
Java 高同時実行システム設計 - キャッシュ

- coldplay.xixi転載
- 2020-10-10 17:24:122279ブラウズ
Java の基礎 今日のコラムでは、Java の高同時実行性システム設計のキャッシュの章を紹介します。

一般的なハードウェア コンポーネントのレイテンシは次のとおりです。 
これらのデータから、メモリ アドレッシングを実行していることがわかります。には約 100 ナノ秒かかり、ディスク ルックアップには 10 ミリ秒かかります。メモリをキャッシュ記憶媒体として使用すると、ディスクを主記憶媒体として使用するデータベースと比較して、パフォーマンスが何桁も向上することがわかります。したがって、メモリはデータをキャッシュするための最も一般的な媒体です。
1. キャッシュのケース
1. TLB
Linux のメモリ管理は、MMU (Memory Management Unit) と呼ばれるハードウェアを通じて仮想アドレスから物理アドレスへ実現されます。 , しかし、変換のたびにそのような複雑な計算が必要になると、間違いなくパフォーマンスの低下を引き起こすため、TLB (Translation Lookaside Buffer) と呼ばれるコンポーネントを使用して、最近変換された仮想アドレスと物理アドレスをキャッシュします。 TLB はキャッシュ コンポーネントです。
2. Douyin
プラットフォーム上の短いビデオは、実際には内蔵のネットワーク プレーヤーを使用して完成します。ネットワークプレーヤーは、データストリームを受信し、データをダウンロードし、音声ストリームと映像ストリームの分離、デコードなどの処理を行った後、周辺機器に出力して再生します。一部のキャッシュ コンポーネントは通常、ビデオが開かれていないときにビデオ データの一部をキャッシュするようにプレーヤー内で設計されています。たとえば、Douyin を開くと、サーバーは一度に 3 つのビデオ情報を返すことがあります。最初のビデオを再生すると、 player 2本目と3本目の動画のデータの一部をキャッシュしておき、2本目の動画を視聴するときに「数秒で始まる」という感覚をユーザーに提供できるようにしています。
3. HTTP プロトコル キャッシュ
画像などの静的リソースを初めてリクエストすると、サーバーは画像情報を返すだけでなく、「Etag」も持ちます。応答ヘッダーフィールド。ブラウザは画像情報とこのフィールドの値をキャッシュします。次回画像がリクエストされると、ブラウザによって開始されたリクエスト ヘッダーに「If-None-Match」フィールドが存在し、キャッシュされた「Etag」値がそこに書き込まれてサーバーに送信されます。サーバーは画像情報が変更されたかどうかをチェックし、変更されていない場合は 304 ステータス コードをブラウザに返し、ブラウザはキャッシュされた画像情報を引き続き使用します。このキャッシュネゴシエーション方式により、ネットワーク上に送信されるデータサイズが削減され、ページの表示パフォーマンスが向上します。 
2. キャッシュの分類
1. 静的キャッシュ
静的キャッシュは Web 1.0 時代に非常に有名で、通常は Velocity テンプレートまたは静的 HTML ファイルを生成します。静的キャッシュを実装するには、Nginx に静的キャッシュをデプロイすると、バックエンド アプリケーション サーバーの負荷を軽減できます
2. 分散キャッシュ
分散キャッシュの名前は非常によく知られており、通常はよく知られています。 Memcached と Redis は分散キャッシュの典型的な例です。これらは強力なパフォーマンスを備えており、いくつかの分散ソリューションを通じてクラスターを形成することで、単一マシンの制限を突破できます。したがって、アーキテクチャ全体において、分散キャッシュは非常に重要な役割を果たします
3. ローカル キャッシュ
