
Redis の原理と実装を分析する

- 藏色散人転載
- 2020-10-22 17:55:342677ブラウズ
次のコラムでは、Redis チュートリアルRedis の原理と実装の分析を紹介します。必要としている友達に役立つようにしてください。
1 redis とは
redis は nosql (これも巨大なマップです) シングルスレッドですが、1 秒で 100,000 の同時実行を処理できます (データはすべてメモリ内にあります)
java を使用して redis を操作することは、mysql の jdbc インターフェース標準に似ています。それを実装するさまざまな実装クラスがあります。私たちが一般的に使用するのは druid です。
redis の場合、通常は Jedis を使用します (接続プールも提供します) JedisPool)
redis では、キーは byte[](string)
redis データ構造 (値):
String,list,set,orderset,hash
2 redis の使用
最初に redis をインストールして実行し、pom ファイルに依存関係を導入し、redis によってキャッシュされるクラスの mapper.xml ファイルに redis の完全修飾名を構成します。 。 redis の redis.properties ファイルを導入します (構成を変更したい場合に使用できます)
アプリケーション シナリオ:
文字列:
1Storage json 型オブジェクト、2Counters、3Youku 動画のいいねなど.
list (二重リンク リスト)
1 Redis のリストを使用して、キュー、ヒープ、スタックをシミュレートできます
2 友達のサークル内のいいね (友達のサークル内のコンテンツ ステートメント、いくつかの同様のステートメント)
プロビジョン:友達のサークル内のコンテンツの形式:
1、コンテンツ: user:x:post:x 保存するコンテンツ;
2, likes: post:x:good list to store; (put 対応するアバターを取り出して表示)
hash(hashmap)
1 オブジェクトを保存
2 グループ化
#3 文字列とハッシュのデータの違い
ネットワーク送信中、ネットワーク送信を実行する前にシリアル化を実行する必要があります。文字列型を使用すると、関連するシリアル化が必要になり、ハッシュも必要になります。関連するシリアル化が必要になるため、大量のシリアル化が発生します。保存する場合、ハッシュをより豊富に保存できますが、デシリアライズする場合、文字列のデシリアライズは比較的低く、ハッシュのシリアル化と逆シリアル化は比較的低いです。ハッシュ クラスよりも複雑であるため、ビジネス シナリオによっては、データが頻繁に変更される場合は、パフォーマンスのために文字列を使用できます。データが頻繁に変更されない場合は、パフォーマンスを向上させるために文字列を使用できます。ハッシュを使用できます。ハッシュはデータの保存に優れているため、さまざまなデータ型を保存できます。
4 Redis 永続化メソッド:
にデータを書き込むことができます。メモリをハード ディスクに非同期で保存します。2 つの方法: RDB (デフォルト) と AOF
RDB 永続化の原則: bgsave コマンドによってトリガーされ、親プロセスが fork 操作を実行して子プロセスを作成します。 RDB ファイルを作成し、親プロセスのメモリに基づいて一時スナップショット ファイルを生成します 完了後、元のファイルをアトミックに置き換えます (スケジュールされたすべてのデータの 1 回限りのスナップショットでコピーを生成し、ハードディスクに保存します)
利点: コンパクトで圧縮されたバイナリ ファイルであるため、Redis は RDB をロードして、AOF 方法よりもはるかに高速にデータを復元します。
短所: RDB を毎回生成するオーバーヘッドが大きいため、非リアルタイム永続性、
AOF 永続性の原則: オンにした後、Redis はコマンドを実行するたびにこのコマンドを追加します。データを AOF ファイルに変更するコマンド。
利点: リアルタイムの永続性。
欠点: したがって、AOF ファイルのサイズは徐々に大きくなり、ファイル サイズを減らして読み込みを遅くするには、定期的な書き換え操作が必要になります。
5 なぜ Redis はシングル スレッドなのでしょうか? fast?
Redis はシングルスレッドですが、なぜまだこんなに速いのでしょうか?
