


この記事の内容は、Pandas による Python による Excel の読み取りと変更の操作ガイド (コード例) に関するもので、一定の参考価値があります。必要な友人は参考にしてください。お役に立てれば幸いです。
環境: python 3.6.8
例として特定の Miser 番号を取り上げてみましょう:


>>> pd.read_excel('1.xlsx', sheet_name='Sheet2')
名字 等级 属性1 属性2 天赋
0 四九幻曦 100 自然 None 21
1 圣甲狂战 100 战斗 None 0
2 时空界皇 100 光 次元 27
ここでは、Excel を読み取るために pd.read_excel() 関数を使用します。read_excel() の API を見てみましょう。ここでは、一部の一般的なもののみをインターセプトします。使用パラメータ:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
io: 明らかに、これは Excel ファイル
のパス名文字列です (中国語がある場合は、python2##) # Laotie は decode() を使用して unicode 文字列 ) にデコードする必要があります 例:
>>> pd.read_excel('例子'.decode('utf-8))
sheet_nameusecols:指定した列には、名前またはインデックス値を使用することもできます: 指定されたものを返しますsheet
sheet_nameがNoneとして指定されている場合、シート全体が返されます。複数のシートを返す必要がある場合は、
sheet_name ## を返すことができます。 #['sheet1', 'sheet2'] のようにリストとして指定します。## の名前文字列またはインデックスに基づいて、選択したsheet
を指定できます。 #sheet<pre class="brush:php;toolbar:false">>>> # 如: >>> pd.read_excel('1.xlsx', sheet_name=0) >>> pd.read_excel('1.xlsx', sheet_name='Sheet1') >>> # 返回的是相同的 DataFrame</pre>header: データ テーブルのヘッダーを指定します。デフォルト値は 0 です。つまり、最初の行がヘッダーとして使用されます。
>>> # 如:
>>> pd.read_excel('1.xlsx', sheet_name=1, usecols=['等级', '属性1'])
>>> pd.read_excel('1.xlsx', sheet_name=1, usecols=[1,2])
>>> # 返回的是相同的 DataFrame.ilocまたは # を使用することもできます##.loc
オブジェクト<pre class="brush:php;toolbar:false">>>> # 读取文件
>>> data = pd.read_excel("1.xlsx", sheet_name="Sheet1")
>>> # 找到 等级 这一列,再在这一列中进行比较
>>> data['等级'][data['名字'] == '泰格尔'] += 1
>>> print(data)</pre>見てください!彼はアップグレードされました! ! <pre class="brush:php;toolbar:false">>>> data
名字 等级 属性1 属性2 天赋
0 艾欧里娅 100 自然 冰 29
1 泰格尔 81 电 战斗 16
2 布鲁克克 100 水 None 28</pre>これを保存します
data.to_excel('1.xlsx', sheet_name='Sheet1', index=False, header=True)
index: デフォルトは
Trueです。行インデックスを追加するかどうかは、上の図に移動するだけです。
True左は
False、右は
 、右は
、右は ヘッダー: デフォルトはTrueです。柱マークを付けて絵を描いてみよう!
左側はpd.read_excel()False、右側は
Trueとio、sheet_nameパラメーターの使用法は同じです関数

