
ホームページ >データベース >mysql チュートリアル >Pinterest MySQL の実践ではシャーディングを使用して数百億のデータのストレージ問題を解決しています
Pinterest MySQL の実践ではシャーディングを使用して数百億のデータのストレージ問題を解決しています

- coldplay.xixi転載
- 2020-12-24 09:25:552209ブラウズ
mysql ビデオ チュートリアルこのコラムでは、シャーディングを使用して数百億のデータのストレージを解決する方法を紹介します

推奨 (無料): mysql ビデオ チュートリアル
これは、複数の MySQL サーバーにデータを分割する方法に関する技術的な研究です。このシャーディング アプローチは 2012 年の初めに完了し、現在でもコア データの保存に使用されているシステムです。
データを分割する方法について説明する前に、まずデータを理解しましょう。ムード照明、チョコレートで覆われたイチゴ、スタートレックの引用...
Pinteres は、興味のあるものすべてを発見するエンジンです。データの観点から見ると、Pinterest は人間が興味を持った画像の世界最大のコレクションです。 10 億のボード上でピンナーによって保存されたピンは 500 億以上あります。ユーザーは再度ピンを付け、他の人のピンに「いいね!」をし(ほぼ浅いコピー)、他のピンナー、ボード、興味をフォローし、その後、ホーム ページ上の購読済みピンナーの投稿をすべて表示します。とても良い!さあ、スケールアップしてみましょう!
成長の痛み
2011 年、私たちは成功を収めました。いくつかの評価レポートでは、当社は他のスタートアップよりもはるかに速く成長しています。 2011 年 9 月に、インフラ設備のすべてが限界を超えました。私たちは数多くの NoSQL テクノロジーを適用しましたが、そのすべてが悲惨な結果をもたらしました。同時に、読み取りに多数の MySQL スレーブ サーバーが使用されるため、特にキャッシュに関して多くの迷惑なバグが発生しました。データ ストレージ モデル全体を再構築しました。これを効果的に行うために、私たちは要件を慎重に策定します。
ビジネス要件
- 当社のすべてのシステムは、非常に安定しており、操作が簡単で、拡張が簡単である必要があります。私たちは、サポートされるデータベースが小さなストレージ容量から開始され、ビジネスの発展に応じて拡張できることを期待しています。
- ピンで生成されたすべてのコンテンツは、サイト上ですぐにアクセスできる必要があります。
- 特定の順序 (作成時間に従って、またはユーザー固有の順序など) でアートボードに表示される N 個のピンへのアクセスのリクエストをサポートします。いいねしたピン友達やピン友達のピンリストを指定した順番で表示することもできます。
- わかりやすくするために、通常、更新により最良の結果が保証されます。最終的な整合性を確保するには、分散トランザクション ログなどの追加のものが必要です。これは興味深いものですが、単純ではありません。
ソリューションのアイデアと重要なポイント
このソリューションでは、大量のデータ スライスを複数のデータベース インスタンスに分散する必要があるため、リレーショナル データベースへの接続は使用できません。外部キーまたはインデックスはデータ全体を統合します。よく考えてみると、相関サブクエリは異なるデータベース インスタンスにまたがることはできません。
私たちのソリューションにはデータ アクセスの負荷分散が必要です。私たちはデータ移行、特にレコードごとの移行を嫌います。これは非常にエラーが発生しやすく、関係の複雑さによってシステムに不必要な複雑さが追加されます。データを移行する必要がある場合は、論理ノードのセット全体を移行するのが最善です。
ソリューションの信頼性と迅速な実装を実現するには、分散データ プラットフォーム上で実装が最も簡単で堅牢な技術ソリューションを使用する必要があります。
