
ホームページ >バックエンド開発 >Python チュートリアル >PythonでPDFを操作するいくつかの方法をまとめます
PythonでPDFを操作するいくつかの方法をまとめます

- coldplay.xixi転載
- 2020-10-08 17:50:244199ブラウズ
Python チュートリアル 今日のコラムでは、Python を使用して PDF を操作するいくつかの方法をまとめます。

01
まえがき
みなさん、こんにちは。Python で PDF を操作する事例が書きました。 PDF バッチ マージ を経験する前に、このケースの本来の目的は、便利なスクリプトを提供することだけであり、原理についてはあまり説明されていません。PDF 用の非常に実用的なモジュールが含まれています。処理、PyPDF2。この記事では、主に
- os モジュールの包括的なアプリケーション
- を中心に、このモジュールを注意深く分析します。 glob モジュールの包括的なアプリケーション
- PyPDF2 モジュールの操作
#02
基本操作
##PyPDF2 モジュールをインポートするコードは通常次のとおりです:from PyPDF2 import PdfFileReader, PdfFileWriter复制代码ここでは 2 つのメソッドがインポートされます:
- PdfFileReader はリーダーとして理解できます
- PdfFileWriter がわかるライター向け
MERGE
1 つの仕事は、5 つの請求書 PDF を 10 ページに結合することです。ここで読み手と書き手はどのように協力すべきでしょうか?
ロジックは次のとおりです:- リーダーはすべての PDF を 1 回読み取ります
- リーダーは読み取ったコンテンツをライターに渡します
- ライターは一律に新しい PDF に出力します
独立したステップではありません しかし、リーダーが PDF を読み取った後、ページごとに読み取られると、PDF のすべてのページが循環されます。作家に渡ります。最後に、すべての読み取り作業が完了するまで待ってから出力します。
コードを見るとアイデアがより明確になります:from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxxxxx'
pdf_writer = PdfFileWriter()
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open(path + r'\合并PDF\merge.pdf', 'wb') as out:
pdf_writer.write(out)复制代码すべてのコンテンツは同じライターに渡され、最終的に一緒に出力される必要があるため、ライターの初期化はループ本体の外側。ループ本体の内側にある場合は、PDF にアクセスするたびに新しいライターが生成され、各リーダーがライターに引き継がれるようになります。コンテンツは 繰り返し上書きされます ため、マージ要件は達成できません!ループ本体の先頭のコード:
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))复制代码目的は、ループするたびに新しい PDF ファイルは、後続の操作のためにリーダーに渡されます。実はこの書き方はあまりお勧めできませんが、各 PDF の命名はたまたま非常に規則的であるため、ループする番号を直接指定することもできます。より良い方法は、
glob モジュールを使用することです。コード内の import glob
for file in glob.glob(path + '/*.pdf'):
pdf_reader = PdfFileReader(path)复制代码
を使用すると、リーダー内のページ数を取得できます。 range はリーダーのすべてのページを横断できます。
pdf_writer.addPage(pdf_reader.getPage(page))は、現在のページをライターに渡すことができます。 最後に、
withを使用して新しい PDF を作成し、ライターの pdf_writer.write(out) メソッドを通じて出力します。 04