data['列名'] = [値 1, 値 2, ...]として、さらに数匹の動物を捕獲したり、さらにいくつかの属性を追加したりするとどうなるでしょうか?参照はここにあります:新しい列データ:
>>> data['特性'] = ['瞬杀', 'None', '炎火'] >>> data 名字 等级 属性1 属性2 天赋 特性 0 艾欧里娅 100 自然 冰 29 瞬杀 1 泰格尔 80 电 战斗 16 None 2 布鲁克克 100 水 None 28 炎火新しい行データ、番号ここでの行の ID 値は、Excel の行に自動的に追加される
data.loc[行の番号] = [値 1, 値 2, ...], (違い)
.iloc との違いに注意してください)
>>> data.loc[3] = ['小火猴', 1, '火', 'None', 31, 'None'] >>> data 名字 等级 属性1 属性2 天赋 特性 0 艾欧里娅 100 自然 冰 29 瞬杀 1 泰格尔 80 电 战斗 16 None 2 布鲁克克 100 水 None 28 炎火 3 小火猴 1 火 None 31 None
行または列を追加した後、行または列を削除するにはどうすればよいですか?
.drop()function>>> # 删除列, 需要指定axis为1,当删除行时,axis为0
>>> data = data.drop('属性1', axis=1) # 删除`属性1`列
>>> data
名字 等级 属性2 天赋 特性
0 艾欧里娅 100 冰 29 瞬杀
1 泰格尔 80 战斗 16 None
2 布鲁克克 100 None 28 炎火
3 小火猴 1 None 31 None
>>> # 删除第3,4行,这里下表以0开始,并且标题行不算在类, axis用法同上
>>> data = data.drop([2, 3], axis=0)
>>> data
名字 等级 属性2 天赋 特性
0 艾欧里娅 100 冰 29 瞬杀
1 泰格尔 80 战斗 16 None
>>> # 保存
>>> data.to_excel('2.xlsx', sheet_name='Sheet1', index=False, header=True)
を使用できます。
以上がパンダは Python で Excel 操作戦略を読み取り、変更します (コード例)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 python pandas安装方法Nov 22, 2023 pm 02:33 PM
python pandas安装方法Nov 22, 2023 pm 02:33 PMpython可以通过使用pip、使用conda、从源代码、使用IDE集成的包管理工具来安装pandas。详细介绍:1、使用pip,在终端或命令提示符中运行pip install pandas命令即可安装pandas;2、使用conda,在终端或命令提示符中运行conda install pandas命令即可安装pandas;3、从源代码安装等等。
 日常工作中,Python+Pandas是否能代替Excel+VBA?May 04, 2023 am 11:37 AM
日常工作中,Python+Pandas是否能代替Excel+VBA?May 04, 2023 am 11:37 AM知乎上有个热门提问,日常工作中Python+Pandas是否能代替Excel+VBA?我的建议是,两者是互补关系,不存在谁替代谁。复杂数据分析挖掘用Python+Pandas,日常简单数据处理用Excel+VBA。从数据处理分析能力来看,Python+Pandas肯定是能取代Excel+VBA的,而且要远远比后者强大。但从便利性、传播性、市场认可度来看,Excel+VBA在职场工作上还是无法取代的。因为Excel符合绝大多数人的使用习惯,使用成本更低。就像Photoshop能修出更专业的照片,为
 如何使用Python中的Pandas按特定列合并两个CSV文件?Sep 08, 2023 pm 02:01 PM