各インスタンス上のすべてのデータは、データ バックアップとして スレーブ インスタンス に完全にコピーされます。可用性の高い MapReduce (分散コンピューティング環境) である S3 を使用しています。フロントエンド ビジネス ロジックはバックグラウンド データにアクセスし、データベースの メイン インスタンス にのみアクセスします。 フロントエンド ビジネスにインスタンス からの読み取りおよび書き込みアクセスを許可しないでください。 メイン インスタンスとのデータ同期に遅延があるため、不可解なエラーが発生します。データがスライスされて分散されると、フロントエンド ビジネスがデータを読み書きする理由はなくなります。 スレーブ インスタンスから。
最後に、すべてのデータ オブジェクトの グローバル一意識別子 (UUID) を生成および解析するための優れたソリューションを慎重に設計する必要があります。
当社のスライシング ソリューション
何はともあれ、ニーズを満たし、堅牢で、優れたパフォーマンスを備え、保守しやすいデータ分散ソリューションを設計する必要があります。言い換えれば、(広範な検証がなければ)ナイーブであることはできません。したがって、私たちの基本設計は MySQL に基づいて構築されています。成熟したテクノロジーを選択したことを見てください。設計の開始時には、MongoDB、Cassandra、Membase などの自動スケーリングの新機能を主張するデータベース製品は当然敬遠されます。これらの製品は、実装は簡単そうに見えますが、適用性が低いためです (多くの場合、説明できないエラーが発生し、クラッシュが発生しました)。
ナレーション: 基本から始めて、流行のものや新しいものは避け、現実的な方法で MySQL を学び、使用することを強くお勧めします。信じてください、すべての言葉に涙があふれます。
MySQL は、成熟した安定した使いやすいリレーショナル データベース製品です。当社が使用しているだけでなく、多くの有名な大企業も、大量のデータを保存するバックエンド データ サポートとして使用しています。 (注: 数年ほど前、MySQL は SUN とともに Oracle に買収されたため、Oracle という名前になりました。Google や Facebook などの多くの企業が MySQL のオープンソースの問題を懸念し、別のものに切り替えました) MySQL のオリジナルの作成者によって開発されたデータベース。オープン ソース データベース MariaDB (MySQL の下) は、データベースへの連続したデータ要求、指定された範囲のデータのクエリ、および行 (レコード) レベルでのトランザクション処理に対する技術要件をサポートしています。 MySQL には多くの機能がありますが、それらは必要ありません。 MySQL 自体はモノリシック ソリューションであるため、データをスライスする必要があります。 (注釈: ここでの意味は、単一のインスタンスが大量のデータを管理するため、必然的にパフォーマンスの問題が発生するということです。現在、大量のデータ全体を個々のデータセットにスライスするには、個々のデータセットを分離するための強力な技術的ソリューションが必要です。モノリスは統合されています。問題を起こさずにパフォーマンスを向上させます) 以下は私たちの設計計画です:
8 台の EC2 サーバーで開始し、各サーバーは MySQL インスタンスを実行します:


各 MySQL サーバーは、災害復旧のために冗長ホストに複製されたマスター-マスターを使用します。 当社のフロントエンド ビジネスは、メイン サービス インスタンスからのデータの読み取り/書き込みのみを行います。同じようにすることをお勧めします。これにより、多くのことが簡素化され、遅延による不具合が回避されます。 (注釈: Master-master replicated) は、MySQL データベース自体が提供する機能で、2 台のマシンが相互にバックアップするモードを指します。マスター/スレーブ バックアップなどの他のモードと比較して、2マシン 各マシンのデータは完全に一貫しており、バックグラウンドで同期されます。各マシンは独自の独立した IP を持ち、読み取り/書き込みアクセスのために同時にアクセスできます。ただし、元の記事の著者は、2 つのマシンは同じであるにもかかわらず、次のことを繰り返し強調しています。相互に冗長化し、マスター-マスターバックアップを使用すると、両方のマシンにアクセスできますが、論理的にマスターとスレーブを区別し、常にどちらか一方から読み書きします。たとえば、図に示すように、マスターがあります。 -MySQL001A と MySQL001B の間のマスター バックアップですが、MySQL001A からの読み取り/書き込みアクセスのみを実行します。別の: 彼らは 16 台のマシンを使用し、他の 8 台のスレーブ マシンは EC2 であるかどうかはわかりません)