Guava Cache や Ehcache などは、アプリケーションと同じプロセスにデプロイされます。クロスネットワーク スケジューリングは必要なく、非常に高速であるため、ホット クエリを短期間にブロックするために使用できます。
3. キャッシュ読み取りおよび書き込み戦略
1. キャッシュ アサイド戦略
データ更新時にキャッシュを更新せず、キャッシュ内のデータを削除してデータを読み取ります。キャッシュ内にデータがないことが判明した後、データがデータベースから読み取られてキャッシュに更新される場合。 
この戦略は、キャッシュに使用する最も一般的な戦略です。キャッシュ アサイド戦略 (バイパス キャッシュ戦略とも呼ばれます)。この戦略データはデータベース内のデータに基づいており、キャッシュ内のデータはオンデマンドでロードされました。
キャッシュ アサイド戦略は、日常の開発で最も一般的に使用されるキャッシュ戦略ですが、使用する際には状況に応じて変更することも学習する必要があり、静的なものではありません。 Cache Aside の最大の問題は、書き込みが頻繁に行われる場合、キャッシュ内のデータが頻繁にクリアされるため、キャッシュ ヒット率に影響が出るということです。ビジネスにキャッシュ ヒット率に関する厳しい要件がある場合は、2 つのソリューションを検討できます。
1 つの方法は、データの更新時にキャッシュを更新しますが、キャッシュを更新する前に分散ロックを追加することです。この方法では、同時に 1 つのスレッドのみがキャッシュを更新できるため、同時実行の問題は発生しません。もちろん、これを行うと書き込みパフォーマンスにある程度の影響が生じます (推奨);
別のアプローチは、データ更新時にキャッシュを更新することですが、キャッシュに有効期限を短くするだけです。不整合が発生した場合、キャッシュされたデータはすぐに期限切れになり、ビジネスへの影響は許容されます。
2. 読み取り/書き込みスルー
この戦略の核となる原則は、ユーザーはキャッシュのみを扱い、キャッシュはデータベースと通信してデータの書き込みまたは読み取りを行うことです。 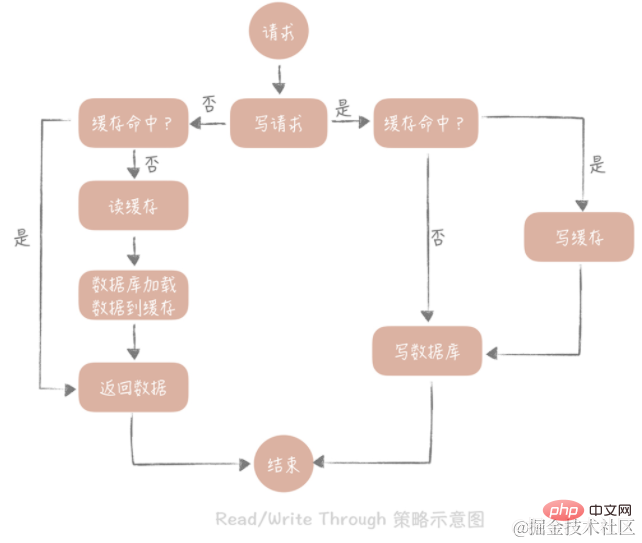
ライトスルー
戦略は次のとおりです。まず、書き込まれるデータがキャッシュにすでに存在するかどうかをクエリし、すでに存在する場合は更新します。キャッシュ キャッシュ内のデータはキャッシュ コンポーネントによって同期され、データベースに更新されます。キャッシュ内のデータが存在しない場合、この状況を「書き込みミス」と呼びます。一般に、2 つの「書き込みミス」方法を選択できます。1 つは「書き込み割り当て (書き込みによる割り当て)」で、キャッシュ内の対応する場所を書き込み、キャッシュ コンポーネントがそれをデータベースに同期的に更新します。 「No -write assign (書き込み時に割り当てを行わない)」の場合、キャッシュに書き込むのではなく、データベースに直接更新する方法です。 ライトスルー戦略でのデータベースへの書き込みは同期的であることがわかります。これは、データベースへの同期書き込みの待ち時間がキャッシュへの書き込みよりもはるかに長いため、パフォーマンスに大きな影響を与えます。ライトバック戦略を通じてデータベースを非同期的に更新します。
最後まで読んでください
戦略はより単純で、その手順は次のとおりです: まず、キャッシュ内のデータが存在するかどうかをクエリし、存在する場合はそれを直接返します。存在しない場合、キャッシュ コンポーネントはデータベースからデータを同期的にロードします。
3. ライトバック
この戦略の中心的な考え方は、データを書き込むときにのみキャッシュに書き込み、キャッシュ ブロックを「ダーティ」としてマークすることです。ダーティ ブロック内のデータは、再度使用されるときにのみバックエンド ストレージに書き込まれます。
