


相関ルール アプリオリ アルゴリズムを理解する: アプリオリ アルゴリズムは、最初の相関ルール マイニング アルゴリズムであり、最も古典的なアルゴリズムです。レイヤーごとの検索の反復方法を使用して、データベース内のアイテム セット間の関係を見つけて、フォーム ルール プロセスは、接続 [行列のような操作] とプルーニング [不要な中間結果の削除] で構成されます。

相関ルール先験アルゴリズムを理解します:
1. 概念
表 1 スーパーマーケットの取引データベース
取引番号 TID |
顧客が購入した商品 |
トランザクション番号 TID |
顧客が購入した商品 |
|||||||||||||||||
|
T1 |
パン、クリーム、ミルク、紅茶 |
T6 |
パン、紅茶 | |||||||||||||||||
T2 |
パン、クリーム、牛乳 |
T7 |
ビール、牛乳、お茶 |
|||||||||||||||||
T3 |
ケーキ、牛乳 | T8 |
パン、お茶 |
|||||||||||||||||
| ##T4 | 牛乳、紅茶 | ##T9#パン、クリーム、牛乳、紅茶 | #T5 | |||||||||||||||||
パン、ケーキ、牛乳 |
T10 |
パン、牛乳、 お茶############### 定義 1: I={i1,i2,…,im} とします。これは、m 個の異なる項目のセットであり、各 ik は呼び出されます。 プロジェクトの場合。アイテムのコレクション I は itemset と呼ばれます。その要素の数はアイテムセットの長さと呼ばれ、長さ k のアイテムセットは k アイテムセットと呼ばれます。この例では、各製品は項目であり、項目セットは I={パン、ビール、ケーキ、クリーム、牛乳、紅茶}、I の長さは 6 です。 定義 2: 各 トランザクションT は、設定したアイテムセットの子です。 。各トランザクションに対応して、一意の識別トランザクション番号があり、TID として記録されます。すべてのトランザクションは トランザクション データベースD を構成し、|D| は D 内のトランザクションの数に等しくなります。この例には 10 個のトランザクションが含まれているため、|D|=10 となります。 定義 3: 項目セット #XX の場合、count(X⊆T) をトランザクション セット D 数量に X を含むトランザクションの数に設定します。の場合、項目セット X の サポート は次のようになります: support(X)=count(X⊆T)/|D| #この例では、#XX={パン, ミルク} が T1、T2、T5、T9、および T10 に出現するため、サポートは 0.5 になります。定義 4 : 最小サポート はアイテムセットの最小値です。サポートしきい値は SUPmin として記録され、ユーザーが関心を持つ関連付けルールの最小重要性を表します。 サポートが SUPmin 以上である項目セットは頻出セット と呼ばれ、長さ k の頻出セットは k 頻度セットと呼ばれます。 SUPmin が 0.3 に設定されている場合、この例の {bread, Milk} のサポートは 0.5 であるため、2 度数セットになります。 定義 5: 関連付けルール は暗黙的です:#R:X⇒Y ここで、X⊂I、Y⊂I、X∩Y=⌀。あるトランザクションでアイテムセット X が出現すると、一定の確率で Y も出現することを示します。ユーザーが気にする関連付けルールは、サポートと信頼性という 2 つの基準で測定できます。 定義 6 : 相関ルール R の サポートはトランザクションです。 X と Y の両方を含むセットを |D| にします。つまり: support(X⇒Y)=count(X⋃Y)/|D|サポートは、XX と Y が同時に出現する確率を反映します。時間。相関ルールのサポートは、頻出セットのサポートと同等です。 定義 7 : 相関ルール R の場合、 credibility を参照します#XX と Y を含むトランザクションの数と、X を含むトランザクションの数の比率。つまり: confidence(X⇒Y)=support(X⇒Y)/support(X)Confidence は、トランザクションに XX が含まれている場合、 then トランザクションに Y が含まれる確率。一般に、ユーザーにとって関心があるのは、高いサポートと信頼性を備えた相関ルールのみです。 定義 8 : 関連付けルールの最小サポートと最小信頼性を SUPmin および CONFmin として設定します。ルール R の支持と信頼性が SUPmin と CONFmin 以上である場合、それは強相関ルール と呼ばれます。相関ルール マイニングの目的は、販売者の意思決定を導くための強力な相関ルールを見つけることです。これらの 8 つの定義には、相関ルールに関連するいくつかの重要な基本概念が含まれています。相関ルール マイニングには 2 つの主な問題があります:
現在、研究者は主に最初の問題に焦点を当てており、頻出集合を見つけることは困難ですが、頻出集合との強い相関ルールを生成することは比較的簡単です。
2. 理論的根拠 まず、頻度集合の性質を見てみましょう。 #定理: 項目セット #XX が頻出セットの場合、その空でないサブセットはすべて頻出セットになります 。 定理によれば、k 頻度集合の項目集合 X が与えられた場合、k-1 次のすべての部分集合は、2 つの k-1 頻度集合の項目集合は次の点のみ異なります。 1 つの項目であり、接続後は X に等しくなります。これは、k−1個の頻度集合を連結することによって生成されたk候補集合が、k頻度集合をカバーすることを証明する。同時に、k-候補集合内の項目集合 Y に、k-1 頻出集合に属さない k-1 次のサブセットが含まれている場合、Y は頻出集合であるはずがないため、候補集合から取り除く必要があります。 Apriori アルゴリズムは、この頻繁なセットの特性を利用します。 3. アルゴリズムのステップ:最初はテスト データです:
|
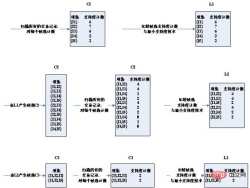
以上が相関規則アプリオリアルゴリズムを理解する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python:自動化、スクリプト、およびタスク管理Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理Apr 16, 2025 am 12:14 AMPythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用するApr 14, 2025 am 12:02 AM限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなどApr 13, 2025 am 12:14 AMPythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

メモ帳++7.3.1
使いやすく無料のコードエディター

