
RedisのLRUアルゴリズムの詳しい説明

- 藏色散人転載
- 2020-08-27 13:33:394260ブラウズ
次のコラム Redis チュートリアル では、Redis の LRU アルゴリズムについて詳しく説明します。困っている友人のお役に立てれば幸いです。

Redis の LRU アルゴリズム
LRU アルゴリズムの背後にある考え方はコンピューター サイエンスのいたるところに普及しており、プログラムの「局所性原理」と非常によく似ています。 。運用環境では、Redis のメモリ使用量アラームがありますが、それでも Redis のキャッシュ使用戦略を理解することは有益です。運用環境での Redis の使用戦略は次のとおりです。使用可能な最大メモリは 4 GB に制限されており、allkeys-lru 削除戦略が採用されています。いわゆる削除戦略: Redis の使用量が最大メモリ (4 GB など) に達したとき、この時点で新しいキーが Redis に追加されると、Redis は削除するキーを選択します。では、削除する適切なキーを選択するにはどうすればよいでしょうか?
CONFIG GET maxmemory
- "maxmemory"
- "4294967296"
CONFIG GET maxmemory-policy
- "maxmemory-policy"
- "allkeys-lru"
公式ドキュメント「LRU キャッシュとしての Redis の使用」の説明では、いくつかの説明が提供されています。 allkeys-lru、volatile-lru などのさまざまな削除戦略。私の意見では、選択する際には、ランダム性、キーが最近アクセスされた時間、キーの有効期限 (TTL)
# の 3 つの要素が考慮されます。例: allkeys-lru, "Count all"キーの履歴アクセス時間。「最も古い」キーを削除します。注: ここでは引用符を追加しましたが、実際、redis の特定の実装では、すべてのキーの最近のアクセス時間をカウントするのは非常にコストがかかります。考えてみてください、どうすればいいでしょうか?
新しいデータを追加するためのスペースを確保するために、最初にあまり使用されていない (LRU) キーを削除してキーを削除します。別の例: allkeys-ランダムとは、キーをランダムに選択して削除することを意味します。新しいデータを追加するためのスペースを確保するために、キーをランダムに削除します。
別の例: volatile-lru。expire コマンドを使用して期限切れになったキーのみを削除します。時間キーは、LRU アルゴリズムに従って削除されます。新しいデータのためのスペースを確保するために、最初にあまり使用されていない (LRU) キーを削除しようとしてキーを削除します。ただし、
有効期限が設定されたキーの間でのみです。追加しました。有効期限セット別の例: volatile-ttl は、expire コマンドを使用して有効期限が設定されているキーのみを削除します。どのキーの生存時間が短いか (TTL キーが小さいほど)、最初に移動し、削除します。
を使用してキーを削除し、新しいデータを追加するためのスペースを確保するために、最初に有効期間 (TTL) の短いキーを削除してみます。。ここで、expires 辞書のキーは、redis データベース キー スペース (redisServer) を指します。 -- ->redisDb--->redisObject)、expires ディクショナリの値は、このキーの有効期限 (long 型の整数) です。揮発性戦略 (エビクション方法) が機能するキーは、有効期限が設定されているキーです。 redisDb 構造では、expires という名前の辞書 (dict) が、
expired コマンドによって設定された有効期限を持つすべてのキーを保存するために定義されています
追加の説明: Redis データベースのキー スペースとは、構造体 redisDb で定義され、ハッシュ ディクショナリ型の「dict」という名前のポインタを指します。これは、redis DB に各キー オブジェクトを保存するために使用されます。および対応する値オブジェクト。 非常に多くの戦略があるので、どれを使用すればよいでしょうか?これには、Redis のキーのアクセス パターン (access-pattern) が関係します。アクセス パターンは、コードのビジネス ロジックに関連しています。たとえば、特定の特性を満たすキーには頻繁にアクセスされますが、他のキーはほとんど使用されません。すべてのキーがアプリケーションによってアクセスされる機会が等しい場合、そのアクセス パターンは一様分布に従います。ほとんどの場合、アクセス パターンは
