php 認証コード認識を実現するメソッド: まず画像を 2 値化し、値を 2 次元配列に保存し、次にループを通じて各数値の位置を見つけ、次に 2 つの数値内の数値の位置を計算します。 -次元配列内の位置を取得し、数値を連結し、最後に文字列を各フォントの文字列と比較して識別します。

推奨: 「PHP ビデオ チュートリアル 」
ただし、原文の導入部分は比較的簡単ですまた、アルゴリズムの具体的な実装プロセスについては言及されていません。詳細なプロセスは次から再現されています:
http://www.poboke.com/study/php-verification-code-identification-primary.html
つまり、これはこの記事は、PHP が検証コードを識別し、検証のためにサーバーに検証コードを送信するプロセスを示す実践的な例に基づいています。
パート 1: 検証コードの特定
最近、検証コードの知識における画期的な成果をいくつか調査し、記録しました。これは、ここ数日間で学んだ知識を自分自身の理解を助けるためにまとめたものである一方で、この側面を勉強している技術系の学生に役立つことを願っています。ウェブサイト管理者の注意を引き、確認コードを提供する際にさらに考慮してもらいたいと考えています。この分野の知識に触れたばかりなので、私の理解は比較的単純なので、間違いは避けられませんが、お気軽にコメントしてください。
検証コードの役割: ハッカーが特定のプログラムを使用して総当たり攻撃を行って、特定の登録ユーザーに対して継続的にログインを試行することを効果的に防ぎます。実際、最新の検証コードは一般に、マシンがバッチで登録したり、マシンがバッチで応答を投稿したりすることを防ぎます。現在、多くの Web サイトでは検証コード技術を使用して、ユーザーがロボットを使用して自動的に登録、ログイン、スパムを送信することを防止しています。
いわゆる認証コードは、ランダムに生成された数字や記号の列から画像を生成します。画像には (OCR を防ぐため) 干渉ピクセルが追加されています。ユーザーは視覚的に認証コード情報を識別できます。ウェブサイト認証を送信すると、認証が成功した場合のみ特定の機能が使用できるようになります。
当社で最も一般的な認証コード:
1. 4 桁、ランダムな 1 桁の文字列で、最も独創的な認証コードであり、認証効果はほぼゼロです。
2. ランダムなデジタル画像検証コード。絵上の文字は非常に規則的で、ランダムなインターフェロンが追加されているものや、文字の色がランダムなものもあるため、検証効果は以前のものより優れています。グラフィックや画像の基礎知識のない人には突破できません。
3. さまざまな画像形式の乱数、ランダムな大文字の英字、ランダムな干渉ピクセル、およびランダムな位置。
4. 漢字は登録用の最新の確認コードであり、ランダムに生成されるため、入力が難しくなり、ユーザー エクスペリエンスに影響を与えるため、一般的にはあまり使用されません。
簡単のため、今回は 1 番目のタイプについて説明しますが、まずインターネット上で一般的な確認コードの画像をいくつか見てみましょう。
これら 4 つのスタイルは、基本的に 2 で説明した検証コードのタイプを表すことができます。最初は、最初の図が最も解読しやすく、2 番目が 2 番目、3 番目がより困難、そして 4 番目が解読するのが最も簡単であるように見えます。クラックするのが最も簡単ですが、最も困難です。
実際の状況はどうですか?実際、これら 3 種類の画像の解読は同様に困難です。
最初の絵が一番簡単で、絵の背景と数字は同じ色で、文字は規則的で、文字の位置も同じです。この記事ではこのタイプの確認コードを例として使用しますが、学生が自分で他の画像を作成することもできます。
2枚目の写真は難しそうに見えますが、実はよく調べてみると法則が見えてきます 背景色やインターフェロンがどんなに変わっても、検証文字は規則正しく同じ色なので、とても簡単ですインターフェロンを除去するには、それがすべて非文字色素である限り、それを除外するだけです。
3枚目の写真はさらに複雑なようで、上記のように背景色とインターフェロンが変化するだけでなく、検証文字の色も変化しており、それぞれの文字の色も異なります。
4枚目の写真は、3枚目の写真に加えて、文字に干渉率の直線が2本追加されています。難しそうに見えますが、実は簡単に消すことができます。
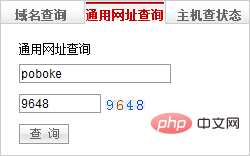
