
ホームページ >バックエンド開発 >Python チュートリアル >パンダの最も詳細なチュートリアル
パンダの最も詳細なチュートリアル

- coldplay.xixi転載
- 2020-09-18 16:51:566374ブラウズ

関連する学習の推奨事項: python チュートリアル
Python はオープンソースであり、優れていますが、オープンソースはそうすることはできません。いくつかの固有の問題: 多くのパッケージが同じことを実行します (または実行しようとします)。 Python を初めて使用する場合、特定のタスクにどのパッケージが最適であるかを知るのは難しいため、経験のある人に教えてもらう必要があります。データ サイエンスには絶対に必要なパッケージが 1 つあり、それは pandas です。
パンダについて最も興味深い点は、内部に多くのパッケージが隠されていることです。これは、他のパッケージの多くの機能を備えたコア パッケージです。これは、パンダを使用するだけで作業を完了できるため、非常に優れています。
pandas は Python の Excel に相当します。pandas はテーブル (つまり、データフレーム) を使用し、データに対してさまざまな変換を実行できますが、他にも多くの機能があります。
すでに Python の使用に慣れている場合は、3 番目の段落に直接ジャンプできます。
始めましょう:
import pandas as pd复制代码
なぜ「p」ではなく「pd」なのかは聞かないでください。それだけです。それを使ってください:)
pandas の最も基本的な関数
Read data
data = pd.read_csv( my_file.csv ) data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])复制代码
sep は区切り文字を表します。フランス語のデータを使用する場合、Excel の CSV 区切り文字は「;」であるため、明示的に指定する必要があります。フランス語の文字を読み取るために、エンコードは latin-1 に設定されます。 nrows=1000 は、データの最初の 1000 行を読み取ることを意味します。 Skiprows=[2,5] は、ファイルを読み取るときに 2 行目と 5 行目を削除することを意味します。
- #最も一般的に使用される関数: read_csv、read_excel
- その他の優れた関数: read_clipboard、read_sql
Write data
data.to_csv( my_new_file.csv , index=None)复制代码index=None は、データがそのまま書き込まれることを意味します。 Index=None と書かない場合、最後の行まで、内容 1、2、3、... を持つ最初の列が余分に存在することになります。 私は通常、.to_excel、.to_json、.to_pickle などの他の関数を使用しません。これは、.to_csv が適切に機能し、csv がテーブルを保存する最も一般的な方法であるためです。
データを確認します

Gives (#rows, #columns)复制代码
data.describe()复制代码
基本統計データの計算
データの表示data.head(3)复制代码
データの最初の 3 行を印刷します。同様に、.tail() はデータの最後の行に対応します。
data.loc[8]复制代码
8 行目を印刷します
data.loc[8, column_1 ]复制代码
「column_1」という名前の列の 8 行目を印刷します
data.loc[range(4,6)]复制代码
4 行目から 6 行目 (左が閉じ、右が開きます) データ サブセット
pandas の基本機能
論理演算data[data[ column_1 ]== french ]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990)]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990) & ~(data[ city ]== London )]复制代码
論理演算を使用してデータのサブセットを取得します。 & (AND)、~ (NOT)、および | (OR) を使用するには、論理演算の前後に「and」を追加する必要があります。
data[data[ column_1 ].isin([ french , english ])]复制代码
同じ列で複数の OR を使用することに加えて、.isin() 関数を使用することもできます。
基本的なプロットmatplotlib パッケージにより、この機能が可能になります。冒頭で述べたように、これはパンダで直接使用できます。
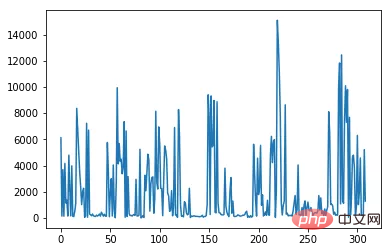
data[ column_numerical ].plot()复制代码
data[ column_numerical ].hist()复制代码
データ分布(ヒストグラム)を描画
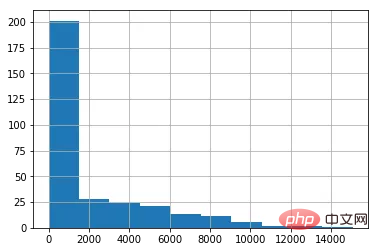
%matplotlib inline复制代码
データの更新
data.loc[8, column_1 ] = english 将第八行名为 column_1 的列替换为「english」复制代码
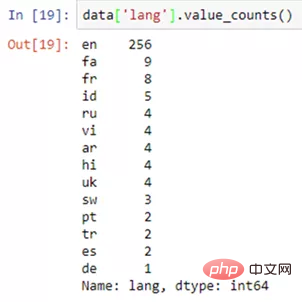
data.loc[data[ column_1 ]== french , column_1 ] = French复制代码1 行のコードで複数の列の値を変更するこれで、 で簡単にアクセスできる操作を行うことができます。エクセルの事。 Excelではできない素晴らしいことをいくつか掘り下げてみましょう。 中間関数出現回数をカウントする
data[ column_1 ].value_counts()复制代码
すべての行、列、またはすべてのデータに対する操作
data[ column_1 ].map(len)复制代码len() 関数は、「column_1」列の各要素に適用されます.map()操作は、列内の各要素に関数を適用します
data[ column_1 ].map(len).map(lambda x: x/100).plot()复制代码pandas の優れた機能は、チェーン メソッド (tomaugspurger.github.io/method-chai… および .plot( )) です。
data.apply(sum)复制代码.apply() は関数を列に適用します。 .applymap() はテーブル (DataFrame) 内のすべてのセルに関数を適用します。
tqdm、唯一の
在处理大规模数据集时,pandas 会花费一些时间来进行.map()、.apply()、.applymap() 等操作。tqdm 是一个可以用来帮助预测这些操作的执行何时完成的包(是的,我说谎了,我之前说我们只会使用到 pandas)。
from tqdm import tqdm_notebook tqdm_notebook().pandas()复制代码
用 pandas 设置 tqdm
data[ column_1 ].progress_map(lambda x: x.count( e ))复制代码
用 .progress_map() 代替.map()、.apply() 和.applymap() 也是类似的。