「書き込みミス」の場合は、「書き込み割り当て」メソッドを使用します。これは、バックエンド ストレージに書き込みながらキャッシュに書き込むことを意味するため、バックエンドを更新せずに、後続の書き込みリクエストでキャッシュを更新するだけで済みます。ストレージ。上記のライトスルー戦略との違いに注意してください。 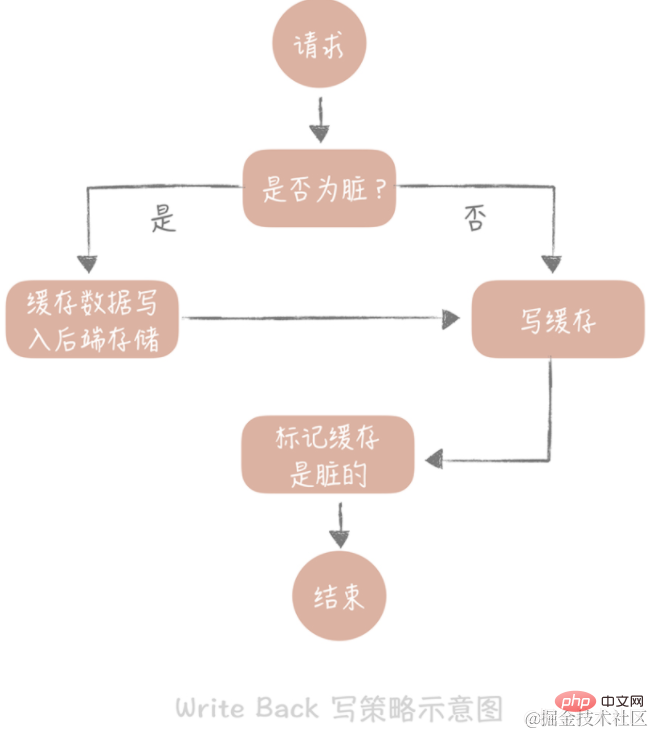
キャッシュの読み取り時にキャッシュ ヒットが見つかった場合は、キャッシュ データを直接返します。キャッシュがミスした場合は、使用可能なキャッシュ ブロックを探します。キャッシュ ブロックが「ダーティ」の場合、キャッシュ ブロック内の以前のデータがバックエンド ストレージに書き込まれ、データがバックエンド ストレージからバックエンド ストレージにロードされます。ブロックがダーティでない場合、キャッシュ コンポーネントはバックエンド ストレージのデータをキャッシュにロードし、最後にキャッシュをダーティでないように設定し、データを返します。 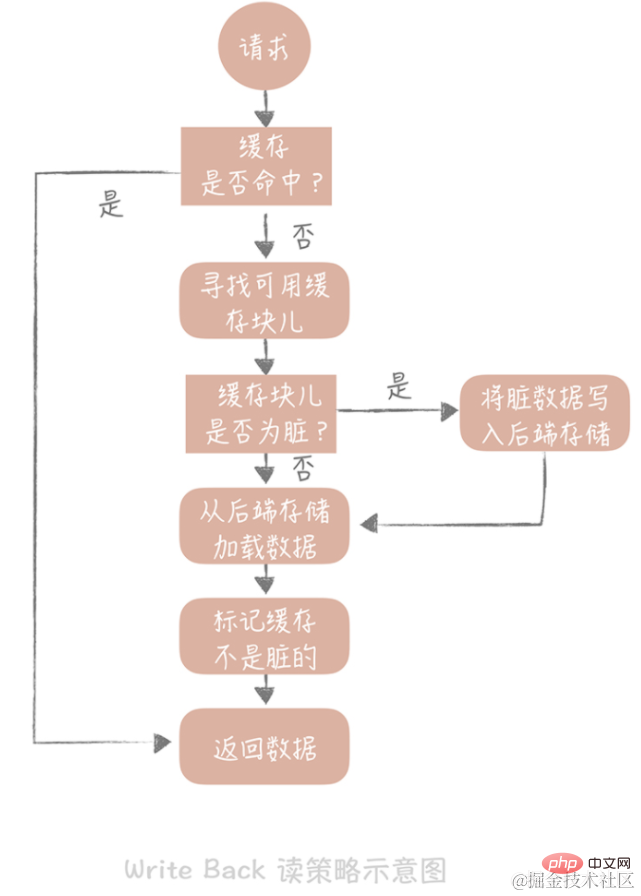
ライトバック戦略は、主にデータをディスクに書き込むために使用されます。例: オペレーティング システム レベルのページ キャッシュ、ログの非同期フラッシュ、メッセージ キュー内のメッセージのディスクへの非同期書き込みなど。この戦略のパフォーマンス上の利点は疑いの余地がないため、ディスクへの直接書き込みによって引き起こされるランダム書き込みの問題が回避されますが、結局のところ、メモリへの書き込みとディスクへの書き込みのランダム I/O のレイテンシは数桁異なります。
4. キャッシュの高可用性
キャッシュ ヒット率は、キャッシュによって監視する必要があるデータ インジケーターです。キャッシュの高可用性により、キャッシュ侵入の確率が一定まで低下します。システムの安定性を向上させます。キャッシュの高可用性ソリューションには、主に、クライアント側ソリューション、中間プロキシ層ソリューション、サーバー側ソリューションの 3 つのカテゴリが含まれます。解決策としては、キャッシュに注意を払う必要があります。書き込みと読み取りの両方の側面: データを書き込む場合、キャッシュに書き込まれたデータを複数のノードに分散する必要があります。つまり、データ シャーディングが実行されます。 データを読み取るとき、フォールト トレランスのために複数のキャッシュ セットを使用し、キャッシュ システムの可用性を向上させることができます。データの読み取りに関しては、マスタースレーブとマルチコピーの 2 つの戦略を使用でき、異なる問題を解決するために 2 つの戦略が提案されています。 具体的な実装の詳細には、データ シャーディング、マスター/スレーブ、および複数のコピーが含まれます。
データ シャーディング一貫したハッシュ アルゴリズム。このアルゴリズムでは、ハッシュ値空間全体を仮想リングに編成し、キャッシュ ノードの IP アドレスまたはホスト名をハッシュしてこのリング上に配置します。特定のキーにアクセスする必要があるノードを決定する必要がある場合、最初にキーに対して同じハッシュ値を実行し、リング上のその位置を決定し、次にリング上を時計回りに「歩きます」。最初のキャッシュ ノードはアクセスされるノードです。 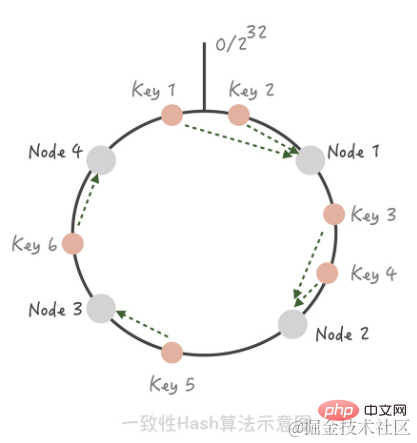
ノード 1 とノード 2 の間にノード 5 を追加すると、最初はノード 2 にヒットしていたキー 3 がノード 5 にヒットする一方、他のキーは変更されていないことがわかります。クラスターからノード 3 を削除すると、キー 5 にのみ影響します。つまり、ノードを追加および削除するときに、少数のキーだけが他のノードに「ドリフト」し、ほとんどのキーがヒットするノードは変更されないため、ヒット率が大幅に低下することはありません。 [ヒント] コンシステント ハッシュで発生するキャッシュ雪崩現象を解決するには、仮想ノードを使用します。 Consistent Hash shardingとHash shardingの違いはキャッシュヒット率の問題で、ハッシュシャーディングではマシンの追加や削減を行うとキャッシュが無効になり、キャッシュヒット率が低下します。
