
ホームページ >Java >&#&チュートリアル >Java の JVM バイトコードの詳細な紹介
Java の JVM バイトコードの詳細な紹介

- 不言転載
- 2018-10-10 11:43:243620ブラウズ
この記事では、Java の JVM バイトコードについて詳しく説明します。必要な方は参考にしていただければ幸いです。
これは Java の基本 (JVM) に関する記事です。最初は Java クラスのロード メカニズムについて話したかったのですが、JVM の役割は、JVM によってコンパイルされたバイトコードをロードすることであると考えました。コンパイラを使用してそれをマシンに解釈する場合は、まずバイトコードを理解してから、バイトコードをロードするためのクラスロードメカニズムについて説明する方がよいと思われるため、この記事はバイトコードの詳細な説明に変更されます。
Java は純粋にオブジェクト指向であるため、バイトコードがクラスの情報を表現できる限り、JVM がクラスの情報をロードできる限り、Java プログラム全体を表現できます。 、プログラム全体をロードできます。したがって、バイトコードであっても、JVM ロードメカニズムであっても、焦点はクラスにあります。私の主な懸念事項は次のとおりです。
1. バイトコードは一度にメモリにロードされないため、JVM はロードしたいクラス情報が .class ファイル内のどこにあるかをどのように認識するのでしょうか。
2. バイトコードはクラス情報をどのように表現するのでしょうか?
3. バイトコードはプログラムを最適化しますか?
最初の質問は非常に単純です。ソース ファイルに多くのクラス (パブリック クラスが 1 つだけ) が含まれている場合でも、コンパイラはクラスごとに .class ファイルを生成し、JVM は必要に応じてそれをロードします。ロードされたクラス名をロードします。
次の問題を解決するために、まずバイトコードの構成を見てみましょう (Mac では Hex Fiend で開きます)。
このコード部分の場合:
package com.test.main1;
public class ByteCodeTest {
int num1 = 1;
int num2 = 2;
public int getAdd() {
return num1 + num2;
}
}
class Extend extends ByteCodeTest {
public int getSubstract() {
return num1 - num2;
}
}その中の Extend クラスを分析してみましょう。
Hex Fiend を使用して、コンパイルされた .class ファイルを次のように開きます (16 進コード):
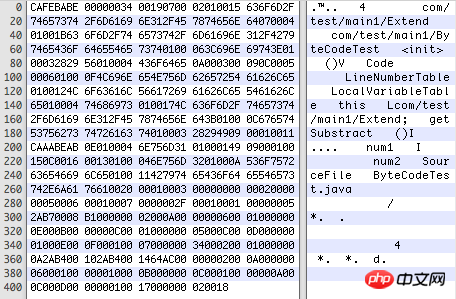
クラス ファイルには区切り文字がないため、それぞれの位置は What になります。を表し、各部分の長さとその他の形式は 厳密に規制されています 、以下の表を参照してください:
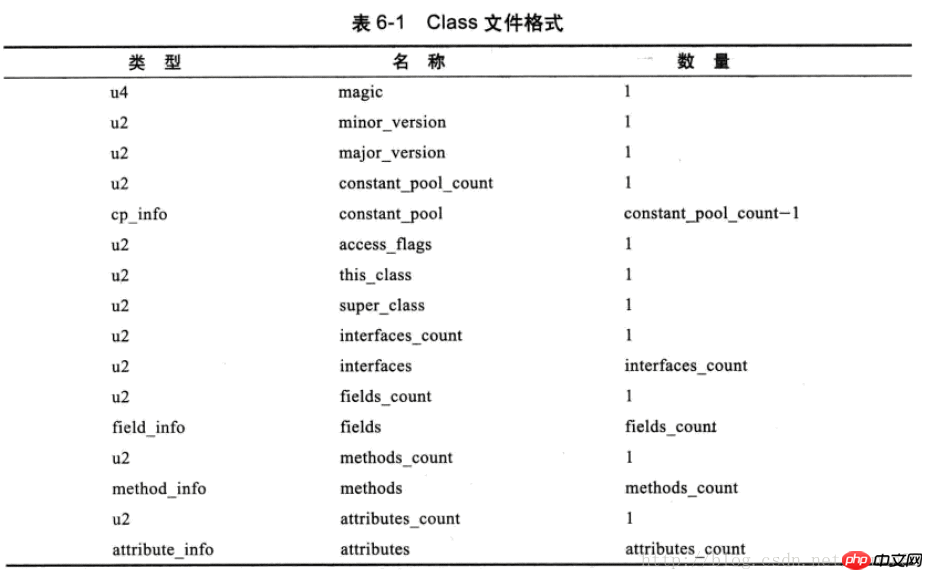
その中には u1、u2、u4、u8 を表します逆コンパイルされた 16 進数ファイルでは、2 つの数値が 1 バイト (u1) を表します。
最初から最後まで 1 つずつ見てください:
(1) マジック: u4 (マジックナンバー) は、このファイルが .class ファイルであることを意味します。 .jpg などにもこのマジックナンバーが付いているため、*.jpg を *.123 に変更しても通常どおり開くことができます。
