAtIndex[i];
// 工作已经完成,所以要退出循环
break;
}
}
}
}最后是 get 方法。这和 remove 方法一样,但是这次,我们返回 pair 而不是删除它。
get(key) {
const index = this.myHashingFunction(key, this.size);
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
for (let i = 0; i < arrayAtIndex.length; i++) {
const pair = arrayAtIndex[i];
if (pair[0] === key) {
return pair[1];
}
}
}
}我认为不需要执行这个操作,因为它的作用与 remove 方法相同。
你可以认为它并不像最初看起来那样复杂。这是一种到处使用的数据结构,也是是一个很好理解的结构!
二叉搜索树
最后一个数据结构是臭名昭著的二叉搜索树。
在二叉搜索树中,每个节点具有零个、一个或两个子节点。左边的称为左子节点,右边的称为右子节点。在二叉搜索树中,左侧的子项必须小于右侧的子项。
你可以像这样描绘一个二叉搜索树:
%20%E3%82%92%E5%AE%9F%E8%A3%85%E3%81%97%E3%81%BE%E3%81%99%E3%80%82 "160940586817023JavaScript は一般的なデータ構造 (スタック、キュー、リンク リスト、ハッシュ テーブル、ツリー) を実装します。")
树的核心类如下:
class Tree {
constructor(value) {
this.root = null
}
add(value) {
// 我们将在下面实现
}
}我们还将创建一个 Node 类来代表每个节点。
class Node {
constructor(value, left = null, right = null) {
this.value = value;
this.left = left;
this.right = right;
}
}下面实现 add 方法。我已经对代码进行了注释,但是如果你发现使你感到困惑,请记住,我们要做的只是从根开始并检查每个节点的 left 和 right。
add(value) {
// 如果没有根,那么就创建一个
if (this.root === null) {
this.root = new Node(value);
return;
}
let current = this.root;
// keep looping
while (true) {
// 如果当前值大于传入的值,则向左
if (current.value > value) {
// 如果存在左子节点,则再次进行循环
if (current.left) {
current = current.left;
} else {
current.left = new Node(value);
return;
}
}
// 值较小,所以我们走对了
else {
// 向右
// 如果存在左子节点,则再次运行循环
if (current.right) {
current = current.right;
} else {
current.right = new Node(value);
return;
}
}
}
}测试新的 add 方法:
const t = new Tree(); t.add(2); t.add(5); t.add(3);
现在树看起来是这样:
%20%E3%82%92%E5%AE%9F%E8%A3%85%E3%81%97%E3%81%BE%E3%81%99%E3%80%82 "160940587511415JavaScript は一般的なデータ構造 (スタック、キュー、リンク リスト、ハッシュ テーブル、ツリー) を実装します。")
为了更好的理解,让我们实现一个检查树中是否包含值的方法。
contains(value) {
// 获取根节点
let current = this.root;
// 当存在节点时
while (current) {
// 检查当前节点是否为该值
if (value === current.value) {
return true; // 退出函数
}
// 通过将我们的值与 current.value 进行比较来决定下一个当前节点
// 如果小则往左,否则往右
current = value < current.value ? current.left : current.right;
}
return false;
}Add 和 Contains 是二进制搜索树的两个核心方法。对这两种方法的了解可以使你更好地解决日常工作中的问题。
总结
我已经在本文中介绍了很多内容,并且掌握这些知识后在面试中将使你处于有利位置。希望你能够学到一些东西,并能够轻松地通过技术面试(尤其是讨厌的白板面试)。
更多编程相关知识,请访问:编程教学!!
以上がJavaScript は一般的なデータ構造 (スタック、キュー、リンク リスト、ハッシュ テーブル、ツリー) を実装します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。