
ホームページ >データベース >mysql チュートリアル >MySQL についての私の理解の 1 つは、インフラストラクチャです。
MySQL についての私の理解の 1 つは、インフラストラクチャです。

- coldplay.xixi転載
- 2020-10-20 17:03:332021ブラウズ
TodayMySQL チュートリアル コラムでは、私が理解している基本的なアーキテクチャを紹介します。

本格的な CRUD エンジニアとして、データベースとの対話は、日々の履歴データの追加、削除、変更、処理などの日常業務で大きな役割を果たしています。反復、SQL パフォーマンスの最適化など。プロジェクト データの量が増加するにつれて、プロジェクトの進捗状況を把握するために埋めてきた深い穴が徐々にその力を発揮し始めており、基本的な CRUD にとどまるのではなく、MySQL を包括的かつ深く学習する必要があります。 。
MySQL シリーズの第 1 回目では、MySQL のインフラストラクチャと、サーバー層のビン ログや InnoDB 特有の REDO ログなど各コンポーネントの機能を中心に紹介します。
1. MySQL アーキテクチャの概要
DB-Engines が発表した最も人気のあるデータベース管理システムのランキングによると、MySQL はしっかりと 2 位にランクされています。
最も人気のあるリレーショナル データベース管理システムの 1 つとして、MySQL は C/S アーキテクチャ、つまりクライアント & サーバー アーキテクチャを使用します。たとえば、開発者が Navicat を使用して MySQL に接続する場合、前者がクライアント、後者がサーバーになります。
同時に、MySQL は単一プロセスおよびマルチスレッドのデータベースでもあります。これは理解するのが簡単で、実行中の MySQL インスタンスは「単一プロセス」であり、このプロセスにはメイン スレッド Master Thread、IO Thread、これらのスレッドは、さまざまなタスクを処理するために使用されます。
2. MySQL コンポーネント
前述したように、MySQL は C/S アーキテクチャを使用しており、ユーザーはクライアントを通じて MySQL サーバーに接続し、SQL ステートメントをサーバーに送信します。サーバーは実行結果をクライアントに返します。
このセクションでは、主に MySQL サーバーの論理構成に焦点を当てます。最初に図を見てみましょう。
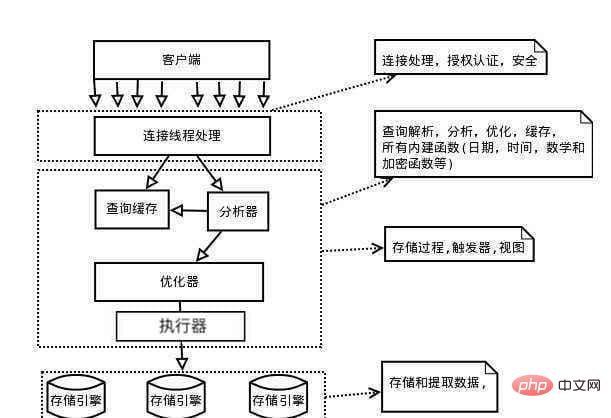
上の図からわかるように、クライアントとの対話において、MySQL サーバーはコネクタ、クエリ キャッシュ、アナライザー、オプティマイザー、エグゼキューター、およびこれらの部分を通過します。ストレージエンジンの。
以下では、簡単なクエリ ステートメントを使用して、MySQL サーバーのさまざまなコンポーネントとその機能を説明します。
2.1 コネクタ
クライアントはクエリ ステートメントを送信する前に、サーバーとの接続を確立する必要があります。コネクタの機能は、 クライアントとの接続の確立と管理を担当し、同時にユーザーの権限を照会することです。
次の点に注意してください:- コネクタはユーザーのアクセス許可のみを取得し、検証は実行しません。検証はクエリ キャッシュまたはエグゼキューターで実行されます。
- 接続が確立され、ユーザーの権限が取得されると、ユーザーの権限は新しい接続が確立されたときにのみ更新されます。
- クライアントが長期間リクエストを送信していない場合、コネクタは自動的に切断されます。ここでの「長い時間」は wait_timeout パラメータによって決まります。デフォルト値は 8 時間です。
MySQL がクライアントによって送信されたクエリ ステートメントを実行したかどうかをクエリすることです. If this SQL が以前に実行されており、ユーザーがテーブル上でステートメントを実行する権限を持っている場合、前回の実行結果が直接返されます。
したがって、ある時点で、SQL ステートメントを複数回実行しても平均実行時間を取得できなくなります。クエリ キャッシュのせいで、その後の実行時間は最初の実行時間よりも短くなることがよくあります。 キャッシュを使用したくない場合は、クエリのたびに update ステートメントを使用してテーブルを更新できますが、これは非常に面倒で愚かな方法です。 MySQL には、対応する構成項目query_cache_type も用意されており、my.cnf ファイルで query_cache_type を 0 に設定すると、クエリ キャッシュをオフにすることができます。
- クエリ キャッシュ部分は
- key-value
の形式で保存されます。ここで、キーはクエリ ステートメントであり、値はクエリ結果。データ テーブルが更新されると、このテーブルのすべてのクエリ キャッシュが無効になるため、一般にクエリ キャッシュのヒット率は非常に低くなります。 - バージョン
- MySQL 8.0
では、クエリ キャッシュ機能が削除されました。
アナライザーは、送信されたステートメントに対して字句解析 (ステートメントの解析) と構文解析 (ステートメントが MySQL の文法規則に準拠しているかどうかの判断) を実行するため、アナライザーの役割は SQL ステートメントを解析してチェックすることです。その合法性。