如何使用Python中的Pandas按特定列合并两个CSV文件?Sep 08, 2023 pm 02:01 PMCSV(逗号分隔值)文件广泛用于以简单格式存储和交换数据。在许多数据处理任务中,需要基于特定列合并两个或多个CSV文件。幸运的是,这可以使用Python中的Pandas库轻松实现。在本文中,我们将学习如何使用Python中的Pandas按特定列合并两个CSV文件。什么是Pandas库?Pandas是一个用于Python信息控制和检查的开源库。它提供了用于处理结构化数据(例如表格、时间序列和多维数据)以及高性能数据结构的工具。Pandas广泛应用于金融、数据科学、机器学习和其他需要数据操作的领域。
 时间序列特征提取的Python和Pandas代码示例Apr 12, 2023 pm 05:43 PM
时间序列特征提取的Python和Pandas代码示例Apr 12, 2023 pm 05:43 PM使用Pandas和Python从时间序列数据中提取有意义的特征,包括移动平均,自相关和傅里叶变换。前言时间序列分析是理解和预测各个行业(如金融、经济、医疗保健等)趋势的强大工具。特征提取是这一过程中的关键步骤,它涉及将原始数据转换为有意义的特征,可用于训练模型进行预测和分析。在本文中,我们将探索使用Python和Pandas的时间序列特征提取技术。在深入研究特征提取之前,让我们简要回顾一下时间序列数据。时间序列数据是按时间顺序索引的数据点序列。时间序列数据的例子包括股票价格、温度测量和交通数据。
 pandas写入excel有哪些方法Nov 22, 2023 am 11:46 AM
pandas写入excel有哪些方法Nov 22, 2023 am 11:46 AMpandas写入excel的方法有:1、安装所需的库;2、读取数据集;3、写入Excel文件;4、指定工作表名称;5、格式化输出;6、自定义样式。Pandas是一个流行的Python数据分析库,提供了许多强大的数据清洗和分析功能,要将Pandas数据写入Excel文件,可以使用Pandas提供的“to_excel()”方法。
 pandas如何读取txt文件Nov 21, 2023 pm 03:54 PM
pandas如何读取txt文件Nov 21, 2023 pm 03:54 PMpandas读取txt文件的步骤:1、安装Pandas库;2、使用“read_csv”函数读取txt文件,并指定文件路径和文件分隔符;3、Pandas将数据读取为一个名为DataFrame的对象;4、如果第一行包含列名,则可以通过将header参数设置为0来指定,如果没有,则设置为None;5、如果txt文件中包含缺失值或空值,可以使用“na_values”指定这些缺失值。
 pandas怎么读取csv文件Dec 01, 2023 pm 04:18 PM
pandas怎么读取csv文件Dec 01, 2023 pm 04:18 PM读取CSV文件的方法有使用read_csv()函数、指定分隔符、指定列名、跳过行、缺失值处理、自定义数据类型等。详细介绍:1、read_csv()函数是Pandas中最常用的读取CSV文件的方法。它可以从本地文件系统或远程URL加载CSV数据,并返回一个DataFrame对象;2、指定分隔符,默认情况下,read_csv()函数将使用逗号作为CSV文件的分隔符等等。
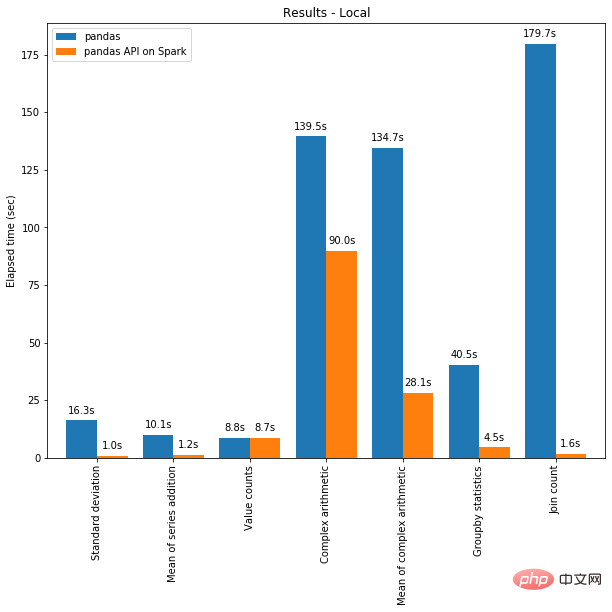 Pandas 与 PySpark 强强联手,功能与速度齐飞!May 01, 2023 pm 09:19 PM
Pandas 与 PySpark 强强联手,功能与速度齐飞!May 01, 2023 pm 09:19 PM使用Python做数据处理的数据科学家或数据从业者,对数据科学包pandas并不陌生,也不乏像云朵君一样的pandas重度使用者,项目开始写的第一行代码,大多是importpandasaspd。pandas做数据处理可以说是yyds!而他的缺点也是非常明显,pandas只能单机处理,它不能随数据量线性伸缩。例如,如果pandas试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。另外pandas在处理大型数据方面非常慢,虽然有像Dask或Vaex等其他库来优化提升数


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SublimeText3 中国語版
中国語版、とても使いやすい

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン
ホットトピック
 7448
7448 15137452
15137452