
ホームページ >データベース >mysql チュートリアル >泣く。MySQL インデックスについてはよく知っているつもりだったのに
泣く。MySQL インデックスについてはよく知っているつもりだったのに

- coldplay.xixi転載
- 2020-11-04 17:24:182140ブラウズ
mysql ビデオ チュートリアル 列では実際のインデックスを紹介します。

関連する無料学習の推奨事項: mysql ビデオ チュートリアル
1. インデックスとは何ですか?
リレーショナル データベースでは、インデックスは、データベース テーブル内の 1 つ以上の列の値を並べ替える別個の物理的なストレージ構造であり、1 つまたは複数の列の値のコレクションです。テーブル内: これらの値を物理的に識別する、テーブル内のデータ ページへの論理ポインターのコレクションと対応するリスト。索引は本の目次に相当し、目次のページ番号をもとに必要な内容をすぐに見つけることができます。
テーブル内に多数のレコードがある場合、テーブルに対してクエリを実行する場合、情報を検索する最初の方法は、テーブル全体を検索することです。つまり、すべてのレコードを 1 つずつ取り出します。 1 つ目は、クエリ条件と 1 つずつ比較し、条件を満たすレコードを返すと、データベース システム時間が大量に消費され、大量のディスク I/O 操作が発生します。2 つ目は、テーブルにインデックスを作成することです。次に、インデックス内のクエリ条件を満たすインデックス値を検索し、最後にインデックスに保存します。テーブル内の ROWID (ページ番号に相当) を使用すると、テーブル内の対応するレコードをすばやく見つけることができます。
MySQL5.5 以降の InnoDB ストレージ エンジンで使用されるインデックス データ構造は、主に B Tree を使用します。この記事では、B Tree の過去と現在について説明します。
**マーク**
:
B ツリーは 、>= に使用できます。 、 BETWEEN 、 IN 、および LIKE は、ワイルドカードで始まらない使用インデックスです。 (MySQL 5.5 以降)
これらの事実は、あなたが読んだ他の記事や書籍など、あなたの認識の一部を覆す可能性があります。上記はすべて「範囲クエリ」であり、インデックスは作成されません。
そうです、5.5 より前では、オプティマイザはインデックスを介した検索を選択しませんでした。オプティマイザは、前に戻る必要があるため、この方法で取得される行はテーブル全体のスキャンよりも多いと考えていました。 I/O 行の数が多くなり、オプティマイザによって放棄される可能性があります。
アルゴリズム (B ツリー) の最適化後、一部の範囲タイプのスキャンがサポートされます (B ツリー データ構造の順序性を利用)。このアプローチは、左端の接頭辞の原則にも違反するため、範囲クエリ後の状態では結合インデックスを使用できなくなります。これについては後で詳しく説明します。
2. インデックスの長所と短所
1. 利点
- インデックスにより、サーバーがスキャンする必要があるデータの量が大幅に削減されます
- インデックスは役に立ちます サーバーはソートや一時テーブルを回避します
- インデックスはランダム I/O をシーケンシャル I/O
2 に変えることができます。欠点
- インデックスは大幅に改善されていますが、クエリの速度は向上しますが、テーブルの INSERT、UPDATE、DELETE などのテーブルの更新速度も低下します。テーブルを更新するとき、MySQL はデータを保存するだけでなく、インデックス ファイルも保存する必要があるためです。
- インデックス ファイルを作成すると、ディスク領域が占有されます。一般に、この問題は深刻ではありませんが、大きなテーブルに複数の結合インデックスを作成し、大量のデータを挿入すると、インデックス ファイルのサイズが急速に増大します。
- データ列に繰り返しのコンテンツが多数含まれている場合、インデックスを作成しても実際的な効果はあまりありません。
- 非常に小さなテーブルの場合、ほとんどの場合、単純な全テーブル スキャンの方が効率的です;
したがって、最も頻繁にクエリされ、最も頻繁に並べ替えられるデータ列のみにインデックスを付ける必要があります。 (MySQL では同じデータテーブル内のインデックスの総数は 16 に制限されています)
データベースの存在意義の 1 つは、データの保存と高速な検索を解決することです。では、データベース内のデータはどこに存在するのでしょうか?そうです、ディスクなのですが、ディスクの利点は何ですか?安い!デメリットについてはどうでしょうか?メモリアクセスより遅い。
では、主に MySQL インデックスで使用されるデータ構造をご存知ですか?
B木!あなたは口走ってしまった。
B ツリーとはどのようなデータ構造ですか? MySQL がインデックスに B ツリーを選択したのはなぜですか?