次の点に注意してください:
- MySQL が SQL ステートメントの有効性をチェックするとき、MySQL 構文規則に準拠しないエラーが最初に表示されるだけです。 、SQL ステートメントは変更されません。すべての文法エラーが表示されます。
例:
select * form user_info limit 1;复制代码
上記の SQL ステートメントには 2 つのエラーがあります。1 つ目は from のスペルミスで、2 つ目は user_info テーブルが存在しないことです。 SQL を 3 回実行した結果の情報を以下に示します。
第一次的执行信息: 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'form user_info limit 1' at line 1, Time: 0.000000s 修改为from后第二次的执行信息:1146 - Table 'windfall.user_info' doesn't exist, Time: 0.000000s 修改为 user 表后第三次的执行信息: OK, Time: 0.000000s复制代码
2.4 オプティマイザー
SQL ステートメントの正当性を検証した後、MySQL はユーザーによって送信されたステートメントが何であるかをすでに認識していますが、実際に実行される前に、まだ次の処理を行う必要があります。まさに「形而上学」オプティマイザーです。

オプティマイザの機能は、SQL ステートメントの最適な実行プランを 生成することです。
オプティマイザが「形而上学的」であると言われる理由は、SQL ステートメントの最適化の過程で、ユーザーが予期しない実行プラン (インデックスの選択、複数テーブルの関連付けの接続シーケンス、暗黙的な関数変換など)。もちろん、オプティマイザはデータ量やインデックス統計などの要因に関連して「間違ったインデックスを選択する」場合があります。 次の点に注意してください:- 実稼働環境で SQL を最適化する必要がある場合は、実稼働環境と同じデータ量でテーブルをローカルに復元してみてください。そして、実行計画に従って最適化します。
- クエリ ステートメントを作成するときは、インデックスの左端の一致原則を必ず考慮してください (左端の一致原則については、インデックスの章で説明します)。
オプティマイザーは MySQL を生成します。最適な実行計画の次は、最終的にエグゼキューターに来ると思います。エグゼキューターの役割は、もちろん
SQL ステートメントを実行することです。
ただし、実行前に、まず権限検証を行って、ユーザーがテーブルに対するクエリ権限を持っているかどうかを確認する必要があります。次に、テーブルで定義されたエンジン タイプに従って、対応するエンジンが提供するインターフェイスを使用してテーブルに対して条件付きクエリを実行し、最後に条件を満たすテーブルのすべてのデータ行を結果セットとしてクライアントに返します。 SQL 全体の実行が終了したことを意味します。 次の点に注意してください:- 実行プログラムが SQL ステートメントを実行する前に、ユーザーがテーブルに対する操作権限を持っているかどうかを確認するための検証が実行されます。
ストレージ エンジンについては、私は比較的触れることが少ないので、「MySQL Technology Insider: InnoDB Storage Engine」を読んでから整理するとして、ここでは簡単に触れる程度にします。3. ログ モジュール上記の実行プロセスは主にクエリ文について説明していますが、更新文の場合は MySQL ログ モジュールも関係します。 クライアントからエグゼキューターへの論理クエリ ステートメントと更新ステートメントは同じですが、エグゼキューター層に到達するときに更新ステートメントが MySQL ログ モジュールと対話する点が異なります。これがクエリ ステートメントとエグゼキューターの違いです。ステートメントを更新します。
3.1 物理日志 redo log
3.1.1 redo log 中记录的内容
对于 InnoDB 存储引擎来说,它有一个特有的日志模块——物理日志(重做日志)redo log,它是 InnoDB 存储引擎的日志,它所记录的是数据页的物理修改。
举个例子,现在有一张 user 表,有一条主键 id=1,age=18 的数据,然后用户提交了下面这条 SQL,执行器准备执行。
update user set age=age+1 where id=1;复制代码
对于这条 SQL,在 redo log 中记录的内容大致是:将 user 表中主键 id=1 行的 age 字段值修改为19。
3.1.2 WAL
MySQL 的更新持久化逻辑运用到了 WAL(Write-Ahead Logging,写前日志记录) 的思想:先写日志,再写磁盘。
需要注意的是这里的写日志也是写到磁盘中,但由于日志是顺序写入的,所以速度很快。而如果没有 redo log,直接更新磁盘中的数据,那么首先需要找到那条记录,然后再把新的值更新进入,由于查询和读写I/O,就相对会慢一些。
最后,当 InnoDB 引擎空闲的时候,它会去执行 redo log 中的逻辑,将数据持久化到磁盘中。
3.1.3 redo log 日志文件