(2) マイナー バージョン、メジャー バージョン: 各 u2、バージョン番号、下位互換性。つまり、上位バージョンの JDK は下位バージョンの .class ファイルを使用できますが、その逆はできません。
(3) constant_pool_count: u2、定数プール内の定数の数、0019 は 24 を表します。
(4) 次に特定の定数です。合計は constant_pool_count-1 です。
定数プールには、通常 2 種類のデータが保存されます。
リテラル: 文字列、最終的に変更された定数など。
シンボル参照: オブジェクトの完全名など。クラス/インターフェイス 修飾名、メソッド名と説明、フィールド名と説明など。
逆コンパイルされた数値に従って、まず以下の表を参照して、定数のタイプと長さを取得します。見つかった長さに等しい次の数値は、定数の特定の値を表します。
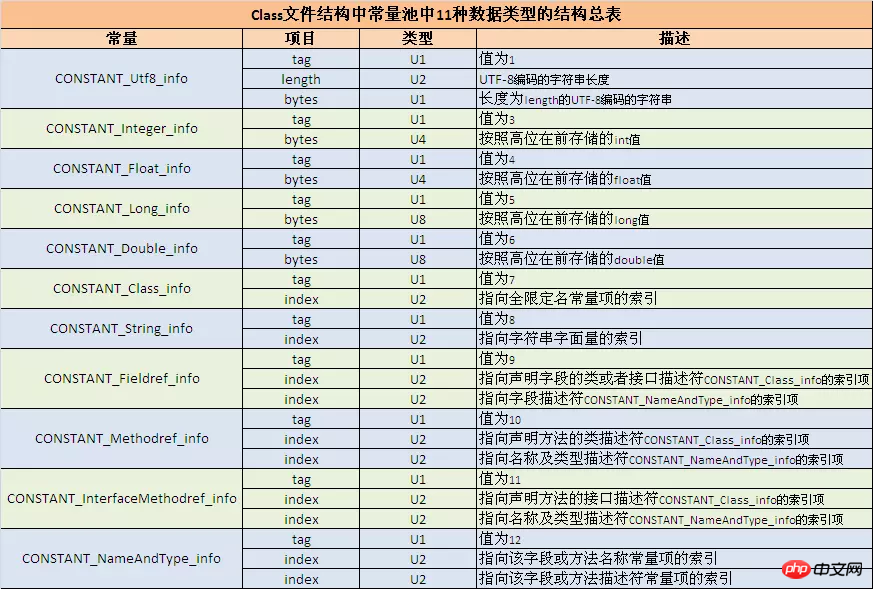
たとえば、070002 は、型が CONSTANT_Class_info、タグが u1、u2 の長さが完全修飾名の定数項目を指すインデックスであることを意味します。このインデックスは、javap -verbose で開かれたクラス ファイルと一緒に表示する必要があります。定数プール内の内容と順序は、ここに明確にリストされています。
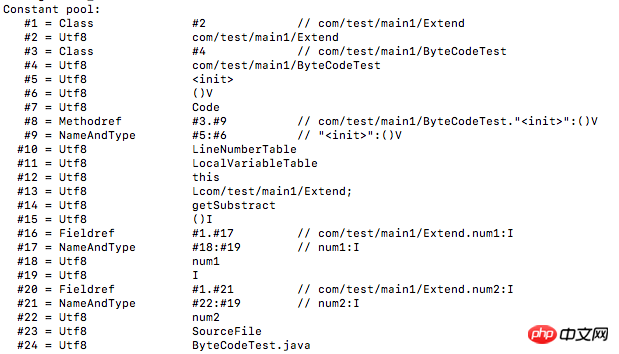
ここで 0002 を確認できます。インデックス項目の定数は com/test/main1/Extend で、これはクラスの完全修飾名です。値が文字列の場合は、値を 10 進数に変換し、ASCII コード テーブルをチェックして特定の文字を取得する必要があります。次の定数は次のように分析されます。
01001563 6F6D2F74 6573742F 6D61696E 312F4578 74656E64:com/test/main1/Extend
070004:com/test/main1/ByteCodeTest
01001B63 6F6D2F74 6573742F 6D61696E 312F4279 7465436F 64655465 7374:com/test/main1/ByteCodeTest
0100063C 696E6974 3E:7e51f00a783d7eb8f68358439dee7daf
01000328 2956:
01000443 6F6465 :コード
0A000300 09:com/test/main1/ByteCodeTest、"7e51f00a783d7eb8f68358439dee7daf":()V
0C000500 06:7e51f00a783d7eb8f68358439dee7daf、()V
01000F4C 696E654E 756D6265 72546162 6C65:行番号テーブル
0100124C 6F63616C 56617269 61626C65 5461626C 65:ローカル変数テーブル
01000474 6 86973:この
0100174C 636F6D2F 74657374 2F6D6169 6E312F45 7874656E 643B:Lcom/テスト/main1/Extend;
01000C67 65745375 62737472 616374:getSubstract
01000328 2949: ()I
09000100 11:com/test/main1/Extend、num1:I
0C001200 13: num1、I
0100046E 756D31: num1