マスター/スレーブ
Redis 自体はマスター/スレーブ デプロイメント方法をサポートしていますが、Memcached はそれをサポートしていません。クライアント。マスターのグループごとにスレーブのセットを構成します。データを更新するとき、マスターとスレーブは同時に更新されます。読み取り時には、データは最初にスレーブから読み取られます。データを読み取れない場合は、マスター経由で読み取られ、スレーブ データをホットな状態に保つためにデータがスレーブにシードされて戻されます。マスター/スレーブ メカニズムの最大の利点は、特定のスレーブがダウンした場合にマスターがバックアップとなるため、データベースに大量のリクエストが侵入することがなくなり、キャッシュ システムの高可用性が向上することです。
複数のコピー
マスター/スレーブ方式は、ほとんどのシナリオですでに問題を解決できますが、極端なトラフィック シナリオでは、通常、スレーブのグループが負担を完全に担うことができません。すべてのトラフィックにおいて、スレーブ ネットワーク カードの帯域幅がボトルネックになる可能性があります。この問題を解決するには、マスター/スレーブの前にコピー層を追加することを検討します。全体的なアーキテクチャは次のとおりです: 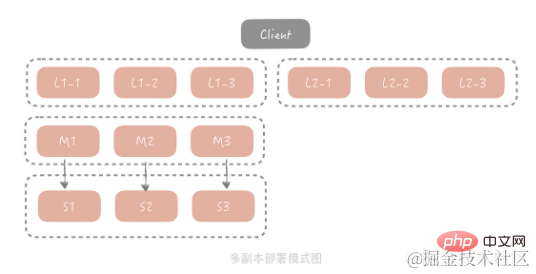
このソリューションでは、クライアントがクエリ リクエストを開始すると、リクエストは最初に行われます。複数のコピー グループから 1 つのコピー グループを選択してクエリを開始します。クエリが失敗した場合、クエリはマスター/スレーブに続行され、クエリ結果はすべてのコピー グループにシードされて戻され、コピー グループにダーティ データが存在するのを防ぎます。コピーグループ。コストを考慮すると、各コピー グループの容量はマスターおよびスレーブの容量よりも小さいため、よりホットなデータのみが保存されます。このアーキテクチャでは、マスターとスレーブのリクエスト量が大幅に削減され、保存されるデータの熱量を確保するために、実際にはマスターとスレーブをコピー グループとして使用します。
2. 中間プロキシ レイヤー
業界には、Facebook の Mcrouter、Twitter の Twemproxy、Wandoujia の Codis など、中間プロキシ レイヤー ソリューションも多数あります。それらの原則は基本的に次の図で要約できます: 
3. サーバー側のソリューション
Redis は、マスター/スレーブ Redis デプロイメントの問題を解決するために、バージョン 2.4 で Redis Sentinel モードを提案しました。高可用性の問題。マスター ノードがハングアップした後、スレーブ ノードをマスター ノードに自動的に昇格させ、クラスター全体の可用性を確保します。全体的なアーキテクチャを次の図に示します。 redis Sentinel もクラスター デプロイメントです。これにより、Sentinel ノードの障害によって引き起こされる自動障害回復の問題を回避できます。各 Sentinel ノードはステートレスです。マスターのアドレスは Sentinel で設定されます。Sentinel はマスターのステータスを常に監視します。設定された時間間隔内にマスターが応答しないことが判明した場合、マスターが死亡したと見なされます。Sentinel は次のいずれかを選択します。スレーブ ノードをマスター ノードに昇格させ、他のすべてのスレーブ ノードを新しいマスターのスレーブ ノードとして扱います。 Sentinel クラスター内の調停中に、構成された値に基づいて決定されます。複数の Sentinel ノードがマスターがダウンしていると判断した場合、マスター/スレーブ切り替え操作を実行できます。つまり、クラスターは、次の点について合意に達する必要があります。キャッシュノードのステータス。 