redo log 日志文件大小是固定的,我把它理解为一个MySQL についての私の理解の 1 つは、インフラストラクチャです。,链表的每个节点都可以存放日志,在这个链表中有两个指针:write(黑) 和 read(白)。
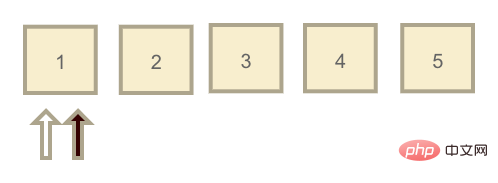
最开始这两个指针都指向同一个节点,且节点日志元素都为空,表示此时 redo log 为空。当用户开始提交更新语句,write 节点开始往前移动,假设移动到3的位置。而此时的情况就是 redo log 中有1-3这三个日志元素需要被持久化到磁盘中,当 InnoDB 空闲时,read 指针往前移动,就代表着将 redo log 持久化到磁盘。
但这里有一种特殊情况,就是 InnoDB 一直没有空闲,write 指针一直在写入日志,直到它写到5的位置,再往前写又回到了最开始1的位置(也就是上图的位置,但不同的是链表节点中都存在日志数据)。
此时发现1的位置已经有日志数据了,同时 read 指针也在。那么这时候 write 指针就会暂停写入,InnoDB 引擎开始催动 read 指针移动,把 redo log 清空掉一部分之后再让 write 指针写入日志文件。
3.1.4 redo log 的作用
我们已经知道,redo log 中记录的是数据页的物理修改,所以 redo log 能够保证在数据库发生异常重启时,记录尚未写入磁盘,但是在重启后可以通过 redo log 来“redo”,从而不会发生记录丢失的情况,保证了事务的持久性。
这一能力也被称作 crash-safe。
3.2 归档日志 bin log
前面说到 redo log 是 InnoDB 特有的日志,而 bin log 则是属于 MySQL Server 层的日志,在默认的 Statement Level 下它记录的是更新语句的原始逻辑,即 SQL 本身。
另外需要注意的是:
- bin log 的日志文件大小并不固定,它是“追加写入”的模式,写完一个文件后会切换到下一个文件写入。
- bin log 没有 crash-safe 的能力。
- bin log 是在事务最终提交前写入的,而 redo log 是在事务执行中不断写入的。
3.2.1 bin log 的作用
与 redo log 不同的是,bin log 常用于恢复数据,比如说主从复制,从节点根据父节点的 bin log 来进行数据同步,实现主从同步。
3.3 两阶段提交
为了让 redo log 和 bin log 的状态保持一致,MySQL 使用两阶段提交的方式来写入 redo log 日志。
在执行器调用 InnoDB 引擎的接口将写入更新数据时,InnoDB 引擎会将本次更新记录到 redo log 中,同时将 redo log 的状态标记为 prepare,表示可以提交事务。
随后执行器生成本次操作的 bin log 数据,并写入 bin log 的日志文件中。
最后执行器调用 InnoDB 的提交事务接口,存储引擎把刚写入的 redo log 记录状态修改为 commit,本次更新结束。
在这个过程中有三个步骤 add redo log and mark as prepare -> add bin log -> commit,即:
- REDO ログ ログを書き込み、prepare としてマークします
- bin ログを書き込みます
- トランザクションをコミットします
2 番目のステップの場合、また、システムは bin ログを書き込む前にクラッシュするか再起動します。起動後は、bin ログにレコードがないため、REDO ログ内のレコードはこの update ステートメントの実行前にロールバックされます。
3 番目のステップの前、つまり送信前にシステムがクラッシュまたは再起動した場合、コミットはなくても REDO ログのレコードが準備ステータスにあり、bin ログに完全なレコードが存在する場合でも、の場合、再起動後に自動的にコミットされ、ロールバックされません。
4. まとめ
この記事では主にMySQLのインフラと各コンポーネントの機能を紹介し、最後にMySQL Server層のbinログとInnoDB独自のREDOログについて紹介します。
5.温故知新を学ぶ
次の質問は、この記事で説明されている内容を疑問視し、知識を定着させるためのものです。教師になれるよ。」
- クエリ ステートメント内のフィールドが存在しない場合、フィールドがあいまいな場合、またはキーワードのスペルが間違っている場合、どの部分がエラーを報告しますか?
- ユーザーがテーブルに対するクエリ権限を持っていない場合、どの部分がエラーを報告しますか?
- MySQL のクエリ キャッシュが無効なのはなぜですか?
- 選択クエリ ステートメントはどのように実行されますか?
- MySQL で一般的に使用されるストレージ エンジンは何ですか?
- MySQL のロギング モジュールとは何ですか?彼らはどんな役割を果たしているのでしょうか?
- REDO ログがいっぱいになった場合はどうすればよいですか?
- REDO ログの 2 フェーズの送信を理解するにはどうすればよいですか?
REDO ログと bin ログの違いは何ですか?
#その他の関連する無料学習の推奨事項: mysql チュートリアル(ビデオ)
以上がMySQL についての私の理解の 1 つは、インフラストラクチャです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。