各 MySQL インスタンスには、複数のデータベース:
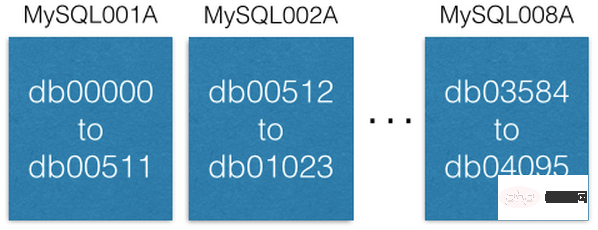
[
{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}
]この構成テーブルは、スライス データベースが移行されるか、ホストが置き換えられる場合にのみ変更されます。たとえば、マスター インスタンス ホストがダウンした場合、そのスレーブ インスタンス ホストをマスター インスタンスに昇格させ、できるだけ早くスレーブ インスタンス ホストとして新しいマシンに置き換えます。構成スクリプトは ZooKeeper 上に保持されており、上記の変更が行われると、スクリプトは構成変更のためにスライシング サービスを維持するマシンに送信されます。 (注釈: フロントエンド ビジネスは論理マスター インスタンスからのデータの読み取りと書き込みのみを行うことを、原著者が常に強調してきた利点がわかります)。 各スライス データベースは、ピン、ボード、users_has_pins、users_likes_pins、pin_liked_by_user、その他のデータベース テーブルなど、同じデータベース テーブルとテーブル構造を維持します。デプロイメント時に同期的にビルドします。 スライス サーバーにデータを分散するための設計スキーム
シャード ID (シャード ID)、データ型識別、および ローカル ID (ローカル ID)## を組み合わせます。 # 64 ビットの グローバル一意識別子 (ID) を形成します。 スライス ID (シャード ID) は 16 ビット (ビット) を占め、データ型識別は 10 ビット (ビット) を占め、 ローカル ID (ローカル ID) は 36 ビット (ビット) を占めます。目の肥えた人なら、これがわずか 62 ビットであることにすぐに気づくでしょう。データの分散と統合に関する私の過去の経験から、拡張のためにいくつかのデータを保持しておくのは非常に貴重であることがわかります。したがって、2 ビットを保持 (0 に設定) しました。 (注釈: ここで説明します。以下の操作と説明によると、任意のオブジェクトの一意の識別 ID は 64 ビットです。最上位 2 ビットは常に 0 で、その後に 36 ビットのローカル ID、その後に 10 ビットが続きます。タイプ識別、最後に 16 ビット スライス識別子。ローカル識別子は 2^36 から最大 600 億を超える ID を表現できます。データ型は 2^10 から最大 1024 のオブジェクト タイプを表現でき、スライス識別子は次のように細分化できます。 2^16 最大 65536 のスライス データベース。前述のソリューションは 4096 スライス データベース) ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
ピンを例として挙げます: https://www.pinterest.com/pin/241294492511...この Pin オブジェクトのグローバル ID 241294492511762325 を分解します:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
可知这个 Pin 对象在3429切片数据库里。 假设 Pin 对象 数据类型标识为 1,它的记录在3429切片数据库里的 pin 数据表中的 7075733 记录行中。举例,假设切片3429数据库在 MySQL012A中,我们可利用下面语句得到其数据记录:(译注:这里原作者泛泛举例,若按其前面方案例子来说,3429应在MySQL007A 上)