Splitマージ操作におけるリーダーとライターの協力を理解していれば、分割は簡単に理解できます。
INV1.pdfを 2 つの個別の PDF ドキュメントに分割する例を取り上げます。最初にロジックを見てみましょう:
読者が PDF ドキュメントを読み取ります- 読者が手にしますページごとにライターに渡されます。
- ライターは、取得したすべてのページをすぐに出力します。
- このコード ロジックを通じて、次のことも理解できます。 Writer は、ループの外側ではなく、PDF 読み取りループの各ページのループ本体内に存在する必要があります。
コードは非常に単純です:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxx'
pdf_reader = PdfFileReader(path + '\INV1.pdf')
for page in range(pdf_reader.getNumPages()):
# 遍历到每一页挨个生成写入器
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入器被添加一页后立即输出产生pdf
with open(path + '\INV1-{}.pdf'.format(page + 1), 'wb') as out:
pdf_writer.write(out)复制代码05
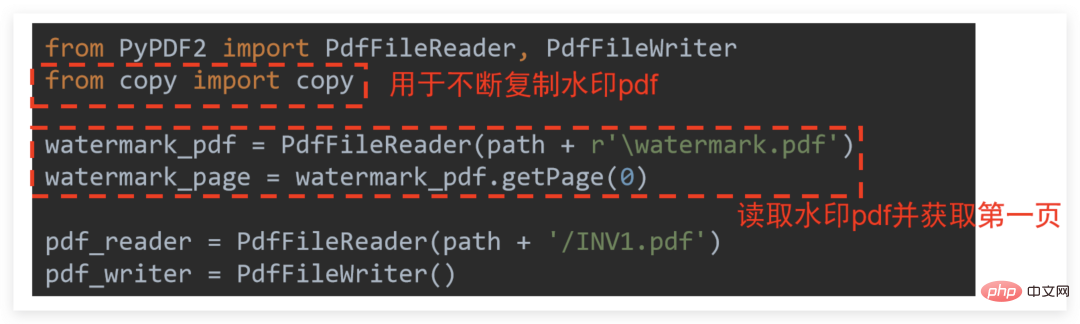
ウォーターマーク今回の作業は、
INV1.pdf
 最初の画像にウォーターマークとして次の画像を追加することです。
最初の画像にウォーターマークとして次の画像を追加することです。 copy モジュールを使用する必要があります。詳細な説明については、下の図を参照してください:
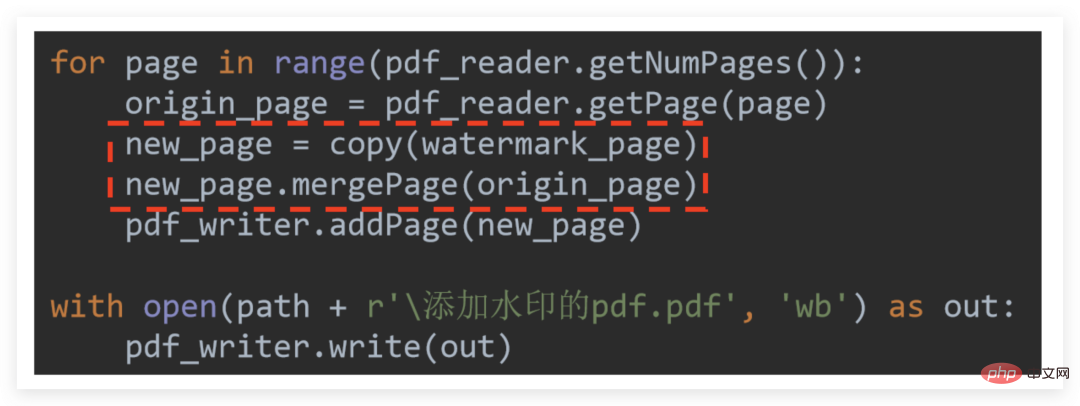
透かしを追加するということは、本質的には 透かしを入れた PDF ページを透かしを入れる必要がある各ページと結合することです
透かしを入れる必要がある PDF がそこにあるためです。多くのページがあるかもしれませんが、透かし入り PDF には 1 ページしかないため、透かし入り PDF を直接結合すると、抽象的には、最初のページを追加すると透かし入り PDF ページがなくなると理解できます。
したがって、 を直接マージすることはできません ただし、透かし入りの PDF ページは、後で使用できるように継続的に コピー して新しいページに出力する必要があります new_page, .mergePage このメソッドは各ページとのマージを完了し、最終的な統合出力のためにマージされたページをライターに渡します!
.mergePage# の使用について##:下のページに表示されます。mergePage (上のページに表示されます)、最終的な効果は以下のようになります:
06暗号化
暗号化は非常に簡単です。覚えておいてください:「暗号化はライターの暗号化のためです」
したがって、pdf_writer.encrypt (パスワード) を呼び出すだけで済みます。 # 該当する操作が完了した後 ## 単一の PDF の暗号化を例にとります:
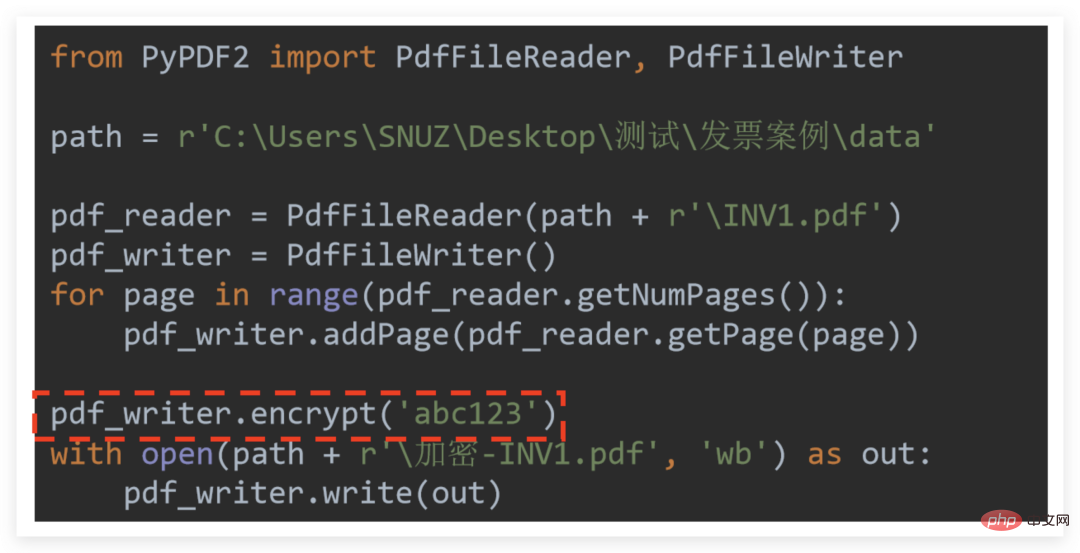 は最後に記述されます
は最後に記述されます Python を Excel および Word と組み合わせて使用して、より多くの自動化要件を実現することもできます。これらは読者に委ねられています。自分たちで開発する。 Python リソース共有 Junyang 1075110200 (インストール パッケージ、PDF、学習ビデオが含まれています)。これは Python 学習者が集まる場所です。ゼロベースでも上級者でも大歓迎です。最後に、Python オフィス オートメーションを誰もが理解できることを願っています1 つのコアは、バッチ操作で手を解放し、
複雑な作業を自動化することです。その他の関連する無料学習の推奨事項:
Python チュートリアル(ビデオ)
以上がPythonでPDFを操作するいくつかの方法をまとめますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。