
ホームページ >データベース >mysql チュートリアル >数百億のデータがテーブルに分割された後のページング クエリを理解する
数百億のデータがテーブルに分割された後のページング クエリを理解する

- coldplay.xixi転載
- 2020-11-09 17:24:033219ブラウズ
mysql ビデオ チュートリアル 列では、数百億のデータのページング クエリを紹介します。

#事業規模がある程度の規模に達すると、タオバオの1日の注文量は5,000万件を超え、美団の1日の注文量は5,000万件を超えます。注文数は3,000万件を超えています。データベースが大規模なデータ負荷に直面している場合、サブデータベースとテーブルのサブ操作が必要になります。データベースがテーブルに分割された後、一部の通常のクエリで問題が発生する可能性があります。最も一般的なのはページング クエリです。通常、シャーディング テーブルのフィールドのことを shardingkey と呼びます。たとえば、注文テーブルではユーザー ID が shardingkey として使用されます。では、クエリ条件にユーザー ID が含まれていない場合にページングを行うにはどうすればよいでしょうか?たとえば、シャーディング キーがない場合、どのようにしてより多くの多次元クエリを実行できるでしょうか?
一意の主キー
一般に、データベースの主キーは自動的にインクリメントされるため、テーブル分割後の主キーの競合の問題は避けられません。最も簡単な方法は、次の方法です。ユニークなビジネス このフィールドは唯一の主キーとして機能します。たとえば、注文テーブルの注文番号はグローバルに一意である必要があります。
一意の ID を生成する一般的な分散方法は数多くありますが、最も一般的なものは Snowflake アルゴリズム、Didi Tinyid、Meituan Leaf です。スノーフレーク アルゴリズムを例にとると、1 ミリ秒以内に複数の ID を生成できます。
最初のビットは使用されず、デフォルトは0です。41桁のタイムスタンプはミリ秒単位で正確で、69年に対応でき、10桁は機能します。マシン ID の上位 5 桁はデータセンター ID、下位 5 桁はノード ID、12 桁のシリアル番号 各ノードはミリ秒ごとに蓄積され、合計は 2^12 に達することがあります。 4096 ID。
 パーティション化
パーティション化
