
ホームページ >Java >&#&チュートリアル >Javaweb でのテーブル クエリの SQL 最適化の概要
Javaweb でのテーブル クエリの SQL 最適化の概要

- 不言転載
- 2018-10-12 14:35:282669ブラウズ
この記事では、Javaweb でのテーブル クエリの SQL 最適化について説明します。必要な方は参考にしていただければ幸いです。
背景
この SQL 最適化は、Javaweb のテーブル クエリに対して行われます。
部分的なネットワーク アーキテクチャ図
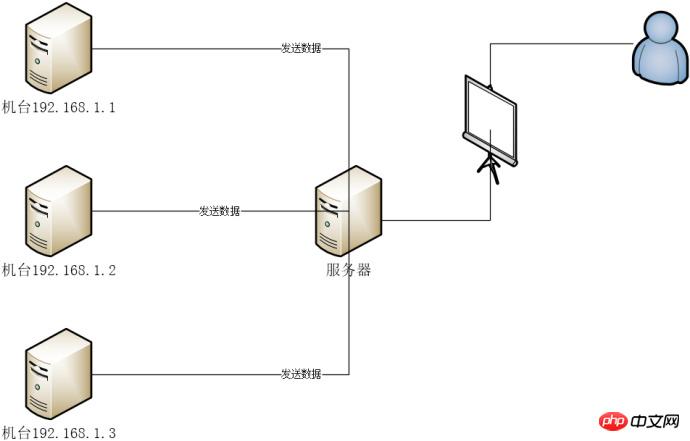
- Windows の単一マシンのマスター/スレーブ分離
- はテーブルとデータベースに分割されており、データベースは年ごとに分割されています。Talent テーブル
- 各テーブルには約 200,000 のデータが含まれます
- ドルイドを構成すると、ドルイド上の SQL 実行時間と URI リクエストを直接表示できます。 page Time
- バックグラウンド コードで System.currentTimeMillis を使用して、時差を計算します。
- SQLスプライシングが長すぎて 3,000 行、場合によっては 8,000 行に達します。そのほとんどがすべてユニオン操作であり、不要なネストされたクエリとクエリされる不要なフィールドがあります。
- Explain を使用して実行を表示します。 plan 、 time を除き、where 条件の 1 つのフィールドだけがインデックスを使用します
- たとえば、union all演算を分解します(union all SQLも非常に長いです)
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_02 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_03 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
上記の SQL をいくつかの SQL に分解して実行し、最終的にデータを要約することで 20 秒ほど速くなります。
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where ..
分解された SQL を非同期で実行する
Java 非同期プログラミング操作を使用して、実行します分解された SQL を非同期的に処理し、最後にデータを要約します。ここでは CountDownLatch と ExecutorService が使用されています。サンプル コードは次のとおりです。
// 获取时间段所有天数
List<String> days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());
// 天数长度
int length = days.size();
// 初始化合并集合,并指定大小,防止数组越界
List<你想要的数据类型> list = Lists.newArrayListWithCapacity(length);
// 初始化线程池
ExecutorService pool = Executors.newFixedThreadPool(length);
// 初始化计数器
CountDownLatch latch = new CountDownLatch(length);
// 查询每天的时间并合并
for (String day : days) {
Map<String, Object> param = Maps.newHashMap();
// param 组装查询条件
pool.submit(new Runnable() {
@Override
public void run() {
try {
// mybatis查询sql
// 将结果汇总
list.addAll(查询结果);
} catch (Exception e) {
logger.error("getTime异常", e);
} finally {
latch.countDown();
}
}
});
}
try {
// 等待所有查询结束
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// list为汇总集合
// 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了
結果は 20 ~ 30 秒速くなります。
MySQL 構成を最適化します。
##以下は私の構成の例です。 Skip-name-resolve が追加され、4 ~ 5 秒速くなりました。その他の構成は自分で決定します[client] port=3306 [mysql] no-beep default-character-set=utf8 [mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin slave-skip-errors=all #跳过所有错误 skip-name-resolve port=3306 datadir="D:/mysql-slave/data" character-set-server=utf8 default-storage-engine=INNODB sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" log-output=FILE general-log=0 general_log_file="WINDOWS-8E8V2OD.log" slow-query-log=1 slow_query_log_file="WINDOWS-8E8V2OD-slow.log" long_query_time=10 # Binary Logging. # log-bin # Error Logging. log-error="WINDOWS-8E8V2OD.err" # 整个数据库最大连接(用户)数 max_connections=1000 # 每个客户端连接最大的错误允许数量 max_connect_errors=100 # 表描述符缓存大小,可减少文件打开/关闭次数 table_open_cache=2000 # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要) # 每个连接独立的大小.