
ホームページ >データベース >mysql チュートリアル >mysql ストレージ エンジンの違いは何ですか?
mysql ストレージ エンジンの違いは何ですか?

- 清浅オリジナル
- 2019-05-06 11:33:124475ブラウズ
MySQL のストレージ エンジンの違い: Innodb と myisam を例に挙げると、前者はトランザクションをサポートしますが、後者はサポートしません。前者は汎用性を重視し、より拡張された機能をサポートしますが、後者は主にパフォーマンスに重点を置きます。
INNODB
INNODB インデックスの実装
MyISAM と同じことは、InnoDB も B Tree を使用することです。 B-Treeインデックスを実装するためのデータ構造。大きな違いは、InnoDB ストレージ エンジンが B ツリー インデックスを実装するために「クラスター化インデックス」データ保存方法を使用していることです。いわゆる「集約」とは、データ行と隣接するキー値がまとめてコンパクトに保存されることを意味しますInnoDB では、リーフ ページ (16K) のレコードのみが集約される (つまり、クラスタード インデックスが一定の範囲のレコードを満たす) ため、隣接するキー値を含むレコードが大きく離れている可能性があることに注意してください。 InnoDB では、テーブルはインデックス構成テーブルと呼ばれます。InnoDB は主キーに従って B ツリーを構築します (主キーがない場合は、代わりに一意の空でないインデックスが選択されます)。主キーがない場合、代わりに一意で空でないインデックスが選択されます。そのようなインデックスの場合、InnoDB は主キーをクラスター化インデックスとして暗黙的に定義し、同時にリーフ ページには次の行レコード データが保存されます。テーブル全体 クラスター化インデックスのリーフ ノードはデータ ページと呼ぶこともできます 非リーフ ページも表示できます リーフ ページのスパース インデックスを実行します。 次の図は、InnoDB クラスター化インデックスの実装を示し、innoDB テーブルの構造も反映しています。InnoDB では、主キー インデックスとデータが分離されておらず、統合されていることがわかります。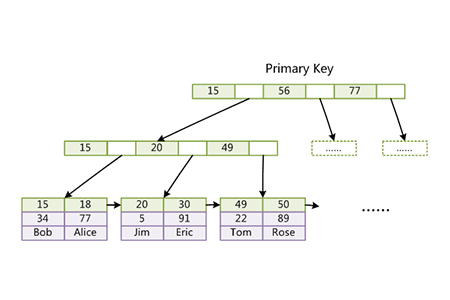
フル テーブル スキャン
InnoDB がフル テーブル スキャンを実行する場合、InnoDB は実際には順次に読み取らないため、効率的ではありません。ほとんどの場合、ランダムに読み取られます。 。フル テーブル スキャンを実行する場合、InnoDB は主キーの順序でページと行をスキャンします。これは、断片化されたテーブルを含むすべての InnoDB テーブルに適用されます。主キー ページ テーブル (主キーと行を格納するページ テーブル) が断片化されていない場合、読み取り順序が物理的な記憶順序に近いため、テーブル全体のスキャンは非常に高速になります。ただし、主キー ページが断片化されている場合、スキャンは非常に遅くなります。行レベル ロック
Oracle で提供される行ロック (行レベルでのロック) を提供します。 SELECT でのタイプ一貫性のある非ロック読み取り。また、InnoDB テーブルの行ロックは絶対的ではありません。SQL ステートメントの実行時に MySQL がスキャンする範囲を決定できない場合、InnoDB テーブルはテーブル全体もロックします。update table set num=1 where name like “%aaa%”
MYISAM
MyISAM インデックスの実装
各 MyISAM はディスク上に 3 つのファイルとして保存されます。最初のファイルの名前はテーブルの名前で始まり、拡張子はファイルの種類を示します。 MyISAM インデックス ファイル [.MYI (MYIndex)] とデータ ファイル [.MYD (MYData)] は分離されており、インデックス ファイルにはレコードが配置されているページのポインタ (物理的な場所) のみが保存されます。これらのアドレスを指定すると、ページが読み取られ、インデックス付きの行が読み取られます。まず構造図を見てみましょう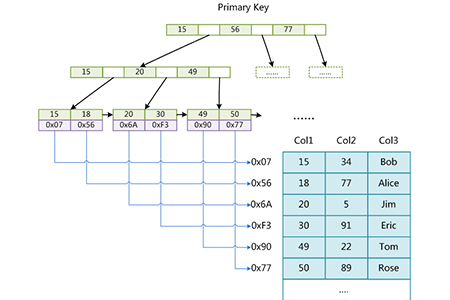
MyISAM はデフォルトでインデックスをメモリに読み取り、メモリ内で直接操作します;
テーブルレベルのロック要約: Innodb は汎用性を重視し、サポートされている拡張機能を比較します。関数は多く、myisam は主にパフォーマンスに重点を置いています
相違点1. InnoDB はトランザクションをサポートしますが、MyISAM はサポートしません。InnoDB の場合、すべての SQL 言語はトランザクションにカプセル化されます。デフォルトで自動的に送信されますが、これは速度に影響するため、begin と commit の間に複数の SQL ステートメントを入れてトランザクションを形成することをお勧めします;
2. InnoDB はクラスター化インデックスであり、データ ファイルは主キーが必要であり、主キーを使用したインデックス作成は非常に効率的です。ただし、補助インデックスには 2 つのクエリが必要です。最初に主キーをクエリし、次に主キーを介してデータをクエリします。したがって、主キーが大きすぎると、他のインデックスも大きくなるため、主キーは大きすぎないでください。 MyISAM は非クラスター化インデックスであり、データ ファイルは分離されており、インデックスにはデータ ファイルのポインタが保存されます。主キーインデックスと副キーインデックスは独立しています。
3. InnoDB はテーブル内の特定の行数を保存しないため、テーブルから select count(*) を実行する場合、テーブル全体のスキャンが必要です。 MyISAM は変数を使用してテーブル全体の行数を保存します。上記のステートメントを実行するときは、変数を読み取るだけで済みます。これは非常に高速です。
4. Innodb はフルテキスト インデックスをサポートしていません、MyISAM はフルテキスト インデックスをサポートしていますが、クエリ効率の点では MyISAM の方が優れています;
以上がmysql ストレージ エンジンの違いは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。