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
有两种类型的数据:对象或关系。对象包含对象本身细节。 如 Pin 。
存储对象的数据库表
对象库表中的每个记录,表示我们前端业务中的一个对象,诸如:Pins(钉便签), users(用户),boards(白板)和 comments(注释),每个这样的记录在数据库表中设计一个标识 ID 字段(这个字段在表中作为记录的 自增主键「auto-incrementing primary key」 ,也就是我们前面提到的 局部 ID「 local ID」 ),和一个 blob 数据字段 -- 使用 JSON 保存对象的具体数据 --。
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
举例,一个 Pin 对象形状如下:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
创建一个 Pin 对象,收集所有的数据构成 JSON blob 数据。然后,确定它的 切片 ID「 shard ID」 (我们更乐意把 Pin 对象的切片数据放到跟其所在 白板「 board」 对象相同的切片数据库里,这不是强制设计规则)。Pin 对象的数据类型标识为 1。连接到 切片 ID 指示的切片数据库,插入(insert)Pin 对象的 JOSON 数据到 Pin 对象数据库表中,MySQL 操作成功后将会返回 自增主键「auto-incrementing primary key」 给你,这个作为此 Pin 对象的 局部 ID「 local ID」。现在,我们有了 shard 、类型值、local ID 这些必要信息,就可以构建出此 Pin 对象的64位 ID 。(译注:原作者提到的,他们的前端业务所用到的每种对象都保存在一个对象数据库表里,每个对象记录都通过一个全局唯一 ID去找到它,但这个全局唯一 ID并不是数据库表中的 局部ID,由于切片的缘故。原作者一直在讲这个设计及其原理。这样设计的目的为了海量数据切片提高性能,还要易用,可维护,可扩展。后面,作者会依次讲解到)
编辑一个 Pin 对象,使用 MySQL 事务「transaction」 在 Pin 对象的数据记录上 读出--修改--写回「read-modify-write」 Pin 对象的 JOSON 数据字段:
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [修改 json blob] > UPDATE db03429.pins SET blob=’<修改后的 blob>’ WHERE local_id=7075733 > COMMIT
编辑一个 Pin 对象,您当然可以直接删除这个对象在 MySQL 数据库表中的数据记录。但是,请仔细想一下,是否在对象的 JSON 数据上加个叫做「 active」的域,把剔除工作交由前端中间业务逻辑去处理或许会更好呢。
(译注:学过关系数据库的应知道,自增主键在记录表中是固实,在里面删除记录,会造成孔洞。当多了,势必造成数据库性能下降。数据库只负责保存数据和高性能地查询、读写数据,其数据间的关系完全靠设计精良的对象全局ID通过中间件逻辑去维护 这样的设计理念一直贯穿在作者的行文中。只有理解了这点您才能抓住这篇文章的核心)
关系映射数据库表
关系映射表表示的是前端业务对象间的关系。诸如:一个白板(board)上有哪些钉便签(Pin), 一个钉便签(Pin)在哪些白板(board)上等等。表示这种关系的 MySQL 数据库表包括3个字段:一个64位的「from」ID, 一个64位的「to」ID和一个顺序号。每个字段上都做索引方便快速查询。其记录保存在根据「from」字段 ID 解构出来的切片 ID 指示出的切片数据库上。
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
(译注:这里的关系映射指前端业务对象间的关系用数据库表来运维,并不指我上节注释中说到的关系数据库的关系映射。作者开篇就讲到,由于切片,不能做关系数据库表间的关系映射的,如一对一,一对多,多对多等关系关联)