最初のステップは、テーブルを分割した後の順序番号が一意であることを確認することです。次に、テーブルの分割の問題を考えてみましょう。まず、サブテーブル自体の業務量と増分に基づいて、サブテーブルのサイズを検討します。
たとえば、当社の 1 日あたりの注文量は現在 100,000 件ですが、1 年後には 1 日あたり 100 万件に達すると推定されています。ビジネス属性に応じて、通常は半年以内に注文のクエリをサポートします。半年を超える注文はアーカイブが必要です。
したがって、半年間で 1 日あたり 100 万件の注文に基づくと、個別のテーブルを使用しない場合、注文量は 100 万件に達します。たとえ RT の時間を処理できたとしても、それを受け入れることはできません。経験によれば、1 つのテーブルの数が数百万であればデータベースに負荷はかからないため、テーブルを 256 個のテーブル (1 億 8,000 万/256 ≈ 700,000) に分割するだけで十分です。 512 のテーブルに分割することもできます。次に、ビジネス量がさらに 10 倍増加して 1 日あたり 1,000 万件の注文になった場合、サブテーブル 1024 がより適切な選択となることを考えてください。
半年以上にわたってテーブルを分割し、データをアーカイブした結果、単一テーブル内の 700,000 データは、ほとんどのシナリオに十分に対応できるようになりました。次に、注文番号をハッシュし、256 の剰余を取得して、それがどのテーブルに該当するかを決定します。
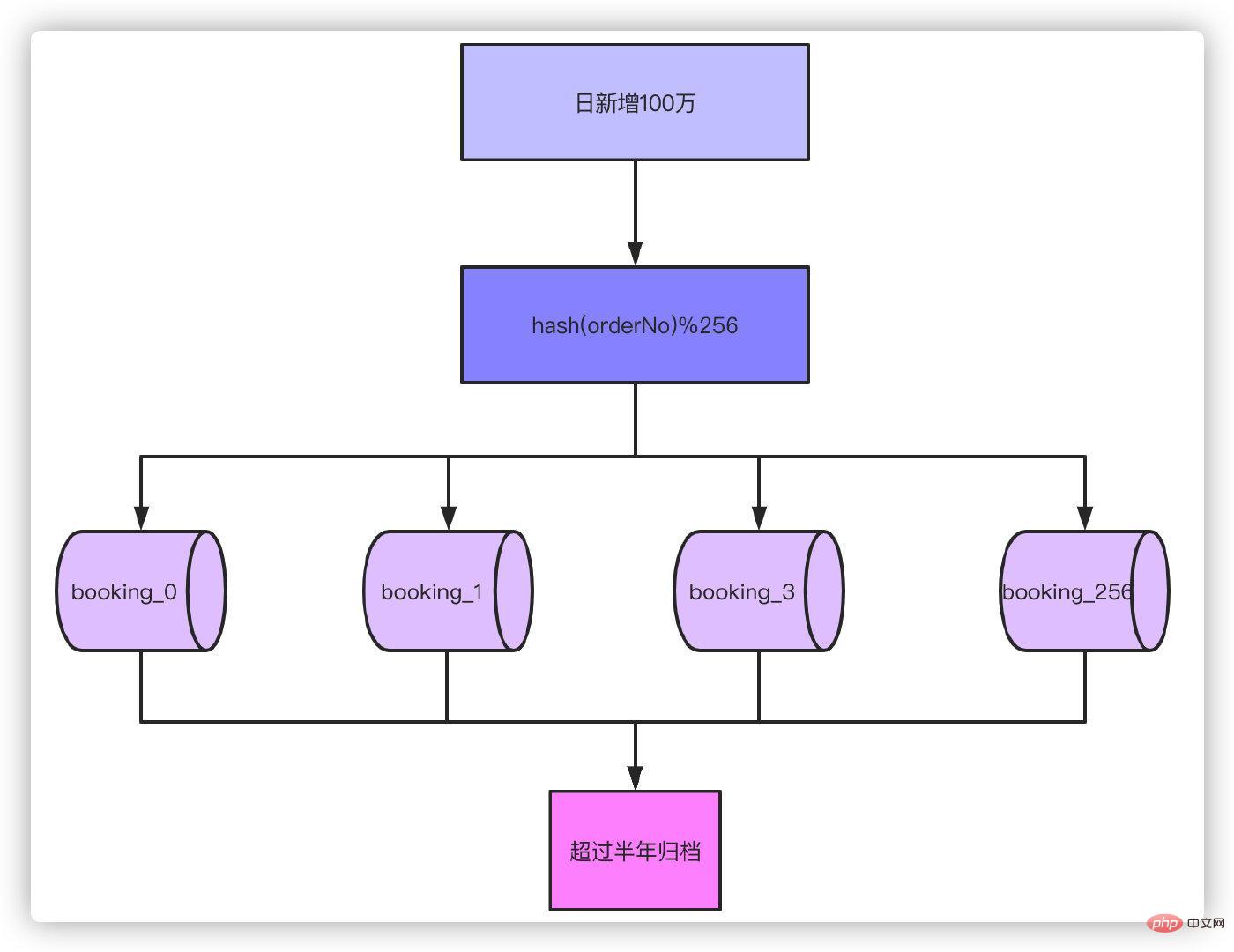 まあ、主キーは注文番号のみなので、過去に主キーIDを元に書いたクエリは使えません。これには履歴が必要です。 . クエリ機能の変更。でも、これは問題ないですよね? 注文番号で確認するように変更すれば大丈夫です。これはどれも問題ではありません。問題はタイトルにあるとおりです。
まあ、主キーは注文番号のみなので、過去に主キーIDを元に書いたクエリは使えません。これには履歴が必要です。 . クエリ機能の変更。でも、これは問題ないですよね? 注文番号で確認するように変更すれば大丈夫です。これはどれも問題ではありません。問題はタイトルにあるとおりです。
C 側クエリ
長々と話してようやく本題に到達したのですが、テーブル分割後のクエリとページングクエリの問題をどうやって解決するのでしょうか?