大小动态增加 max_allowed_packet=64M # 在排序发生时由每个线程分配 sort_buffer_size=8M # 当全联合发生时,在每个线程中分配 join_buffer_size=8M # cache中保留多少线程用于重用 thread_cache_size=128 # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量. thread_concurrency=64 # 查询缓存 query_cache_size=128M # 只有小于此设定值的结果才会被缓冲 # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖 query_cache_limit=2M # InnoDB使用一个缓冲池来保存索引和原始数据 # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少. # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80% # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸. innodb_buffer_pool_size=1G # 用来同步IO操作的IO线程的数量 # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好. innodb_read_io_threads=16 innodb_write_io_threads=16 # 在InnoDb核心内的允许线程数量. # 最优值依赖于应用程序,硬件以及操作系统的调度方式. # 过高的值可能导致线程的互斥颠簸. innodb_thread_concurrency=9 # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘. # 1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上 # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上 innodb_flush_log_at_trx_commit=2 # 用来缓冲日志数据的缓冲区的大小. innodb_log_buffer_size=16M # 在日志组中每个日志文件的大小. innodb_log_file_size=48M # 在日志组中的文件总数. innodb_log_files_in_group=3 # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久. # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务. # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎 # 那么一个死锁可能发生而InnoDB无法注意到. # 这种情况下这个timeout值对于解决这种问题就非常有帮助. innodb_lock_wait_timeout=30 # 开启定时 event_scheduler=ONビジネスに応じて、さらにフィルタリング条件を追加しますすぐに 4 ~ 5 秒追加where 条件 時間条件以外のフィールドの結合インデックスを確立する 効果はそれほど明らかではありません内部結合メソッドを使用して、where 条件のインデックス条件を関連付けます
これには私自身とても驚いています。元の SQL、b はインデックス
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'です。前に Union all があるはずで、union all が 1 つずつ実行され、最終的な集計結果は次のようになります。得られた。
select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join
(
select 'xxx1' as b2
union all
select 'xxx2' as b2
union all
select 'xxx3' as b2
union all
select 'xxx3' as b2
) t on b = t.b2
結果は 3 ~ 4 秒速くなりますパフォーマンスのボトルネック上記の操作によると、クエリは3 日で効率が向上しました。約 8 秒に達し、これ以上速くすることはできませんでした。 MySQL の CPU 使用率とメモリ使用率はそれほど高くありません。なぜクエリがそれほど遅いのでしょうか? データの最大数は 3 日間で 600,000 件です。ネットの情報に頼り続けて、一連のエッチな作戦は基本的には無駄で仕方がありません。 環境比較SQL 最適化を分析した後、それがディスクの読み取りと書き込みの問題であるかどうかを想像してみてください。最適化されたプログラムをさまざまなオンサイト環境に展開します。 1つはSSDを搭載し、もう1つはSSDを搭載しません。クエリ効率が大きく異なることがわかりました。ソフトウェアでテストした結果、SSDの読み取りおよび書き込み速度は700〜800M/sで、通常の機械式ハードディスクの読み取りおよび書き込み速度は70〜80M/sであることがわかりました。 最適化の結果と結論
最適化の結果: 期待に応えます。 - 最適化の結論: SQL の最適化は、SQL 自体の最適化だけでなく、SQL 自体のハードウェア条件、他のアプリケーションの影響、および独自のコードの最適化にも依存します。
- 上記はこの記事の全内容です。Java に関するさらに興味深い情報については、 Java ビデオ チュートリアル
Java 開発を参照してください。 PHP 中国語 Web サイトのチュートリアル。 ! !
以上がJavaweb でのテーブル クエリの SQL 最適化の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はcnblogs.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。