
ホームページ >バックエンド開発 >Python チュートリアル >Python の前処理とヒートマップの簡単な紹介
Python の前処理とヒートマップの簡単な紹介

- 不言転載
- 2018-10-11 16:29:122420ブラウズ
この記事では、Python の前処理とヒート マップについて簡単に紹介します。一定の参考値があります。困っている友人は参照してください。お役に立てれば幸いです。
データ分析にはまだまだやるべきことがたくさんあります。ここではヒューリスティックな紹介をするだけです。この点を理解した後、使用する際に解決策をより早く見つけることができます。皆様のお役に立てば幸いです。
今回も sklearn で設定した虹彩データを使用し、ヒート マップで表示します。
前処理
sklearn.preprocessing は、機械学習ライブラリの前処理モジュールで、データの標準化、正規化などを行い、必要に応じて使用できます。ここでは、その標準化された方法を使用してデータを整理します。他の方法は自分で問い合わせることができます。
標準化: 特徴データの分布を標準正規分布 (ガウス分布とも呼ばれる) に調整します。これは、データの平均が 0、分散が 1 であることを意味します。
標準化の理由は、一部の特徴の分散が大きすぎると、その分散が目的関数を支配し、パラメーター推定器が他の特徴を正しく学習できなくなるためです。
標準化プロセスは、平均の分散化 (平均が 0 になる) と分散のスケーリング (分散が 1 になる) の 2 つのステップです。
上記の機能を実現するために、sklearn.preprocessing にはスケールメソッドが提供されています。
例を見てみましょう:
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
xx = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
xx_scale = preprocessing.scale(xx)
xx_scale各列のデータを正規化した後の結果は次のとおりです:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])内部のデータに変化があり、数値が変化していることがわかります。値は比較的小さいため、一目でわかる人もいるかもしれませんが、見えなくても問題ありません。Python では統計の一部を簡単に計算できます。
# 测试一下xx_scale每列的均值方差 print('均值:', xx_scale.mean(axis=0)) # axis=0指列,axis=1指行 print('方差:', xx_scale.std(axis=0))
上記では、標準化が何に変換されるかを紹介しましたが、結果は確かに一貫しています。列ごとに平均と分散を計算した結果は次のとおりです:
均值: [0. 0. 0.] 方差: [1. 1. 1.]
もちろん、標準化のためです。 , 分散と平均 これを一緒に行う必要はありません。たとえば、どちらかの方法だけを利用したい場合があります。
with_mean,with_std という方法もあります。これらは両方ともブール値パラメータであり、デフォルトではどちらも true ですが、false にカスタマイズすることもできます。つまり、平均中心化や分散スケーリングを 1 にしないでください。
heatmap
ヒートマップについては、すでにインターネット上に詳細な情報がたくさんあるので、ここでは簡単に説明します。
ヒート マップではデータがマトリックス状に存在し、属性範囲を色のグラデーションで表現しますが、ここでは pcolor を使用してヒート マップを描画します。
小 Lizi
それでもインポート ライブラリから開始して、データ セットをロードし、データを処理して、画像を描画し、画像に注釈や装飾を追加します。私はコードにコメントすることに慣れています。わからないことがあれば、メッセージを残していただければ、すぐに返信します。
# 导入后续所需要的库 from sklearn.datasets import load_iris from sklearn.preprocessing import scale import numpy as np import matplotlib.pyplot as plt # 加载数据集 data = load_iris() x = data['data'] y = data['target'] col_names = data['feature_names'] # 数据预处理 # 根据平均值对数据进行缩放 x = scale(x, with_std=False) x_ = x[1:26,] # 选取其中25组数据 y_labels = range(1, 26) # 绘制热图 plt.close('all') plt.figure(1) fig, ax = plt.subplots() ax.pcolor(x_, cmap=plt.cm.Greens, edgecolors='k') ax.set_xticks(np.arange(0, x_.shape[1])+0.5) # 设置横纵坐标 ax.set_yticks(np.arange(0, x_.shape[0])+0.5) ax.xaxis.tick_top() # x轴提示显示在图形上方 ax.yaxis.tick_left() # y轴提示显示在图形的左侧 ax.set_xticklabels(col_names, minor=False, fontsize=10) # 传递标签数据 ax.set_yticklabels(y_labels, minor=False, fontsize=10) plt.show()
それでは、描画されたイメージはどのようになりますか:
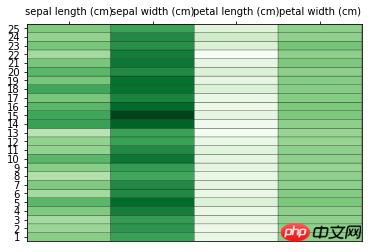
これらの簡単な手順に従ってください。データは直感的なものを描画します。もちろん、実際に使ってみるとそう簡単ではなく、さらに知識を深めていく必要があります。
以上がPython の前処理とヒートマップの簡単な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。