まず、シャーディング キーを使用したクエリについて説明します。たとえば、注文番号によるクエリです。何をしても、クエリ対象の特定のテーブルを直接見つけることができます。明らかに問題はありません。クエリで。
シャーディング キーではなく、上記の例で注文番号がシャーディング キーとして使用されている場合、APP や小規模なプログラムは通常、ユーザー ID を通じてクエリされます。注文番号を通して?多くの企業の注文テーブルでは、ユーザー ID をシャーディング キーとして直接使用します。これは非常にシンプルで、直接確認できます。では、注文番号はどうすればよいのでしょうか? 非常に簡単な方法は、ユーザー ID 属性を注文番号に追加することです。非常に単純な例を挙げると、元の 41 桁のタイムスタンプを使い切ることはできないと考えます。ユーザー ID は 10 桁です。注文番号生成ルールにはユーザー ID が含まれています。特定のテーブルに入るとき、10 桁のユーザー注文番号のIDハッシュを使用し、注文番号やユーザーIDに関わらずクエリの効果が同じになるように法を計算します。
もちろん、この方法は一例であり、具体的な注文番号の生成ルール、桁数、要素を含めるなどの具体的な内容は、自社のビジネスや実装メカニズムに応じて決定されます。
わかりました。注文番号またはユーザー ID をシャーディング キーとして使用する場合は、上記の 2 つの方法に従って問題を解決できます。次に、別の質問があります。注文番号でもユーザー ID クエリでもない場合はどうすればよいですか?最も直感的な例は、販売者側またはバックエンドからのクエリです。販売者側は、販売者または販売者の ID をクエリ条件として使用します。バックグラウンドでのクエリ条件は、私が遭遇したいくつかのバックグラウンド クエリ条件のように、より複雑になる場合があります。数十個ある可能性があります。確認するにはどうすればよいですか? ? ?心配しないでください。B サイドとバックエンドの複雑なクエリについては個別に説明します。
実際には、実際のトラフィックのほとんどはユーザー側の C 側から来ているため、基本的にユーザー側の問題は解決されます。この問題はほとんど解決され、残りはマーチャントから来ます。売り手側、B側、バックエンドサポート運用業務 クエリトラフィックはそれほど多くないため、この問題は簡単に解決できます。
もう一方のサイド クエリ
B サイドの非シャーディング キー クエリを解決するには 2 つの方法があります。
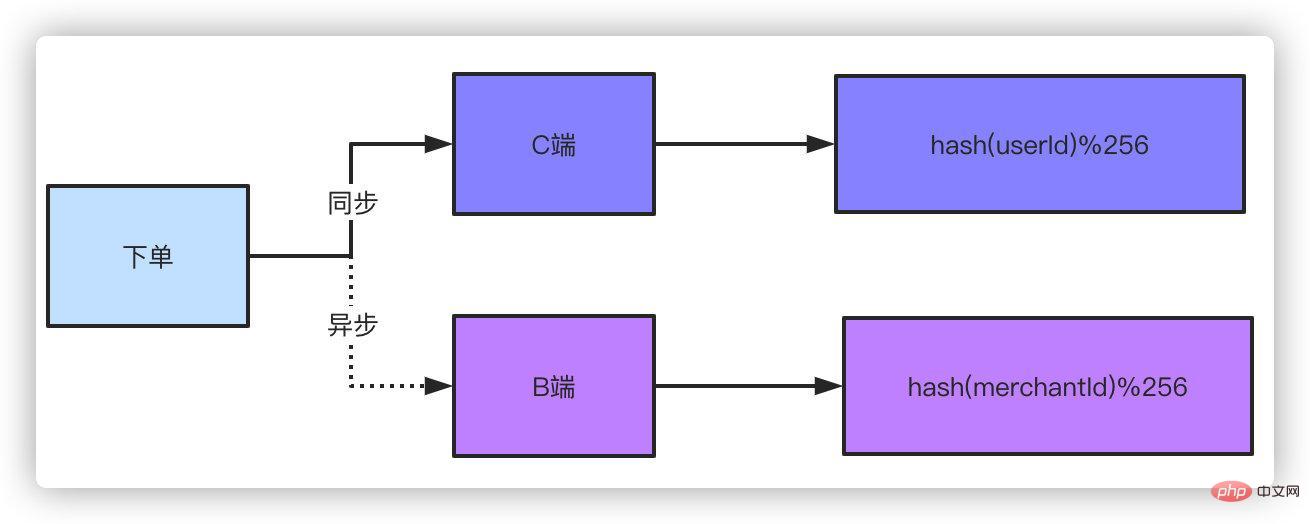
二重書き込み. 二重書き込みとは、注文データが2部に保存されることを意味します。C面とB面に1部ずつ保存されます。C面には注文番号が使用できます。ユーザー ID をシャーディング キーとして使用します。B 側は販売者の販売者の ID をシャーディング キーとして使用できます。クラスメイトの中には、二重に書いてもパフォーマンスに影響しないのではないかと言う人もいます。 B サイドではわずかな遅延が許容されるため、非同期メソッドを使用して B サイドの注文を行うことができます。考えてみてください。タオバオで何かを購入して注文した場合、販売者が注文メッセージを受け取るのが 1 ~ 2 秒遅れても問題ありませんか?注文の受け取りが 1 ~ 2 秒遅れることは、注文した持ち帰り販売店に大きな影響を及ぼしますか?