実際、B ツリーの最終的な選択は、長い進化のプロセスを経ました:
友人に「B-Tree と B-Tree の違いは何ですか?」と尋ねられました。ツリーとBツリーは?」ここで一般化すると、MySQL のデータ構造には B-Tree (B ツリー) と B Tree (B ツリー) しかありません。それらのほとんどは単に発音が違うだけです。「B-Tree」は一般的に B ツリーと呼ばれます。B と呼ぶこともできます。 -tree~ ~ また、友人が言及した赤黒ツリーは、MySQL ではなくプログラミング言語の記憶構造です。たとえば、Java の HashMap はリンク リストと赤黒ツリーを使用します。 さて、今日は B ツリーに進化するプロセスについて説明します。##バイナリ ソート ツリー → バイナリ バランス ツリー → B-Tree(B ツリー) → B Tree(B ツリー)
3. B Tree の過去と現在 インデックス
1. 2 値ソート ツリー
B ツリーを理解する前に、2 値ソート ツリーについて簡単に説明します。 , その左の子 ツリーの子ノードの値はそれ自体より小さくなければならず、その右のサブツリーの子ノードの値はそれ自体より大きくなければなりません。すべてのノードがこの条件を満たす場合、それはバイナリソートされたツリーです。 。 (ここで二分探索の知識をつなげることができます) 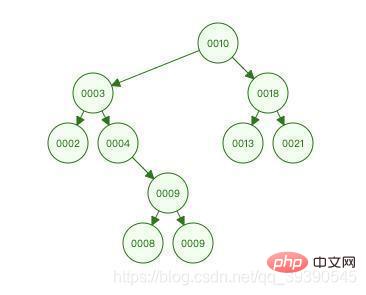
上の図は二分ソートツリーですが、その特徴を利用して9を見つける過程を体験してみてください。
- ##9 は 10 より小さいので、その左側のサブツリー (ノード 3) に移動して
- 9 が 3 より大きいことを確認し、ノード 3 の右側のサブツリー (ノード ) に移動します。 4)
- 9 が 4 より大きいことを確認するには、ノード 4 (ノード 9) の右のサブツリーに移動して、
- ノード 9 が 9 に等しいことを確認します。検索は成功します。
- 9 は 4 より大きいので、その右のサブツリーに移動して
- を見つけます#9 は 10 より小さいので、その左側のサブツリーで
- ノード 9 と 9 を検索します。これらは等しいため、検索は成功します。
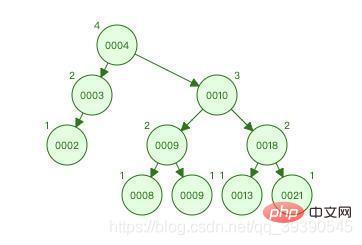
B ツリーの特徴:
- すべてキー値はツリー全体に分散されます
- キーワードは 1 つのノードにのみ表示されます
- #検索はリーフ ノード以外で終了する可能性があります ##検索が実行されますキーワードの完全なセット内で、二分探索アルゴリズムに近いパフォーマンス
- 効率を向上させるには、ディスク I/O の数をできるだけ減らす必要があります。実際のプロセスでは、ディスクは毎回厳密にオンデマンドで読み取られるのではなく、毎回先読みされます。
- B ツリーはコンピューターのディスク先読みメカニズムを使用します:
- 新しいノードが作成されるたびに、1 ページのスペースが適用されるため、ノードが作成されるたびに、実際のアプリケーションではノードの深さが非常に小さいため、検索効率が非常に高くなります。
- では、B ツリーの最終バージョンはどのように作成されるのでしょうか?