理由 1: スレッド間の競合を避けるためにシングルスレッドです
理由 2: メモリ内にある はい、メモリを使用するとディスク IO を削減できます
理由 3: 多重化モデルはバッファーとセレクター モデルの概念を使用します
6 Redis マスターがハングするのはなぜですかアップ? 操作
redis はセンチネル モードを提供します。マスターがハングアップしたとき、他の人を代わりに選択できます。センチネル モードの実装原理は、3 つのスケジュールされたタスクを監視することです。
6.1 10 秒ごと、各 S ノード (センチネル ノード) は、最新のトポロジ構造を取得するために、マスター ノードとスレーブ ノードに info コマンドを送信します。
6.2 2 秒ごとに、各 S ノードは、マスターの S ノードの判断を送信します。ノードを特定のチャネルに送信します。現在の S1 ノードの情報と同様に、
同時に、各センチネル ノードもこのチャネルにサブスクライブして、他の S ノードとマスター ノードの判断について学習します。 (オフラインの客観的な基準として)
6.3 1 秒ごとに、各 S ノードはハートビート検出 (ハートビート検出メカニズム) のためにマスター ノード、スレーブ ノード、および他の S ノードに ping コマンドを送信し、ハートビート検出が行われているかどうかを確認します。これらのノードは現在到達可能です
ハートビートが 3 回検出された後、投票が行われ、投票の半分以上が受け取られた場合、ノードはマスターとみなされます
7 redis クラスター
redis クラスターは 3.0 以降で Ruby を提供します。スクリプトが構築され、粗さの概念が導入されます。
Redis クラスター内のノードは、ピンポン メッセージを通じてノード通信を実現します。メッセージはノード スロット情報を伝播するだけでなく、マスター/スレーブ ステータス、ノード障害などの他のステータスも伝播します。したがって、障害発見もメッセージ伝播メカニズムを通じて実現されます。主なリンクには、主観的オフライン (pfail) と客観的オフライン (fail) が含まれます。
主観的オフラインと客観的オフライン:
主観的オフライン: 組織内の各人クラスタ ノードは定期的に他のノードに ping メッセージを送信し、受信ノードは応答として pong メッセージを返します。通信が失敗し続ける場合、送信ノードは受信ノードを主観的にオフライン (pfail) としてマークします。
目標オフライン: 半分以上、マスター ノードは客観的にオフラインになります。
マスター ノードは、特定のマスター ノードをフェールオーバーのリーダーとして選択します。
フェイルオーバー (新しいマスター ノードとしてスレーブ ノードを選択)
8 メモリ削除戦略
Redis のメモリ削除戦略とは、Redis で使用されるキャッシュを指します。メモリが不足しており、新たに書き込む必要があり追加の領域アプリケーションが必要なデータを処理する方法。
noeviction: メモリが新しく書き込まれたデータを収容するのに不十分な場合、新しい書き込み操作はエラーを報告します。
allkeys-lru: 新しく書き込まれたデータを格納するにはメモリが不十分な場合、キー空間で、最も最近使用されていないキーを削除します。
allkeys-random: メモリが新しく書き込まれたデータを収容するのに不十分な場合、キーはキー空間からランダムに削除されます。
volatile-lru: 新しく書き込まれるデータを格納するにはメモリが不十分な場合、有効期限が設定されたキー空間で、最も最近使用されていないキーを削除します。
volatile-random: メモリが新しく書き込まれたデータを収容するのに不十分な場合、有効期限が設定された状態でキーがキー空間からランダムに削除されます。
volatile-ttl: メモリが新しく書き込まれたデータを収容するのに不十分な場合、有効期限が設定されたキー空間では、有効期限が早いキーが最初に削除されます。 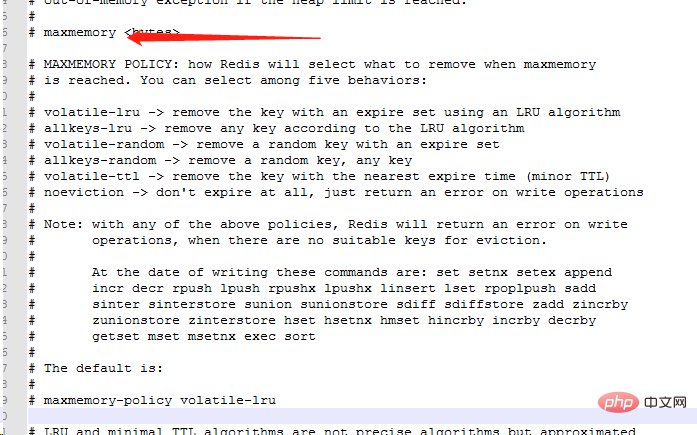
9 キャッシュ故障の解決策:
理由: 他の人がデータをリクエストした場合、多くのデータはキャッシュ内でクエリできないため、データ クエリを直接入力します。
解決策は、関連データをクエリする場合にのみキャッシュにクエリを実行することです。特殊なデータの場合は、データベースにクエリを実行できます。
## ブルーム フィルタを使用してクエリを実行することもできます 10 キャッシュなだれの解決策: キャッシュなだれの原因: 一度にキャッシュに追加されるデータが多すぎるため、メモリが過剰になり、メモリ使用量に影響し、サービスのダウンタイムが発生します解決策: 1 redis クラスター、クラスタリングを通じてデータを配置する 2 バックエンド サービスの低下と電流制限: インターフェイスが何度も要求されると、追加されるデータが多すぎます、サービスはフローを制限し、アクセス数を制限することで、問題の発生を減らすことができます。
以上がRedis の原理と実装を分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。