在 Jupyter 中使用 tqdm 和 pandas 得到的进度条
相关性和散射矩阵
data.corr() data.corr().applymap(lambda x: int(x*100)/100)复制代码
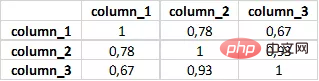
.corr() 会给出相关性矩阵
pd.plotting.scatter_matrix(data, figsize=(12,8))复制代码
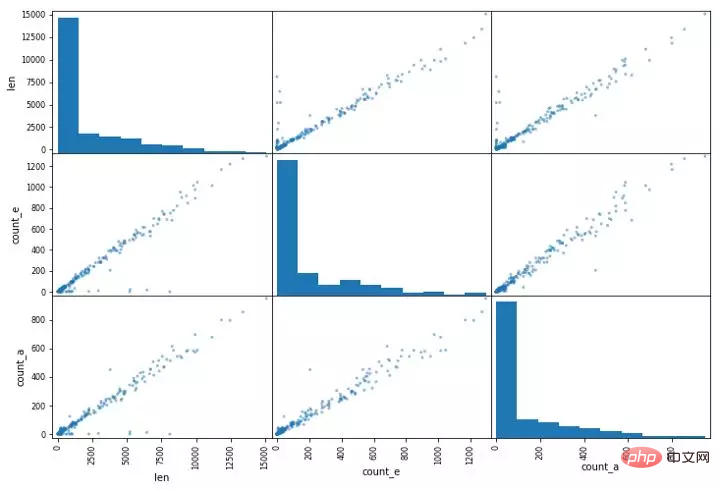
散点矩阵的例子。它在同一幅图中画出了两列的所有组合。
pandas 中的高级操作
The SQL 关联
在 pandas 中实现关联是非常非常简单的
data.merge(other_data, on=[ column_1 , column_2 , column_3 ])复制代码
关联三列只需要一行代码
分组
一开始并不是那么简单,你首先需要掌握语法,然后你会发现你一直在使用这个功能。
data.groupby( column_1 )[ column_2 ].apply(sum).reset_index()复制代码
按一个列分组,选择另一个列来执行一个函数。.reset_index() 会将数据重构成一个表。
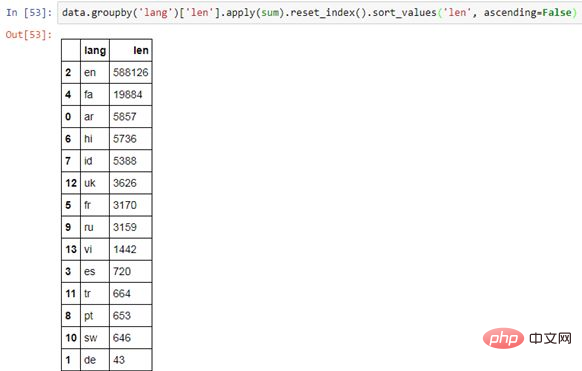
正如前面解释过的,为了优化代码,在一行中将你的函数连接起来。
行迭代
dictionary = {}
for i,row in data.iterrows():
dictionary[row[ column_1 ]] = row[ column_2 ]复制代码.iterrows() 使用两个变量一起循环:行索引和行的数据 (上面的 i 和 row)
总而言之,pandas 是 python 成为出色的编程语言的原因之一
我本可以展示更多有趣的 pandas 功能,但是已经写出来的这些足以让人理解为何数据科学家离不开 pandas。总结一下,pandas 有以下优点:
易用,将所有复杂、抽象的计算都隐藏在背后了;
直观;
快速,即使不是最快的也是非常快的。
它有助于数据科学家快速读取和理解数据,提高其工作效率
以上がパンダの最も詳細なチュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。