以下では、Wanwang の「一般 URL クエリ」を使用して、検証コードの識別プロセスを説明します。
Wanwang: http://www.net.cn を開くと、Web サイトの右側のサイドバーに「一般 URL クエリ」があります:
これは最初のA種の認証コードであることがわかり、人間の目で数字を認識できるように、デジタルカラーと認証コード画像の背景色の色差が比較的大きいため、RGB値も非常に高くなります。各ピクセルのRGB値を判断することで、数字と背景を区別することができます。
検証コードの識別は、一般に次のステップに分かれています:
1. フォントを取り出します
検証コードの識別、結局のところ、私は OCR 認識の専門家ではありません。Web サイトごとに検証コードが異なるため、最も一般的な方法は、この検証コードの署名ライブラリを構築することです。フォントを削除する場合は、すべての文字が含まれるようにさらにいくつかの画像をダウンロードする必要がありますが、ここの画像には数字しか含まれていないため、0 ~ 9 を含む数字の画像のみを収集する必要があります。
1. 確認コードを数回更新し、確認コードの画像を保存します。0 から 9 までのすべての画像を収集します。
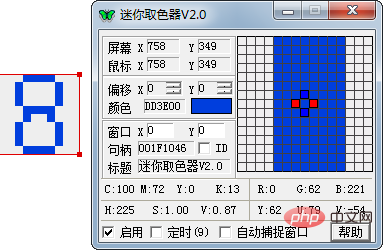
2. 画像処理ソフトウェアで画像を開きます。私は Fireworks を使用しています。ctrl 8 を押したままにすると、画像が 8 倍に拡大され、画像がはっきりと確認できます。すべてのピクセル。
各数字の幅は 6 ピクセル、高さは 10 ピクセル、数字間の間隔は 4 ピクセル、最初の数字は左側に 2 ピクセル、上部はオフセットされていることがわかります。 0px単位で。これらの番号は後で使用します。
3. 各数字を切り取って画像として保存します (サイズは 6*10)。
2. 画像の 2 値化
2 値化とは、画像上の検証番号の各ピクセルを 1 で表し、それ以外の部分を 0 で表すことです。手段。認識対象の画像を二値化して二次元配列に保存し、画像特徴配列を取得します。
1. まず、背景色と干渉色から数字を区別し、スクリーンのカラーピッカーを使用して色のパターンを観察します。
結論を導き出すことができます。背景色の R、G、B 値はすべて 200 より大きく、背景色の R、G、B 値のいずれか 1 つは、デジタルカラーは 200 未満の場合もあります。そのため、簡単に区別できます。
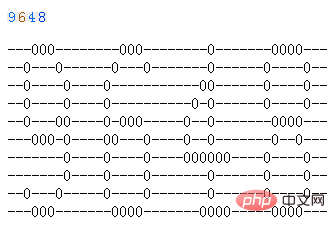
2. 次の PHP コードは、2 次元配列を示すためのものです。数値を視覚的に確認するために、1 と 0 は 0 と - に変更されています。
|
#1234
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
echo '<br><img src="v1.jpg"><br><br>';
getHec("v1.jpg");
関数 getHec($imagePath) {
#$res = imagecreatefromjpeg($imagePath);
#$サイズ = getimagesize($imagePath);
for ($i = 0; $i < $サイズ[1]; $i ) {
for ($j = 0; $j < $サイズ[0]; $j) {
$rgb = imagecolorat($res, $j, $i);
$rgbarray = imagecolorsforindex($res, $rgb )#;
if ($rgbarray[ '赤'] < 200 || $rgbarray['緑']<200 || $rgbarray['青'] #< 200) {
エコー "0";
}else{
echo " -「#;
}
}
echo "<br>";
}
}
|
結果は次の図に示されています:
画像の背景色がより複雑な場合でも、処理方法は同じです。区別するための臨界値を常に見つけることができます。自分で観察しなければなりません。
3. デジタルフォントの二値化
各デジタルフォントのバイナリデータを計算して記録し、キーとして使用します。
1. デジタルフォント画像を0~9まで2値化し、画像の各ピクセルの色を1つずつ取り出し、各ピクセルのR、G、B値を取得し、コードは次のとおりです:
|