5. キャッシュの侵入
1. パレート
インターネット システムのデータ アクセス モデルは、一般に「80/20 原則」に従います。 「80/20原則」はパレートの法則とも呼ばれ、イタリアの経済学者パレートが提唱した経済理論です。簡単に言うと、一連の物事において、最も重要な部分は通常 20% しか占めず、残りの 80% はそれほど重要ではないことを意味します。これをデータ アクセスの分野に当てはめると、ホット データの 20% には頻繁にアクセスされますが、残りの 80% のデータには頻繁にアクセスされません。キャッシュ容量は限られており、ほとんどのアクセスはホットスポット データの 20% のみを要求するため、理論的には、壊れやすいバックエンド システムを効果的に保護するには、限られたキャッシュ スペースにホットスポット データの 20% を保存するだけで済みます。ホットでないデータの残りの 80% のキャッシュを諦めることができます。したがって、この少量のキャッシュの侵入は避けられませんが、システムに害を与えることはありません。
2. null 値を返す
データベースから null 値をクエリする場合、または例外が発生した場合は、キャッシュに null 値を返すことができます。ただし、NULL 値は正確なビジネス データではなく、キャッシュ領域を占有するため、NULL 値がすぐに期限切れになり、短期間で削除されるように、比較的短い有効期限を NULL 値に追加します。 null 値を返すと大量の貫通リクエストをブロックできますが、大量の null 値がキャッシュされている場合は、キャッシュの記憶領域も無駄に消費されます。キャッシュ領域がいっぱいの場合、キャッシュされている一部のユーザー情報が失われます。逆にキャッシュヒット率が低下する原因となります。したがって、使用する場合は、キャッシュ容量がこのソリューションをサポートできるかどうかを評価することをお勧めします。これをサポートするために多数のキャッシュ ノードが必要な場合は、null 値を植え付けるだけでは解決できないため、ブルーム フィルターの使用を検討できます。
3. ブルーム フィルター
1970 年に、ブルームは、要素がセット内にあるかどうかを判断するためのブルーム フィルター アルゴリズムを提案しました。このアルゴリズムは、バイナリ配列とハッシュ アルゴリズムで構成されます。その基本的な考え方は次のとおりです。提供されたハッシュ アルゴリズムに従って、セット内の各値に対応するハッシュ値を計算し、そのハッシュ値を配列の長さで割って、配列に含める必要があるインデックス値を取得します。配列のこの位置にインデックス値を追加します。値は 0 から 1 に変更されました。このセットに要素が存在するかどうかを判断する場合は、同じアルゴリズムに従って要素のインデックス値を計算するだけでよく、この位置の値が 1 であれば要素がセット内にあると見なされ、それ以外の場合は要素がセット内にあるとみなされます。セットに含まれていないものとみなされます。 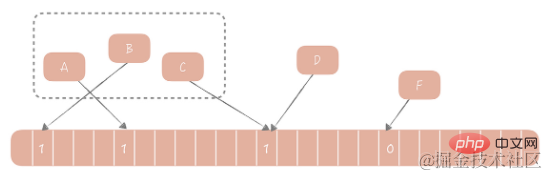
ブルーム フィルターを使用してキャッシュの侵入を解決するにはどうすればよいですか?
