
ホームページ >バックエンド開発 >Python チュートリアル >クローラーの解析方法 4: PyQuery
クローラーの解析方法 4: PyQuery

- 爱喝马黛茶的安东尼転載
- 2019-06-05 15:14:533468ブラウズ
多くの言語でクロールできますが、python に基づくクローラーはより簡潔で便利です。クローラーも Python 言語の重要な部分になっています。クローラーを解析する方法もたくさんあります。前回の記事では、 クローラーを解析する 3 番目の方法である正規表現 について説明しましたが、今日は別の方法である PyQuery について説明します。

PyQuery
PyQuery ライブラリは、非常に強力で柔軟な Web ページ解析ライブラリでもあります。経験があれば、それを使用できます。jQuery を使用したことがある場合は、PyQuery が最適です。PyQuery は、jQuery をモデルとした Python の厳密な実装です。構文は jQuery とほぼ同じなので、変なメソッドを覚えようとする必要はもうありません。
初期化中に渡すには、通常、文字列で渡す、URL で渡す、ファイルで渡すという 3 つの方法があります。
文字列の初期化
html =
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
from pyquery
import PyQuery as pq
doc = pq(html)print(doc)
print(type(doc))
print(doc('li'))結果は次のとおりです。
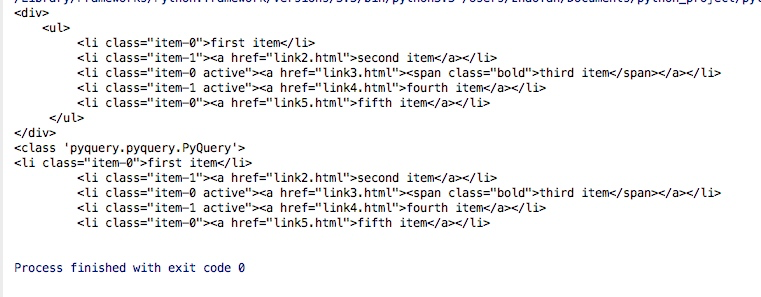
PyQuery は書くのが面倒なので、
from pyquery import PyQuery as pq
ここで、上記のコードの doc が実際には pyquery オブジェクトであることがわかります。doc を通じて要素を選択できます。実際、これは次のとおりです。 CSS セレクターなので、すべての CSS セレクター ルールを使用できます。直接 doc (タグ名) を実行して、タグのすべてのコンテンツを取得できます。クラスを取得したい場合は、doc('.class_name') を使用します。 ID、次に doc('#id_name') ...
URL 初期化
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')print(doc('head'))
ファイル初期化
URL パラメータを渡すことができますまたは、 pq() 内のファイルパラメータ。もちろん、ここでのファイルは通常 HTML ファイルです。例: pq(filename='index.html')
Basic CSS selector
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''
from pyquery import PyQuery as pq
doc = pq(html)
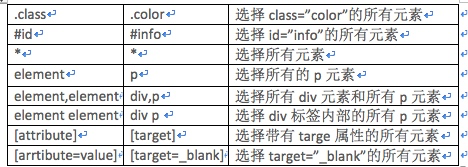
print(doc('#container .list li'))Oneここで注意する必要があるのは doc ('#container .list li') です。階層関係があれば、ここで 3 つが隣り合う必要はありません。一般的に使用される CSS は次のとおりです。セレクター メソッド:
要素の検索
子要素
children,find
Code例:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)実行結果は次のとおりです
結果から、pyquery で見つかった結果が実際には pyquery オブジェクトであることもわかり、検索を続行できます。上記のコードの ('li') は、ul 内のすべての li を検索することを意味します。
li = items.children() print(type(li)) print(li)
同時に、CSS セレクターは子でも使用できます
li2 = items.children('.active') print(li2)
親要素
parent,parents メソッド
例は次のとおりです:
html = '''<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)You can find the先祖ノード through .parents 内容と例は次のとおりです:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)結果は次のとおりです:結果から、コンテンツの 2 つの部分が返されたことがわかります。1 つは親ノードの情報で、もう 1 つは親ノードの親ノードの情報、つまり祖先ノードの情報です。
同様に、.parents を検索する場合、CSS セレクターを追加してコンテンツをフィルターすることもできます
兄弟要素siblings
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())doc('.list .item-0.active') のコード .tem-0 と .active は互いに隣接しているため、マージされた関係にあり、条件を満たすものは 1 つだけ残ります。 3 番目の項目 そのタグ この方法で、.siblings を通じてすべての兄弟タグを取得できます。もちろん、ここには独自のタグは含まれません。
同様に、.siblings() では、CSS セレクターを介してフィルター処理することもできます。
単一要素
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
lis = doc('li').items()
print(type(lis))for li in lis:
print(type(li))
print(li)実行結果は次のとおりです。 結果から、ジェネレーターは items() を通じて取得できます。また、for ループを通じて取得した各要素は依然として pyquery オブジェクトです。
属性の取得
pyquery object.attr(属性名)pyquery object.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)したがって、ここで、属性値を取得するときに、直接 a.attr (属性名) または a.attr.attribute name テキストを取得できることもわかります
多くの場合、html タグに含まれるテキスト情報を取得する必要があります。テキスト情報は .text()
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())によって取得できます。結果は次のようになります。

Get html
現在のタグに含まれる HTML 情報は、.html() を通じて取得できます。例は次のとおりです。
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())結果は次のとおりです。
 DOM 操作
DOM 操作
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())结果如下:

以上がクローラーの解析方法 4: PyQueryの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。