これは解決策です。別の解決策は、 オフライン データ ウェアハウスまたは ES クエリを使用することです。注文データがデータベースにドロップされた後、 binlog または MQ メッセージを使用する場合、メッセージはすべてデータ ウェアハウスまたは ES にデータを同期する形式になっており、この種のクエリ条件ではサポートされる桁数は非常に単純です。この方法では確かにわずかな遅延が発生しますが、この制御可能な遅延は許容範囲です。
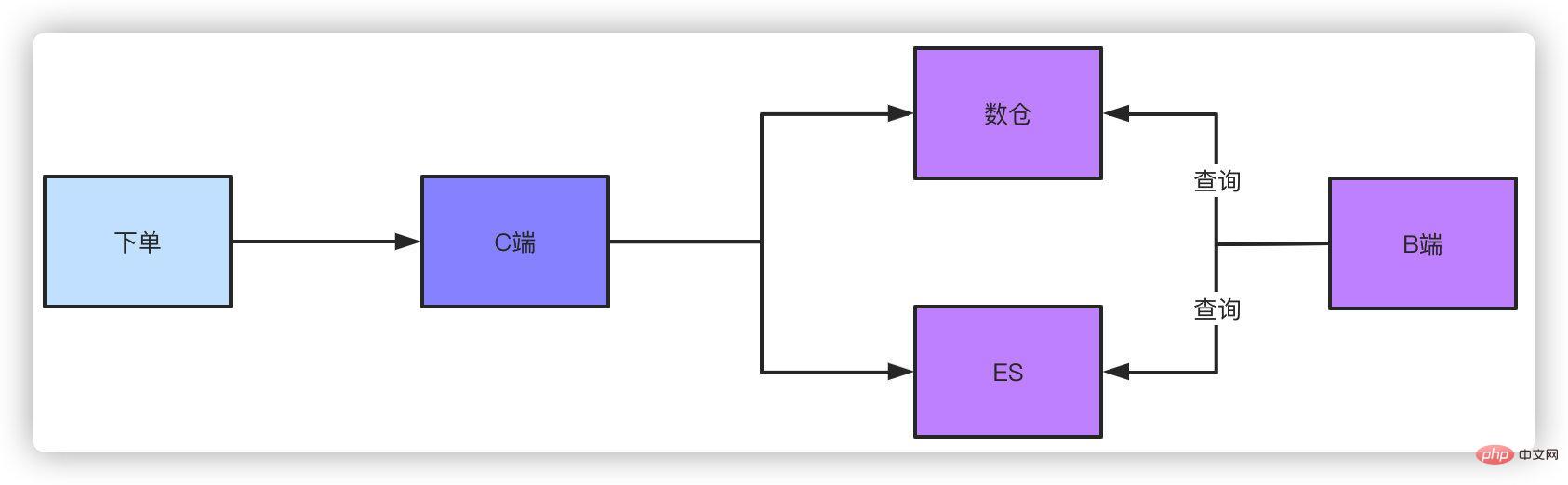
データを確認する必要がある運用、ビジネス、製品などの管理バックエンドでのクエリの場合、当然、複雑なクエリ条件が必要になります。これは、次の方法でも実行できます。 ESとかデータウェアハウスとか。このソリューションを使用せず、シャーディング キーを使用せずにページング クエリを実行する場合、テーブル全体をスキャンして集計データをクエリし、手動でページングを実行することしかできませんが、この方法で得られる結果は限られています。
たとえば、256 個のシャードがある場合、クエリを実行するときにすべてのシャードを周期的にスキャンし、各シャードから 20 個のデータを取得し、最後にデータを集計して手動でページングすると、完全な量のデータ。
概要
データベースとテーブルのパーティショニング後のクエリの問題は、経験豊富な学生には実際に知られていますが、ほとんどの学生はまだこの問題に取り組んでいない可能性があると思います。データベースやテーブルについてはまだ構想段階かもしれませんが、面接で質問されても経験がないので何をすればいいのかわからず戸惑っています。
サブデータベースとサブテーブルは、既存の業務量と将来の増加に基づいて最初に判断されます。たとえば、Pinduoduo の 1 日あたりの注文量が 5,000 万件の場合、半年分のデータはスコアは 4096 テーブルですよね。でも、実際の操作は同じです。あなたのビジネスでは、スコアが 4096 である必要はありません。ビジネスに基づいて合理的な選択をしてください。
シャーディングキーに基づくクエリは簡単に解決できます。シャーディングキー以外のクエリは、データの二重コピー、データウェアハウス、ESをドロップすることで解決できます。もちろん、分割後のデータ量が少なければ、、インデックスを作成してテーブル全体をスキャンしてクエリを実行することは問題ありません。
関連する無料学習の推奨事項: mysql ビデオ チュートリアル
以上が数百億のデータがテーブルに分割された後のページング クエリを理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。