べき乗則分布
捕捉 (キャプチャ) するには適切な削除戦略が必要です。電力指数分布の下では、LRU は優れた戦略です: キャッシュは将来を予測できませんが、次のように推論できます: 再び要求される可能性のあるキーは次のとおりです。最近頻繁にリクエストされたキー
。通常、アクセス パターンはそれほど突然変化しないため、これは効果的な戦略です。Redis での LRU 戦略の実装
最も直感的なアイデア: LRU、各キーの最新のアクセス時刻 (UNIX タイムスタンプなど) を記録します。UNIX タイムスタンプが最も小さいキーは最近使用されていないキーであり、このキーを削除します。 HashMapならできるようです。はい、ただし最初に各キーとそのタイムスタンプを保存する必要があります。次に、タイムスタンプを比較して最小値を取得する必要があります。コストは非常に高く、非現実的です。
2 番目の方法: 観点を変えて、特定のアクセス時点 (UNIX タイムスタンプ) を記録するのではなく、アイドル時間を記録します。アイドル時間が短いほど、最近アクセスされたことを意味します。
LRU アルゴリズムは、最も長く使用されていないキー、つまりアイドル時間が最も長いキーを削除します。
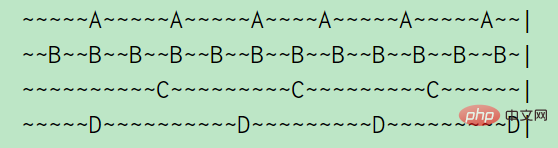
例: A、B 、 C 、 D の 4 つのキー、A は 5 秒ごとにアクセスされ、B は 2 秒ごとにアクセスされ、C と D は 10 秒ごとにアクセスされます。 (チルダは 1 秒を表します)、上の図からわかるように、A のアイドル時間は 2 秒、B のアイドル時間は 1 秒、C のアイドル時間は 5 秒、D はちょうど訪問したばかりなので、アイドル時間は 0 秒です
ここ、すべてのキーをリストするには、二重リンク リストを使用します。キーにアクセスした場合は、キーをリンク リストの先頭に移動します。キーを削除する場合は、リストの最後から直接削除します。
これは、特定のキーが最後にアクセスされた時刻を追跡するだけで済むため、実装が簡単です。場合によっては、これが必要ない場合もあります。必要なオブジェクトがすべて揃っているだけかもしれません。リンク リストでリンクされた削除。
しかし、redis では、LinkedList がスペースを取りすぎると考えられるため、この方法では実装されません。 Redis は、文字列、リンク リスト、辞書などのデータ構造に直接基づいて KV データベースを実装するのではなく、これらのデータ構造に基づいてオブジェクト システム Redis オブジェクトを作成します。 24 ビットの符号なしフィールドが redisObject 構造で定義され、コマンド プログラムによってオブジェクトが最後にアクセスされた時刻を保存します。
Redis オブジェクト構造を少し変更することで、24 ビットにすることができました。リンク リスト (ファット ポインタ!) でオブジェクトをリンクする余地はありませんでした。
結局のところ、最新の LRU アルゴリズムが削除されたとしても、完全に正確な LRU アルゴリズムは必要ありません。アクセスされたキーはほとんど影響しません。
#このメタデータを取得するために別のデータ構造を追加するという選択肢はありませんでしたが、LRU 自体が達成したいことの近似であるため、LRU 自体を近似するのはどうでしょうか?もともと Redis は次のように実装されました。 ランダムに 3 つのキーを選択し、アイドル時間が最も長いキーを削除します。その後、3 が設定可能なパラメータに変更され、デフォルトは N=5 になりました:
maxmemory-samples 5
キーを削除する必要がある場合は、ランダムなキーを 3 つ選択します。そしてアイドル時間が最も長いものを排除しますこれはとてもシンプルで、信じられないほどシンプルで、非常に効果的です。しかし、それでも欠点があります。ランダムに選択されるたびに、
歴史情報が使用されません。各ラウンドでキーを削除 (エビクト) する場合、N からランダムにキーを選択し、アイドル時間が最も大きいキーを削除します。次のラウンドでは、N からランダムにキーを選択します...考えたことはありますか? 過去:前回のラウンドでキーを削除するプロセスで、実際に N 個のキーのアイドル時間がわかったのですが、次のラウンドでキーを削除するときに、前のラウンドで学んだ情報の一部をうまく活用できますか?