ユーザー情報を格納するテーブルを例に説明します。まず大きな配列、たとえば長さ 20 億の配列を初期化し、次にハッシュ アルゴリズムを選択します。次に、既存のすべてのユーザー ID のハッシュ値を計算し、それらをこの大きな配列にマッピングします。位置の値は次のとおりです。 1 に設定され、その他の値は 0 に設定されます。データベースへの書き込みに加えて、新規登録ユーザーは、同じアルゴリズムに従ってブルーム フィルター配列内の対応する位置の値を更新する必要もあります。次に、特定のユーザーの情報をクエリする必要がある場合、まずブルーム フィルターに ID が存在するかどうかをクエリし、存在しない場合はデータベースとキャッシュへのクエリを続行せずに直接 null 値を返すため、大幅なコスト削減が可能になります。例外 クエリによるキャッシュの侵入。 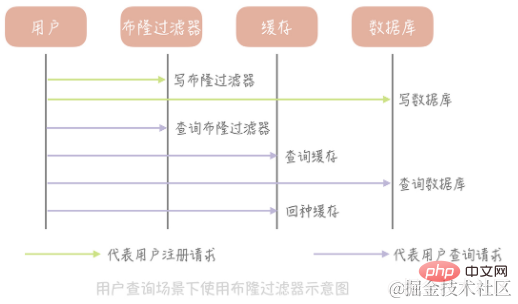
ブルームフィルターの利点:
(1) 高性能。書き込み操作であっても読み取り操作であっても、時間計算量は O(1) であり、スペースを節約するために定数値
(2) になります。たとえば、20 億の配列には 2000000000/8/1024/1024 = 238M のスペースが必要です。配列がストレージに使用される場合、各ユーザー ID が 4 バイトのスペースを占有すると仮定すると、20 億のユーザーを保存するには 2000000000 * 4 / 1024 が必要になります。 / 1024 = 7600M のスペース、ブルーム フィルターの 32 倍。
ブルームフィルターのデメリット:
(1) 要素を分類するなど、要素が集合に含まれるかどうかの判定に一定の確率で誤りが発生する集合に含まれていない要素は集合に含まれると判断されます。
理由: ハッシュ アルゴリズム自体の欠陥。
解決策: 複数のハッシュ アルゴリズムを使用して要素の複数のハッシュ値を計算します。すべてのハッシュ値に対応する配列内の値が 1 である場合にのみ、要素はセット。
(2) 要素の削除はサポートされていません。ブルームフィルターが要素の削除をサポートしていないという欠陥も、ハッシュ衝突に関連しています。たとえば、2 つの要素 A と B が両方ともコレクション内の要素であり、同じハッシュ値を持つ場合、それらは配列内の同じ位置にマップされます。このときAを削除すると、配列内の対応する位置の値も1から0に変わります。そしてBを判定して値が0であれば、Bもそうでない要素であると判定します。そうなると、間違った結論が得られてしまいます。
解決策: 配列に 0 と 1 の値を入れるだけではなく、カウントを保存します。たとえば、A と B が同時に配列のインデックスにヒットした場合、この位置の値は 2 になります。A が削除されると、値は 2 から 1 に変更されます。このソリューションの配列はビットではなく値を保存するため、スペース消費量が増加します。
4. ドッグパイル効果
たとえば、非常にホットなキャッシュ項目がある場合、それが失敗すると、大量のリクエストがデータベースに侵入し、瞬間的かつ巨大なエラーが発生します。データベースへの圧力がかかるため、このシーンを「ドッグパイル効果」と呼びます。ドッグ スタブ効果を解決するアイデアは、キャッシュ侵入後の同時実行性を最小限に抑えることです。解決策は比較的単純です:
(1) 特定のホット キャッシュ アイテムの有効期限が切れた後にバックグラウンド スレッドを開始するようにコード内で制御します。侵入 データベースに移動し、データをキャッシュにロードします。キャッシュがロードされる前は、このキャッシュにアクセスするすべてのリクエストは侵入せず、直接返されます。
(2) Memcached または Redis で分散ロックを設定すると、ロックを取得するリクエストのみがデータベースに侵入できるようになります
6. CDN
1、静的理由リソース アクセラレーション
私たちのシステムには多数の静的リソース リクエストがあります。モバイル APP の場合、これらの静的リソースは主に画像、ビデオ、ストリーミング メディア情報です。Web ウェブサイトの場合、それらには JavaScript ファイル、CSS ファイル、静的HTMLファイルなど。これらには大量の読み取りリクエストがあり、高いアクセス速度が必要で、高帯域幅を占有します。現時点では、アクセス速度が遅いことと、全帯域幅が動的リクエストに影響を与えるという問題が発生します。その後、これらの静的リソースをターゲットにする方法を検討する必要があります。 . 読書が加速します。