01000149: I
09000100 15: com/test/main1/Extend、num2:I
0C001600 13: num2、I
0100046E 756D32: num2
01000A53 6F757263 6546696C 65: ソースファイル
01001142 79746543 6F646554 6573742E 6A617661: ByteCodeTest.java
この時点で、定数プール内のすべての定数が解析されました。
(5) 次に、u2 の access_flags です。 access_flags アクセス フラグの主な目的は、クラスがクラスであるかインターフェイスであるか、クラスの場合はアクセス許可がパブリックであるかどうかをマークすることです。抽象的であるかどうか、最終としてマークされているかどうかなどについては、以下の表を参照してください:
| #フラグ名 | ##値 | 解釈 | #ACC_PUBLIC
| ##0x0001 | # アクセス権限がパブリックであり、このパッケージの外部からアクセスできることを示しますACC_FINAL | |
| は、final によって変更され、サブクラスが許可されていないことを意味します | ACC_SUPER | |
| は特別で、直接の親クラスへの動的バインディングを示します。以下の説明を参照してください。 | ##ACC_INTERFACE。 | |
| はクラスではなくインターフェースを表します | ACC_ABSTRACT | |
| は抽象クラスを表すため、インスタンス化できません | #ACC_SYNTHETIC | 0x1000 |
| は、合成によって変更され、ソース コードには表示されないことを意味します。付録 [2] を参照してください。 | ACC_ANNOTATION##0x2000 | |
| は注釈のタイプを示します | ACC_ENUM | 0x4000 |
| は列挙型を表します | 所以,本类中的access_flags是0020,表示这个Extend类调用父类的方法时,并非是编译时绑定,而是在运行时搜索类层次,找到最近的父类进行调用。这样可以保证调用的结果是一定是调用最近的父类,而不是编译时绑定的父类,保证结果的正确性。 (6)this_class:u2的类索引,用于确定类的全限定名。本类的this_class是0001,表示在常量池中#1索引,是com/test/main1/Extend (7)super_class:u2的父类索引,用于确定直接父类的全限定名。本类是0003,#3是com/test/main1/ByteCodeTest (8)interfaces_count:u2,表示当前类实现的接口数量,注意是直接实现的接口数量。本类中是0000,表示没有实现接口。 (9)Interfaces:表示接口的全限定名索引。每个接口u2,共interfaces_count个。本类为空。 (10)fields_count:u2,表示类变量和实例变量总的个数。本类中是0000,无。 (11)fields:fileds的长度为filed_info,filed_info是一个复合结构,组成如下: filed_info: {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}由于本类无类变量和实例变量,故本字段为空。 (12)methods_count:u2,表示方法个数。本类中是0002,表示有2个。 (13)methods:methods的长度为一个method_info结构: method_info {
u2 access_flags; 0000 ?
