
ホームページ >データベース >mysql チュートリアル >InnoDB のチェックポイント テクノロジーを理解する
InnoDB のチェックポイント テクノロジーを理解する

- coldplay.xixi転載
- 2020-10-28 17:14:332661ブラウズ
mysql 教程 目録の大家は InnoDB のチェックポイント テクニックを熟知しています。

一句概要、チェックポイント テクニックつまり、ある時点で保存池内の点刷りを磁盘に戻す操作
評価された問題?
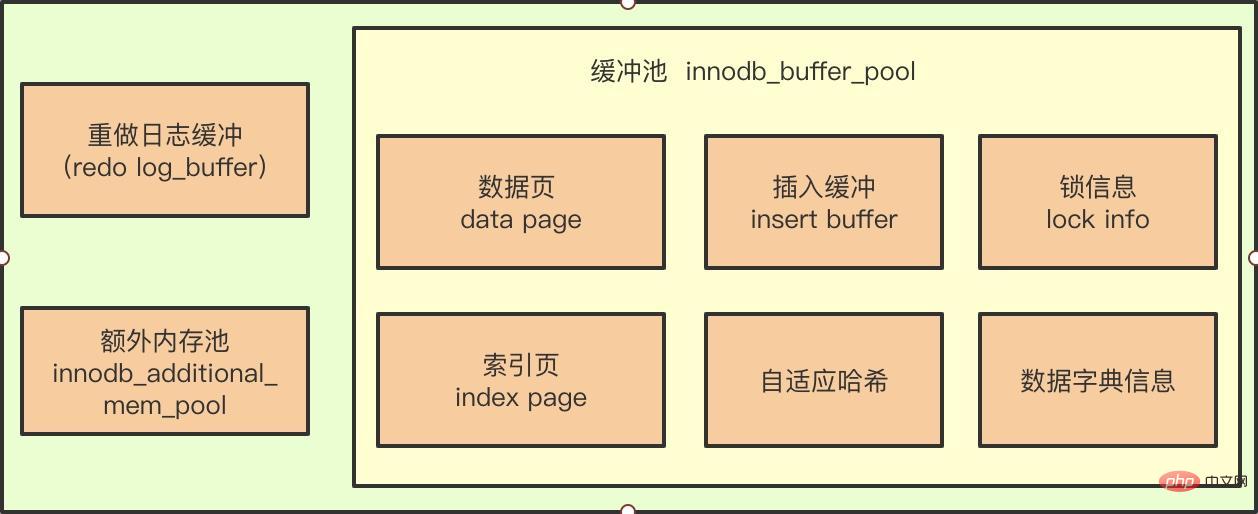
都知道缓冲セルの発生は、CPU とマグネティックの速度の間の混乱を認識するためであり、これにより、データの書き込み中にマグネティックス IO 操作を実行する必要がなくなりました。
#DML の例のように、データの更新または削除操作を実行すると、冷却セルのデータが磁場よりも新しいため、このときの設定が変更されます。 不管怎样、会議後の内部保存データは磁盘里に戻る必要があります、ここに就涉及几个问题:- 若每次一页発行变化、就将新页のバージョンが磁盘に新しく到着しました。那么この销は非常に大きいです
- 若熱量データが特定の場所に集中しており、那么データ プールのパフォーマンスは非常に差が得られます
- 結果的には、池将页の新しいバージョンの刷新が磁盘に到着したとき、完了机が発生しました、那么データ就は恢了できません
redo log
,每当有事务提交時,先書入redo log(重做日志),在修改缓冲池データ页,这样電気が発生した場合、システムは再実行後に操作を続行できます。WAL ポリシー機構の原理
障害が発生してメモリ データが失われた場合、InnoDB は再起動時に REDO ログを再生することでバッファ プール データ ページをクラッシュ前の状態に復元します。
チェックポイント
WAL戦略を使えば、座ってリラックスできるのは当然です。しかし、REDO ログで問題が再び発生します。アイドル状態で復元されます。REDO ログが大きすぎる場合、リカバリのコストも非常に高くなります。
- では、ダーティ ページのリフレッシュ パフォーマンスを解決するには、いつ、どのような状況で行う必要がありますか?ダーティ ページを更新する必要がありますか? 更新にはチェックポイント テクノロジが使用されます。
- チェックポイントの目的
1. データベースの復旧時間を短縮します
データベースがアイドル状態で復元されると、やり直しの必要がありません。すべてのログ情報。チェックポイント前のデータ ページがディスクにフラッシュ バックされているためです。チェックポイントの後に REDO ログを復元するだけです。2. バッファー プールが十分でない場合は、ダーティ ページをディスクにフラッシュします。
バッファー プールのスペースが不十分な場合、最も最近使用されていないページが、このページがダーティ ページである場合、チェックポイントにダーティ ページ、つまりページの新しいバージョンを強制的にフラッシュしてディスクに戻す必要があります。3. REDO ログが利用できない場合は、ダーティ ページを更新します
図に示すように、REDO ログは現在のデータベースが使用できないため、デザインはすべてリサイクルされるため、スペースは無限ではありません。
REDO ログがいっぱいになると、現時点ではシステムが更新を受け入れることができないため、すべての更新ステートメントがブロックされます。 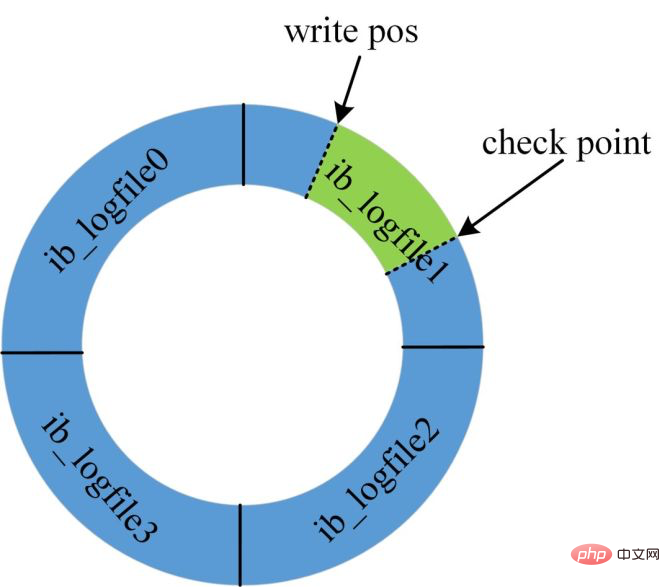