2. CDN
静的リソース アクセスのキー ポイントは近くのアクセス、つまり北京のユーザーは北京のデータにアクセスし、杭州のユーザーは杭州のデータにアクセスすることです。最適なパフォーマンスを達成できます。静的リソースへのほとんどのアクセスを処理するために、業務サーバーの上位層に特別なキャッシュ層を追加することを検討していますが、この特別なキャッシュのノードを全国に分散させ、ユーザーが最も近いノードを選択してアクセスできるようにする必要があります。また、キャッシュヒット率もある程度保証する必要があり、リソース格納元サイトへのアクセスリクエスト(原点復帰リクエスト)は最小限にする必要がある。このキャッシュ層は CDN です。
CDN (コンテンツ配信ネットワーク/コンテンツ配信ネットワーク、コンテンツ配信ネットワーク)。簡単に言えば、CDN は地理的に複数の場所にあるコンピューター室にあるサーバーに静的リソースを分散するため、近隣のデータ アクセスの問題を十分に解決し、静的リソースのアクセス速度を高速化できます。
3. CDN システムを構築する
CDN システムを構築する際には 2 つの点を考慮する必要があります:
(1) ユーザー リクエストを CDN ノードにマッピングする方法
これは非常に簡単だと思われるかもしれませんが、ユーザーに CDN ノードの IP アドレスを伝え、この IP アドレスにデプロイされた CDN サービスを要求するだけです。ただし、そうではなく、IP を対応するドメイン名に置き換える必要があります。では、どうやってこれを行うのでしょうか?これには、ドメイン名のマッピングの問題を解決するために DNS に依存する必要があります。 DNS (Domain Name System) は、実際にはドメイン名と IP アドレスの対応を保存する分散データベースです。一般に、ドメイン名解決結果には 2 種類あり、1 つはドメイン名に対応する IP アドレスを返す「A レコード」と呼ばれ、もう 1 つは別のドメイン名、つまり、現在のドメイン名の解決 別のドメイン名の解決にジャンプします。
例: たとえば、会社の第 1 レベルのドメイン名が example.com である場合、イメージ サービスのドメイン名を「img.example.com」として定義し、ドメイン名 CNAME は CDN によって提供されるドメイン名に構成されます。たとえば、ucloud は「80f21f91.cdn.ucloud.com.cn」というドメイン名を提供します。このようにして、電子商取引システムで使用される画像アドレスは「img.example.com/1.jpg」になります。
ユーザーがこのアドレスを要求すると、DNS サーバーはドメイン名を 80f21f91.cdn.ucloud.com.cn ドメイン名に解決し、次にドメイン名を CDN ノード IP に解決します。 CDNではリソースデータを取得できます。
ドメイン名レベルの解決の最適化
ドメイン名解決プロセスは階層的であり、各レベルには解決を担当する専用のドメイン ネーム サーバーがあるため、ドメイン名解決プロセスは可能です。パブリック ネットワーク上で複数の DNS クエリが必要ですが、パフォーマンスが比較的劣ります。解決策の 1 つは、APP の起動時に解析する必要があるドメイン名を事前に解析し、解析結果をローカル LRU キャッシュにキャッシュすることです。このように、このドメイン名を使用したい場合は、必要な IP アドレスをキャッシュから直接取得するだけで済みますが、キャッシュに存在しない場合は、DNS クエリ プロセス全体を実行することになります。同時に、DNS 解決結果の変化によってキャッシュ内のデータが無効になるのを避けるために、タイマーを開始してキャッシュ内のデータを定期的に更新できます。