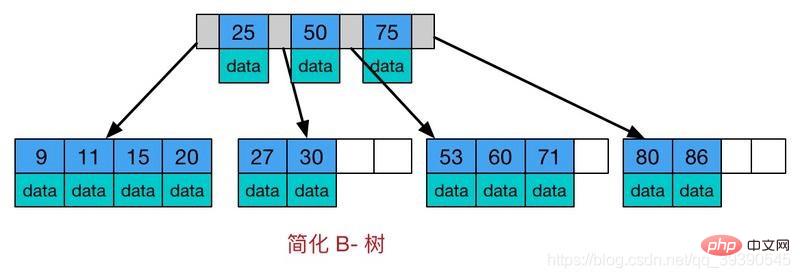
4. B ツリー (B ツリーは B ツリーの変形であり、マルチパス検索ツリーでもあります)
画像からもわかります、B ツリーと B ツリーの違いは次のとおりです: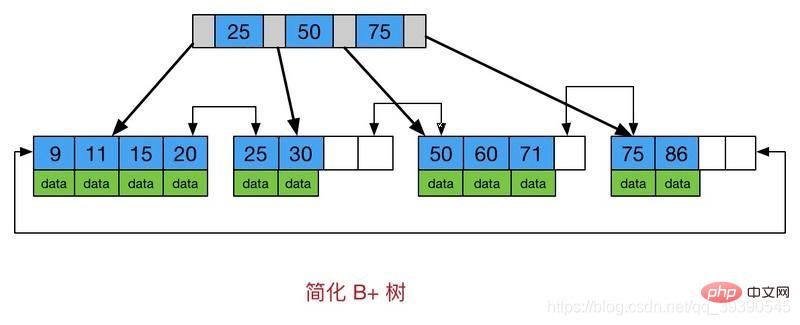 すべてのキーワードはリーフ ノードに格納されます
すべてのキーワードはリーフ ノードに格納されます
- すべてのリーフ ノードにチェーン ポインタを追加します
- 。これは、すべての値が順番に格納され、各リーフ ページからルートまでの距離が同じであることを意味します。範囲データの検索に非常に適しています。 ** したがって、B ツリーでは、ワイルドカード文字で始まらない 、>=、BETWEEN、IN、および LIKE のインデックスを使用できます。 **
- B ツリーの利点: 比較数のバランスが取れ、I/O 数が削減され、検索速度が向上し、検索がより安定します。
- B ツリーのディスク読み取りおよび書き込みコストは低いです。
- B ツリーのクエリ効率はより安定しています。
知っておく必要があるのは、毎回のことです。テーブルを作成すると、システムはすべてのデータを保存するための ID ベースのクラスター化インデックス (前述の B ツリー) を自動的に作成します。インデックスを追加するたびに、データベースは追加のインデックス (前述の B-tree) であり、インデックスによって選択されるフィールドの数はそれぞれノード格納データのインデックスの数ですが、このインデックスにはすべてのデータが格納されるわけではないことに注意してください。
4. MySQL がインデックスに B ツリーではなく B ツリーを選択するのはなぜですか?
- B ツリーは外部ストレージ (通常はディスク ストレージ) に適しています。内部ノード (非リーフ ノード) はデータを格納しないため、1 つのノードにさらに多くの内部ノードを格納でき、各ノードはインデックス付き 範囲がより広く、より正確になります。つまり、B-tree を使用した場合、1 回のディスク I/O の情報量が B-tree よりも多くなり、I/O 効率が高くなります。
- Mysql はリレーショナルデータベースであり、インデックスカラムは間隔に応じてアクセスされることが多く、B ツリーの葉ノード間にリンクポインタが順番に確立され、間隔アクセスが強化されるため、B ツリーはhas Interval 範囲クエリはフレンドリーです。 B-treeの各ノードのキーとデータが一緒になっているため、区間検索はできません。
5. プログラマの皆さん、知っておくべきインデックスの知識ポイント
1. テーブルの戻りクエリ
たとえば、name、age インデックス name_age_index を作成する場合、クエリを実行します。データ
select * from table where name ='陈哈哈' and age = 26; 1复制代码
が使用されるのは、追加インデックスに名前と年齢のみがあるためです。したがって、インデックスにヒットした後、データベースは他のデータを見つけるためにクラスター化インデックスに戻る必要があります。これがテーブル リターンです。これは、また、あなたが覚えているもの: use less * を選択した理由。
2. インデックス カバレッジ
戻りテーブルと組み合わせると、よりよく理解できるようになります。たとえば、上記の name_age_index インデックスには、クエリ
select name, age from table where name ='陈哈哈' and age = 26; 1复制代码
At今回は、選択したフィールド名、インデックス内の年齢が取得できるため、テーブルに戻る必要がなく、インデックスカバレッジを満たし、インデックス内のデータが直接返されるため、非常に効率的です。これは、DBA 学生が最適化を行う場合に推奨される最適化方法です。
3. 左端プレフィックスの原則
B ツリーのノード格納インデックスの順序は左から右に格納されており、マッチングの際には左から右のマッチングを満たすのが自然です。通常、作成するとき 共同インデックスを作成するとき、つまり、複数のフィールドにインデックスを作成するとき インデックスを作成した学生は、Oracle と MySQL の両方でインデックスの順序を選択できることがわかると思います。たとえば、3 つのフィールドにインデックスを付けたいとします。 、b、および c。結合インデックスを作成するには、 必要な優先順位を、a、b、c または b、a、c または c、a、b などの順序で選択できます。 なぜデータベースではフィールドの順序を選択できるのでしょうか?どれも3分野の結合インデックスではないでしょうか?これは、データベース インデックスの左端のプレフィックスの原則につながります。
私たちの開発では、このフィールドに対して結合インデックスが構築されているにもかかわらず、SQL がこのフィールドをクエリするときにインデックスが使用されないという問題がよく発生します。たとえば、インデックス abc_index: (a, b, c) は、3 つのフィールド a、b、c の結合インデックスです。次の SQL を実行すると、インデックス abc_index にヒットできません。
select * from table where c = '1'; select * from table where b ='1' and c ='2'; 123复制代码
次の 3 つの状況では、インデックスが失われます。:
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3'; 12345复制代码
上の 2 つの例から何か手がかりはありますか?