上記の問題に直面して、InnoDB ストレージ エンジンは内部的に 2 つのチェックポイントを提供します。
Sharp Checkpoint
データベースがシャットダウンされ、すべてのダーティ ページがディスクにフラッシュされます。これがデフォルトの動作方法です。パラメータ innodb_fast_shutdown=1- Fuzzy Checkpoint InnoDB ストレージ エンジン このモードを使用すると、すべてのダーティ ページをディスクにフラッシュするのではなく、一部のダーティ ページのみがフラッシュされます
-
#FuzzyCheckpoint で何が起こるか##
ほぼ毎秒または 10 秒ごとに、バッファ プール内のダーティ ページ リストから特定の割合のページをディスクにフラッシュします。
このプロセスは非同期です。つまり、InnoDB ストレージ エンジンはこの時点で他の操作を実行でき、ユーザー クエリ スレッドはブロックされません- FLUSH_LRU_LIST チェックポイント LRU リストでは一定数の空きページを使用できるようにする必要があるため、空きページが不足した場合は末尾からページが削除され、削除されたページにダーティ ページがある場合にこのチェックポイントが実行されます。 バージョン 5.6 以降、このチェックポイントは別のページ クリーナー スレッドに配置され、ユーザーはパラメータ innodb_lru_scan_ Depth を通じて LRU リスト内の使用可能なページの数を制御できます。デフォルト値は 1024
- 非同期/同期フラッシュ チェックポイント は、REDO ログ ファイルが利用できない状況を指します。現時点では、一部のページを強制的にディスクにフラッシュする必要があり、ダーティ ページはダーティ ページ リストから削除されました。選択された 5.6 バージョンはユーザー クエリをブロックしません
- ダーティ ページが多すぎるチェックポイント つまり、ダーティ ページの数が多すぎるため、InnoDB ストレージ エンジンがチェックポイントを強制します。 一般的な目的は、バッファ プール内に十分な使用可能なページがあることを確認することです。 パラメータ innodb_max_dirty_pages_pct で制御できます。たとえば、値は 75 で、バッファ プール内のダーティ ページが 75% を占めると、CheckPoint が強制的に実行されることを意味します。
-
#概要
CPU とディスクの間にギャップがあるため、バッファー プール データ ページはデータベース DML 操作を高速化するようです
- バッファ プールのダーティ ページのリフレッシュ パフォーマンスの問題のため、チェックポイントテクノロジーの登場
- InnoDB 実行効率を向上させるために、すべての DML 操作は永続化のためにディスクと対話しません。代わりに、最初に先行書き込みログを使用して REDO ログを書き込み、内容の永続性を確保します。 トランザクションで変更されたバッファ プールのダーティ ページの場合、ディスクは非同期でフラッシュされ、メモリ空きページと REDO ログの可用性はチェックポイント テクノロジによって保証されます。
#その他の関連する無料学習の推奨事項:
(ビデオ)
以上がInnoDB のチェックポイント テクノロジーを理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。