(2) ユーザーの地理的位置情報に基づいて比較的近いノードを選択する方法。
GSLB (Global Server Load Balance) は、異なるリージョンに展開されたサーバー間の負荷分散を意味し、多くのローカル負荷分散コンポーネントは以下で管理できます。負荷分散サーバーとしての機能が 2 つあります。負荷分散とは、その名前が示すように、下で管理されているサーバーの負荷がより均等になるようにトラフィックを均等に分散することを指します。また、サーバーが通過するトラフィックがトラフィックの発信元に比較的近いことを確認する必要もあります。
GSLB はさまざまな戦略を使用して、返された CDN ノードとユーザーが可能な限り同じ地理的エリアに存在することを保証できます。たとえば、ユーザーの IP アドレスは地理的位置に応じて複数のエリアに分割できます。リージョンでは、ユーザーが位置するリージョンに応じて適切なノードが返されます。また、RTT を測定するためのデータ パケットを送信して、どのノードを返すかを決定することもできます。
概要: DNS テクノロジーは、CDN 実装で使用されるコア テクノロジーであり、ユーザー リクエストを CDN ノードにマッピングできます。DNS 解決プロセスの応答時間を短縮するには、DNS 解決結果をローカルにキャッシュする必要があります。GSLB は、次のことを提供します。ユーザーは、静的リソースへのアクセスを高速化するために、それに近いノードを返します。
拡張
(1) Baidu ドメイン名解決プロセス
最初に、ドメイン名解決リクエストは、最初に、ローカル マシンに www.baidu.com に対応する IP があるかどうかを確認し、存在しない場合は、ローカル DNS を要求して、ドメイン名解決結果のキャッシュがあるかどうかを確認し、キャッシュがある場合は、非ドメインから返されたことを示す結果を返します。 -権限のある DNS; そうでない場合は、DNS の反復クエリを開始します。最初にルート DNS をリクエストすると、トップレベル DNS (.com) のアドレスが返されます。次に、.com トップレベル DNS にリクエストして、baidu.com のドメイン ネーム サーバー アドレスを取得し、次に、baidu.com のドメイン ネーム サーバー アドレスをクエリします。 baidu.com のドメイン ネーム サーバーから www.baidu.com.IP アドレスを返し、この IP アドレスを返すときに、結果を権威 DNS からのものとしてマークし、ローカル DNS 解析結果キャッシュに書き込みます。同じドメイン名を解析する場合、反復的な DNS クエリを実行する必要はありません。
(2) CDN 遅延
一般に、CDN メーカーのインターフェイスを通じて静的リソースを特定の CDN ノードに書き込み、その後 CDN 内部の同期メカニズムを使用します。各 CDN ノードにリソースを分散して同期します。CDN 内部ネットワークが最適化されていても、この同期プロセスは遅れます。選択した CDN ノードからデータを取得できなくなったら、ソースからデータを取得する必要があります。ユーザー ネットワークからのネットワーク発信元サイトへの接続は複数のバックボーン ネットワークにまたがる可能性があり、これによりパフォーマンスが低下するだけでなく、発信元サイトの帯域幅が消費され、研究開発コストが増加します。したがって、CDN を使用する場合は、CDN のヒット率と発信元サイトの帯域幅に注意する必要があります。
関連する学習の推奨事項: Java の基本
以上がJava 高同時実行システム設計 - キャッシュの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。