しかし、このアルゴリズム最初から開始するのはあまりにも愚かです。そこで Redis は別の改善を行いました: バッファー プーリングを使用する 各ラウンドでキーが削除されると、N 個のキーのアイドル時間が取得されます。アイドル時間がプール内のキーよりも長い場合は、アイドル時間が取得されます。まだ大きい場合は、プールに追加します。このようにして、毎回削除されるキーは、ランダムに選択された N 個のキーの中で最大であるだけでなく、プール内のアイドル時間も最大になります。また、プール内のキーは複数回の比較ラウンドを通じて選別されており、そのアイドル時間はtime この時間は、ランダムに取得された Key のアイドル時間よりも大きくなる可能性が高く、プール内の Key には「過去の経験情報」が保持されていると理解できます。の実行全体を考えてみると、どのようにして大量の興味深いデータを廃棄しているかがわかります。おそらく、N 個のキーをサンプリングするときに、多くのデータに遭遇するでしょう。良い候補者を絞り込みましたが、その後は最良の候補者を排除し、次のサイクルで再び最初から開始します。
基本的に、N キーのサンプリングが実行されるとき、それはより大きなキーのプール (デフォルトではわずか 16 キー) を設定するために使用されました。このプールにはアイドル時間によってソートされたキーがあるため、新しいキーのみが含まれます。プール内のアイドル時間が 1 つのキーよりも長い場合、またはプールに空きスペースがある場合に、プールに入ります。「プール」を使用すると、グローバルな並べ替え問題がローカルな並べ替え問題に変換されます。比較の質問。 (並べ替えは本質的には比較ですが、囧)。アイドル時間が最大のキーを知るために、正確な LRU はグローバル キーのアイドル時間を並べ替えてから、アイドル時間が最大のキーを見つける必要があります。ただし、近似的なアイデアを採用することもできます。つまり、グローバル キーを表すいくつかのキーをランダムにサンプリングし、サンプリングによって取得したキーをプールに入れ、各サンプリング後にプールを更新することで、プール内のキーがランダムに選択されたキーの中でアイドル時間が最も長いキーが常に保存されます。エビクトキーが必要な場合は、アイドル時間が最も大きいキーをプールから直接取り出してエビクトします。この考え方は学ぶ価値があります。 この時点で、LRU ベースの削除戦略の分析は完了です。 Redis には LFU (アクセス頻度) に基づいた削除戦略もありますが、これについては後ほど説明します。
JAVA での
LRU 実装
JDK の LinkedHashMap は、次の構築メソッドを使用して LRU アルゴリズムを実装します。accessOrder は「最も最近使用されていない」測定標準を表します。たとえば、accessOrder=true は、java.util.LinkedHashMap#get 要素を実行するときに、この要素が最近アクセスされたことを意味します。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
次に、java.util.LinkedHashMap#removeEldestEntry メソッドを書き換えます。
#{@link #removeEldestEntry(Map.Entry)} メソッドをオーバーライドして、新しいマッピングがマップに追加されたときに古いマッピングを自動的に削除するポリシーを適用することができます。スレッドの安全性を確保するために、Collections.synchronizedMap を使用して LinkedHashMap オブジェクトをラップします:
この実装は同期されていないことに注意してください。複数のスレッドがリンクされたハッシュ マップに同時にアクセスし、少なくとも 1 つのスレッドがリンクされたハッシュ マップにアクセスする場合、スレッドの数はマップを構造的に変更するため、外部で同期する必要があります。これは通常、マップを自然にカプセル化するオブジェクトを同期することによって実現されます。次のように実装されます: (org.elasticsearch.transport.TransportService )
final Map<Long, TimeoutInfoHolder> timeoutInfoHandlers =
Collections.synchronizedMap(new LinkedHashMap<Long, TimeoutInfoHolder>(100, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > 100;
}
});容量が 100 を超えると、LRU 戦略が開始され、最も最近使用されていない TimeoutInfoHolder オブジェクトが削除されます。 参考リンク:
- Redis LRU アルゴリズム改善に関するランダムメモ
- Redis を LRU キャッシュとして使用する
5G には、あらゆる種類のノードがネットワークに接続できるようにする機能があり、大量のデータが生成されます。このデータを処理してマイニングする方法これらのデータは実際には人間の行動を客観的に反映しているため、背後に隠されたパターン (機械学習、深層学習) は非常に興味深いものです。たとえば、WeChat Sports の歩数計測機能を使用すると、次のことがわかります。ねえ、私の活動レベルは毎日約 10,000 歩であることがわかりました。さらに一歩進んで、将来的にはさまざまな産業機器や家電製品から、社会的な事業活動や人間の活動を反映するさまざまなデータが生成されるようになります。このデータを合理的に利用するにはどうすればよいでしょうか?既存のストレージ システムはこのデータのストレージをサポートできますか? データに隠された値を分析するための効率的なコンピューティング システム (Spark または tensorflow...) はありますか?さらに、これらのデータに基づいてトレーニングされたアルゴリズム モデルは、適用後にバイアスをもたらすのでしょうか?データの悪用はありますか?オンラインで物を購入するときに、アルゴリズムがおすすめのものを表示します。モーメントを閲覧しているときに、ターゲットを絞った広告が表示されます。また、モデルは、必要な金額と借りたい額を評価します。ニュースを読むときにも、アルゴリズムがおすすめを表示します。そしてエンターテイメントのゴシップ。私たちが毎日見たり触れたりするものの多くは、これらの「データ システム」によって決定されていますが、それらは本当に公平なのでしょうか?実際には、失敗しても先生や友達、家族がフィードバックや修正をしてくれ、修正すれば、またゼロからやり直すことができます。しかし、これらのデータ システムではどうなるでしょうか?エラー修正のためのフィードバック メカニズムはありますか?それは人々をますます深く沈めるよう刺激するでしょうか?たとえあなたが正しく、良い信用を持っていたとしても、アルゴリズム モデルには依然として確率的なバイアスが存在する可能性があります。これは人間にとっての「公正な競争」の機会に影響を与えますか?これらはデータ開発者にとって考慮に値する質問です。
以上がRedisのLRUアルゴリズムの詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。