はい、インデックス abc_index: (a,b,c) は、(a)、(a,b)、(a,b,c) の 3 種類のクエリでのみ使用されます。実際、ここには少しあいまいさがあり、実際には (a,c) も使用されますが、a フィールドのインデックスのみが使用され、c フィールドは使用されません。
また特殊な場合があり、以下の型の場合はaとbのみインデックスされ、cはインデックスされません。
select * from table where a = '1' and b > '2' and c='3'; 1复制代码
上記のタイプの SQL ステートメントの場合、a と b のインデックスが作成された後、c はすでに順序が狂っているため、c のインデックスを作成できず、オプティマイザは c が順序どおりではないと判断します。完全なインデックスとして優れており、テーブル スキャン C フィールドはすぐに表示されます。
**左端のプレフィックス: 名前が示すとおり、左端が最初であることを意味します。上の例では、a_b_c 複数列インデックスを作成しました。これは、(a) 単一列インデックスと ( a、b) 結合インデックス、および (a、b、c) 結合インデックス。 **
したがって、複数列のインデックスを作成する場合は、ビジネス ニーズに応じて、where 句で最も頻繁に使用される列を左端に配置する必要があります。
4. インデックス プッシュダウンの最適化
またはインデックス name_age_index、次の SQL
select * from table where name like '陈%' and age > 26; 1复制代码
このステートメントには 2 つの実行可能性があります:
- name_age_index をヒットします。ジョイント インデックスは、「陈」で始まる名前を満たすすべてのデータをクエリし、テーブルに戻って、条件を満たすすべての行をクエリします。
- name_age_index ジョイント インデックスをヒットし、名前が「Chen」で始まるすべてのデータをクエリしてから、age > 20 のインデックスをフィルターで除外してから、テーブルに戻ってデータの行全体をクエリします。
明らかに、2 番目のメソッドはテーブルに返す行が少なくなり、I/O の数も減ります。これはインデックス プッシュダウンです。したがって、すべての「いいね!」がインデックスにヒットしないわけではありません。
6. インデックス使用時の注意事項
1. インデックスには null 値の列は含まれません
列に null 値が含まれている限り、インデックスは含まれません。インデックスでは、複合インデックス内の 1 つの列に NULL 値が含まれている限り、この列は複合インデックスに対して無効になります。したがって、データベースを設計する際には、フィールドのデフォルト値を null にしないことをお勧めします。
2、使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
3、索引列排序
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
4、like语句操作
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%陈%” 不会使用索引而like “陈%”可以使用索引。
5、不要在列上进行运算
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<h2 data-id="heading-21">6、不使用not in和操作</h2><p>这不属于支持的范围查询条件,不会使用索引。</p><h1 data-id="heading-22">我的体会</h1><p> 曾经,我一度以为我很懂MySQL。</p><p> 刚入职那年,我还是个孩子,记得第一个需求是做个统计接口,查询近两小时每隔5分钟为一时间段的网站访问量,JSONArray中一共返回24个值,当时菜啊,写了个接口循环二十四遍,发送24条SQL去查(捂脸),由于那个接口,被技术经理嘲讽~~表示他写的SQL比我吃的米都多。虽然我们山东人基本不吃米饭,但我还是羞愧不已。。<br>然后经理通过调用一个dateTime函数分组查询处理一下,就ok了,效率是我的几十倍吧。从那时起,我就定下目标,深入MySQL学习,万一日后有机会嘲讽回去?</p><p> 筒子们,MySQL路漫漫,其修远兮。永远不要眼高手低,一起加油,希望本文能对你有所帮助。</p>
以上が泣く。MySQL インデックスについてはよく知っているつもりだったのにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。