
ホームページ >バックエンド開発 >PHPチュートリアル >PHP でクローラーを実装するプロセスを理解するには 10 分かかります
PHP でクローラーを実装するプロセスを理解するには 10 分かかります
- 烟雨青岚転載
- 2020-07-16 13:49:483835ブラウズ

#テキスト情報
テーブル情報を取得しようとします。ここでは、あるクラスのスケジュールを使用します。 :

#a.php
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url ="表的链接";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch);
preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER);//匹配该表所用的正则
var_dump($matchs);
 授業スケジュールが正常に取得されました;
授業スケジュールが正常に取得されました;
画像の取得
絶対リンク
Baidu Gallery のホームページを例に挙げます
b.php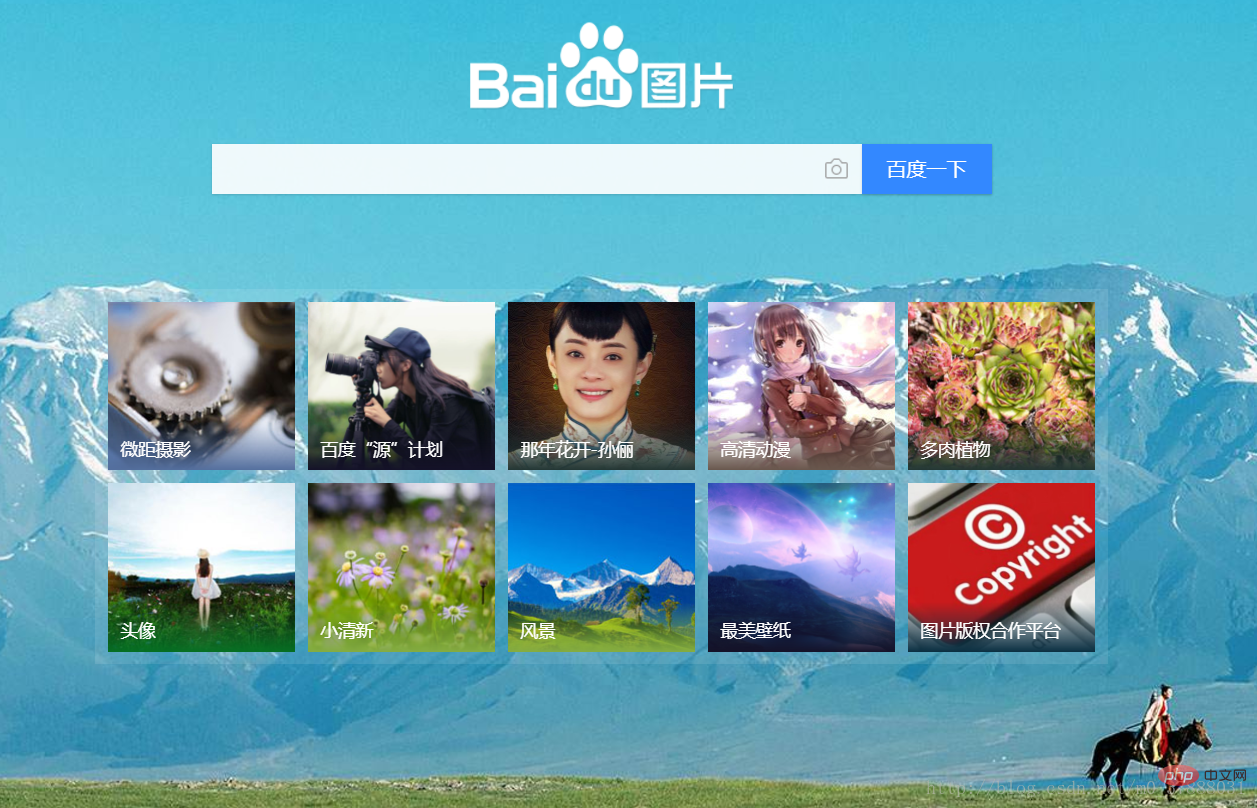
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url="http://image.baidu.com/";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); $string=file_get_contents($url);
preg_match_all("/<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/image/301/164/948/1594878376637006.png" class="lazy" ([^ alt="PHP でクローラーを実装するプロセスを理解するには 10 分かかります" >]*)\s*src=('|\")([^'\"]+)('|\")/",
$string,$matches); $new_arr=array_unique($matches[3]); foreach($new_arr as $key){
echo "<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/image/301/164/948/1594878376637006.png" class="lazy" src=$key alt="PHP でクローラーを実装するプロセスを理解するには 10 分かかります" >";
}すると、次のページが表示されます。 :

Baidu Gallery の画像へのリンクのほとんどは絶対リンクなので、Web ページの画像に遭遇したときこれは相対リンク時間です。どのように対処すればよいでしょうか?実はとても簡単で、ループ部分を
 # に変更するだけで、画像をブラウザに出力することもできます;
# に変更するだけで、画像をブラウザに出力することもできます;
読んでいただきありがとうございます、皆さんが恩恵を受けることを願っています。
推奨チュートリアル:「
php チュートリアル以上がPHP でクローラーを実装するプロセスを理解するには 10 分かかりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。