#12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
for($i= 0;$i& lt;10;$ ###私###### ###){
echo"'$i'=>'";
echogetHec("$i.jpg")."',<br>";
}
関数getHec($imagePath)#{
#$res= #imagecreatefromjpeg($imagePath);
$size=getimagesize($imagePath);
for($i=0;$i<$サイズ[ 1]; $i){
for($j #=0;$j <$サイズ[0]; $j){
$rgb=imagecolorat($res,$j, #$i);
$rgbarray=インデックスのイメージカラー($res,$rgb )#;
if($rgbarray[ 'red']<200||$rgbarray[ '緑'######]###<200||$rgbarray['青']<200){
echo"1";
#}else{
echo# #" 0"; } }
}
}
|
##出力結果:
|
1
2
3
4
5
6
7
8
9
10
|
' 0'=>'011110100001100001100001100001100001100001100001100001011110',
'1'=>' 001000111000001000001000001000001000001000001000001000111110',
'2'=>'011110100001100001000001000010000100001000010000110011111111',
'3'=>' 011110100001100001000010001100000010000001100001100001011110',
'4'=>'000100000100001100010100100100100100111111000100001100001111',
'5'=>' 111111100000100000101110110001000001000001100001100001011110',
'6'=>'001110010001100000100000101110110001100001100001100001011110',
'7'=>' 111111100010100010000100000100001000001000001000001000001000',
'8'=>'011110100001100001100001011110010010100001100001100001011110',
'9'=>' 011100100010100001100001100011011101000001000001100010011100',
|
#4. ステップ 2 の画像特徴を比較するためのコントロール サンプル
コードをステップ 3 の検証コードのフォント パターンと比較して、検証画像上の数字を取得します。
アルゴリズム処理 (コードは添付ファイルを参照):
1. 画像の 2 値化値を 2 次元配列に保存します。
2. ループを通じて、前に取得した数値の幅、高さ、間隔、左オフセット、上オフセットを使用して、各数値の位置を見つけます。
例: i 番目の数値の左オフセット = (数値の幅の間隔) * i の左オフセット。 (w h 数字のグリフに似た文字列。
4. 文字列と各フォントの文字列を比較して類似度を求め、最も類似度が高い数値を取得するか、類似度が 95% 以上に達した場合にその数値であると判断します。
#5. 認識結果は以下の通りです:
現状の方法では、検証コードの認識率は基本的に100%となります。 上記の手順を通じて、インターフェロンを除去する方法がまだ見つからなかったと言ったかもしれません。実際、インターフェロンを除去する方法は非常に簡単です。インターフェロンの重要な特徴は、検証コードの表示効果に影響を与えないことです。そのため、インターフェロンを作成するときに、その RGB が特定の値より低い場合もあれば、高い場合もあります。私が挙げた例では、インターフェロンのRGB値は200以上になるため、インターフェロンを簡単に除去できます。
ソースコードのダウンロード: http://yunpan.cn/cmJCkEnyGij3t
アクセスパスワード d2ba
以上がPHPで検証コード認識を実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。