关系映射表是单向的,如 board_has_pins(板含便签)表方便根据 board (白板)ID查询其上有多少 Pin(钉便签)。若您需要根据 Pin(钉便签)ID查询其都在哪些 board(白板)上,您可另建个表 pin_owned_by_board(便签属于哪些白板)表,其中 sequence 字段表示 Pin 在 board 上的顺序号。(由于数据分布在切片数据库上,我们的 ID 本身无法表示其顺序)我们通常将一个新的 Pin 对象加到 board 上时,将其 sequence 设为当时的系统时间。sequence 可被设为任意整数,设为当时的系统时间,保证新建的对象的 sequence 总是大于旧对象的。这是个方便易行的方法。您可通过下面的语句从关系映射表中查询对象数据集:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
语句会查出50个 pin_ids(便签 ID ),随后可用这些对象 ID 查询其具体信息。
我们只在业务应用层进行这些关系的映射,如 board_id -> pin_ids -> pin objects (从 白板 ID -> 便签 IDs -> 便签对象)。 这种设计一个非常棒的特性是,您可以分开缓存这些关系映射对。例如,我们缓存 pin_id -> pin object (便签 ID -> 便签对象)关系映射在 memcache(内存缓存)集群服务器上,board_id -> pin_ids (白板 ID -> 便签 IDs)关系映射缓存在 redis 集群服务器上。这样,可以非常适合我们优化缓存技术策略。
增大服务能力
在我们的系统中,提升服务处理能力主要三个途径。最容易的是升级机器(更大的空间,更快的硬盘速度,更多的内存,无论什么解决系统瓶颈的升级都算)
另一个途径,扩大切片范围。最初,我们设计只切片了4096个数据库,相比我们设计的16位的切片 ID,还有许多空间,因为16位可表示65536个数。某些时间节点,若我们再提供8台机器运行8个 MySQL 数据库实例,提供从 4096 到 8192 的切片数据库,之后,新的数据将只往这个区间的切片数据库上存放。并行计算的数据库有16台,服务能力必然提升。
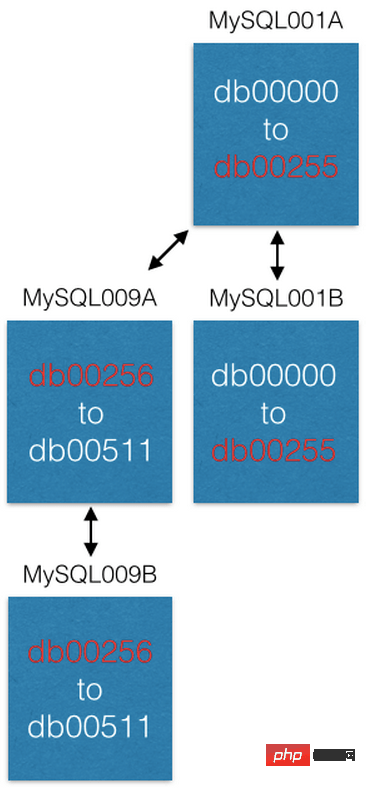
最后的途径,迁移切片数据库主机到新切片主机(局部切片扩容)以提升能力。例如,我们想将前例中的 MySQL001A 切片主机(其上是 0 到 511 编号的切片数据库)扩展分布到2台切片主机上。同我们设计地,我们创建一个新的 master-master 互备份主机对作为新切片主机(命名为 MySQL009A 和 B)并从 MySQL001A 上整体复制数据。

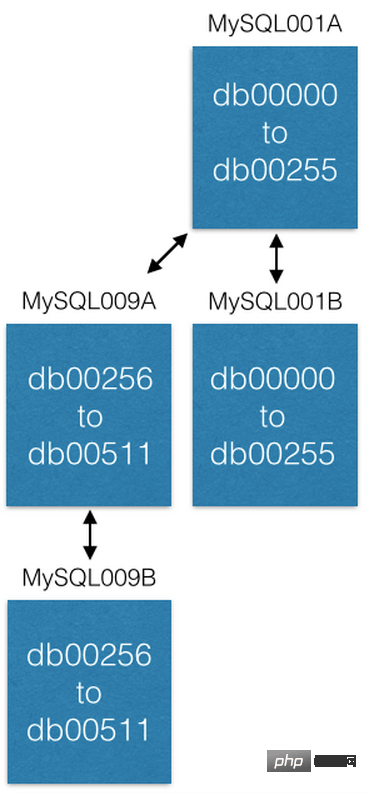
当数据复制完成后,我们修改切片配置,MySQL001A 只负责 0 到 255 的切片数据库,MySQL009A 只负责 256 到 511 的切片数据库。现在2台中每台主机只负责过去主机负责的一半的任务,服务能力提升。
一些特性说明
对于旧系统已产生的业务对象数据,要根据设计,对业务对象要生成它们在新系统中的 UUIDs,你应意识到它们放到哪儿(哪个切片数据库)由你决定。(译注:你可以规划旧数据在切片数据库上的分布)但是,在放入到切片数据库时,只有在插入记录时,数据库才会返回插入对象的 local ID,有了这个,才能构建对象的 UUID。
(译注:在迁移时要考虑好业务对象间关系的建立,通过UUID)
对于那些在已有大量数据的数据库表,曾使用过修改表结构类命令 (ALTERs)--诸如添加个字段之类的 -- 的人来说,您知道那是一个 非常 漫长和痛苦的过程。我们的设计是绝不使用 MySQL 上 ALTERs 级别的命令(当已有数据时)。在我们的业务系统 Pinterest 上,我们使用最后一个 ALTER 语句大概是在3年前了。 对于对象表中对象,如果您需要添加个对象属性字段,您添加到对象数据的 JOSON blob 字段里。您可以给新对象属性设定个默认值,当访问到旧对象的数据时,若旧对象没有新属性,您可以给其添加上新属性默认值。对于关系映射表来说,干脆,直接建立新的关系映射表以符合您的需要。这些您都清楚了!让您的系统扬帆起行吧!