u2 name_index; 0005 <init>
u2 descriptor_index; 0006 ()V
u2 attributes_count; 0001 1个
attribute_info attributes[attributes_count]; 0007 Code
}其中attribute_info结构如下: attribute_info {
u2 attribute_name_index; 0007 Code
u1 attribute_length;
u1 info[attribute_length];
}上面是通用的attribute_info的定义,另外,JVM里预定义了几种attribute,Code即是其中一种(注意,如果使用的是JVM预定义的attribute,则attribute_info的结构就按照预定义的来),其结构如下: Code_attribute { //Code_attribute包含某个方法、实例初始化方法、类或接口初始化方法的Java虚拟机指令及相关辅助信息
u2 attribute_name_index; 0007 Code
u4 attribute_length; 0000002F 47
u2 max_stack; 0001 1 //用来给出当前方法的操作数栈在方法执行的任何时间点的最大深度
u2 max_locals; 0001 1 //用来给出分配在当前方法引用的局部变量表中的局部变量个数
u4 code_length; 00000005 5 //给出当前方法code[]数组的字节数
u1 code[code_length]; 2AB70008 B1 42、183、0、8、177
//给出了实现当前方法的Java虚拟机代码的实际字节内容 (这些数字代码实际对应一些Java虚拟机的指令)
u2 exception_table_lentgh; 0000 0 //异常的信息
{
u2 start_pc; //这两项的值表明了异常处理器在code[]中的有效范围,即异常处理器x应满足:start_pc≤x≤end_pc
u2 end_pc; //start_pc必须在code[]中取值,end_pc要么在code[]中取值,要么等于code_length的值
u2 handler_pc; //表示一个异常处理器的起点
u2 catch_type; //表示当前异常处理器需要捕捉的异常类型。为0,则都调用该异常处理器,可用来实现finally。
} exception_table[exception_table_lentgh]; 在本类中大括号里的结构为空
u2 attribute_count; 0002 2 表示该方法的其它附加属性,本类有1个
attribute_info attributes[attributes_count]; 000A、000B LineNumberTable、LocalVariableTable
}LineNumberTable和LocalVariableTable又是两个预定义的attribute,其结构如下: LineNumberTable_attribute { //被调试器用来确定源文件中由给定的行号所表示的内容,对应于Java虚拟机code[]数组的哪部分
u2 attribute_name_index; 000A
u4 attribute_length; 00000006
u2 line_number_table_length; 0001
{ u2 start_pc; 0000
u2 line_number; 000E //该值必须与源文件中对应的行号相匹配
} line_number_table[line_number_table_length];
}以及: LocalVariableTable_attribute {
u2 attribute_name_index; 000B
u4 attribute_length; 0000000C
u2 local_variable_table_length; 0001
{ u2 start_pc; 0000
u2 length; 0005
u2 name_index; 000C
u2 descriptor_index; 000D //用来表示源程序中局部变量类型的字段描述符
u2 index; 0000
} local_variable_table[local_variable_table_length];然后就是第二个方法,具体略过。 (14)attributes_count:u2,这里的attribute表示整个class文件的附加属性,和前面方法的attribute结构相同。本类中为0001。 (15)attributes:class文件附加属性,本类中为0017,指向常量池#17,为SourceFile,SourceFile的结构如下: SourceFile_attribute {
u2 attribute_name_index; 0017 SourceFile
u4 attribute_length; 00000002 2
u2 sourcefile_index; 0018 ByteCodeTest.java //表示本class文件是由ByteCodeTest.java编译来的
}嗯,字节码的内容大概就写这么多。可以看到通篇文章基本都是在分析字节码文件的16进制代码,所以可以这么说,字节码的核心在于其16进制代码,利用规范中的规则去解析这些代码,可以得出关于这个类的全部信息,包括: 1. 这个类的版本号; 2. 这个类的常量池大小,以及常量池中的常量; 3. 这个类的访问权限; 4. 这个类的全限定名、直接父类全限定名、类的直接实现的接口信息; 5. 这个类的类变量和实例变量的信息; 6. 这个类的方法信息; 7. 其它的这个类的附加信息,如来自哪个源文件等。 解析完字节码,回头再来看开始提出的问题,也就迎刃而解了。由于字节码文件格式严格按照规定,可以用来表示类的全部信息;字节码只是用来表示类信息的,不会进行程序的优化。 那么在编译期间,编译器会对程序进行优化吗?运行期间JVM会吗?什么时候进行的,按照什么原则呢?这个留作以后再表。 最后,值得注意的是,字节码不仅是平台无关的(任何平台生成的字节码都可以在任何的JRE环境运行),还是语言无关的,不仅Java可以生成字节码,其它语言如Groovy、Jython、Scala等也能生成字节码,运行在JRE环境中。 |
以上がJava の JVM バイトコードの詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。