模转(mod)数据库的切片
模转数据切片(mod shard)名称仅仅是像 Mod Squad,实则完全不同。
一些业务对象需要通过非 ID (non-ID)的方式查询访问。(译注: 此 ID 指之前设计说明中的64位 UUID)举例来说,如果一名 Pin友(Pinner)是以他(她)的 facebook 注册帐号注册登录我们的业务平台上的。我们需将其 facebook ID 与我们的 Pin友(Pinner)的 ID 映射。 facebook ID 对于我们系统只是一串二进制位的数。(译注:暗示我们不能像我们系统平台的设计那样解构别的平台的 ID,也谈不上如何设计切片,只是把它们保存起来,并设计使之与我们的 ID 映射)因此,我们需要保存它们,也需要把它们分别保存在切片数据库上。我们称之为模转数据切片(mod shard)其它的例子还包括 IP 地址、用户名和用户电子邮件等。
模转数据切片(mod shard)类似前述我们业务系统的数据切片设计。但是,你需要按照其输入的原样进行查询。如何确定其切片位置,需要用到哈希和模数运算。哈希函数将任意字串转换成定长数值,而模数设为系统已有切片数据库的切片数量,取模后,其必然落在某个切片数据库上。结果是其数据将保存在已有切片数据库上。举例:
shard = md5(“1.2.3.4") % 4096
(译注:mod shard 这个词,我网上找遍了,试图找到一个较准确权威的中文翻译!无果,因为 mod 这个词有几种意思,最近的是module 模块、模组,同时它也是模运算符(%)。我根据原文意思,翻译为 模转 。或可翻译为 模式,但个人感觉意思模糊。不当之处,请指正。另,原作者举的例子是以 IP 地址举例的,哈希使用的是 md5,相比其它,虽老但性能最好)
在这个例子中分片是1524。 我们维护一个类似于ID分片的配置文件:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”},
{“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”},
{“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”},
…]
因此,为了找到 IP 为1.2.3.4的数据,我们将这样做:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
你失去了一些分片好的属性,例如空间位置。你必须从一开始就设置分片的密钥(它不会为你制作密钥)。最好使用不变的id来表示系统中的对象。这样,当用户更改其用户名时,您就不必更新许多引用。
最后的提醒
这个系统作为 Pinterest 的数据支撑已良好运行了3.5年,现在看来还会继续运行下去。设计实现这样的系统是直观、容易的。但是让它运行起来,尤其迁移旧数据却太不易了。若您的业务平台面临着急速增长的痛苦且您想切片自己的数据库。建议您考虑建立一个后端集群服务器(优先建议 pyres)脚本化您迁移旧数据到切片数据库的逻辑,自动化处理。我保证无论您想得多周到,多努力,您一定会丢数据或丢失数据之间的关联。我真的恨死隐藏在复杂数据关系中的那些捣蛋鬼。因此,您需要不断地迁移,修正,再迁移... 你需要极大的耐心和努力。直到您确定您不再需要为了旧数据迁移而往您的切片数据库中再操作数据为止。
这个系统的设计为了数据的分布切片,已尽最大的努力做到最好。它本身不能提供给你数据库事务 ACID 四要素中的 Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)哇呕!听起来很坏呀,不用担心。您可能不能利用数据库本身提供的功能很好地保证这些。但是,我提醒您,一切尽在您的掌握中,您只是让它运行起来,满足您的需要就好。设计简单直接就是王道,(译注:也许需要您做许多底层工作,但一切都在您的控制之中)主要是它运行起来超快! 如果您担心 A(原子性)、I(隔离性)和 C(一致性),写信给我,我有成堆的经验让您克服这些问题。
还有最后的问题,如何灾难恢复,啊哈? 我们创建另外的服务去维护着切片数据库,我们保存切片配置在 ZooKeeper 上。当单点主服务器宕掉时,我们有脚本自动地提升主服务器对应的从服务器立即顶上。之后,以最快的速度运行新机器顶上从服务器的缺。直至今日,我们从未使用过类似自动灾难恢复的服务。
以上がPinterest MySQL の実践ではシャーディングを使用して数百億のデータのストレージ問題を解決していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。