
ホームページ >Java >&#&チュートリアル >Java での高い同時実行性を解決するにはどうすればよいですか? Java の高同時実行ソリューション
Java での高い同時実行性を解決するにはどうすればよいですか? Java の高同時実行ソリューション

- 不言転載
- 2018-10-10 11:16:573094ブラウズ
この記事の内容は、Java での高い同時実行性を解決する方法についてです。 Java の高同時実行ソリューションには、一定の参考価値があります。必要な方は参考にしていただければ幸いです。
私たちが開発する Web サイトの場合、Web サイトへのアクセス数が非常に多い場合は、関連する同時アクセスの問題を考慮する必要があります。同時実行性の問題は、ほとんどのプログラマーにとって頭の痛い問題です。
しかし、この問題から逃れることはできないので、冷静に対処しましょう~今日は、一般的な問題である同時実行性と同期について勉強しましょう。
同時実行性と同期についてより深く理解するには、まず 2 つの重要な概念を理解する必要があります。 同期と非同期
1 同期と非同期の違い。
#いわゆる同期は、関数またはメソッドの実行後にシステムが値またはメッセージを返すのを待つこととして理解できます。このとき、プログラムはブロックされ、受信のみを行います##。#他のコマンドは値またはメッセージを返した後でのみ実行してください。
非同期では、関数またはメソッドを実行した後、戻り値またはメッセージをブロックして待つ必要はありません。システムが戻り値またはメッセージを受け取ったときにのみ、非同期プロセスを委任する必要があります。というメッセージが表示されると、システムは自動的に非同期プロセスをトリガーして、完全なプロセスを完了します。
同期は、ある程度まで単一のスレッドとみなすことができます。このスレッドはメソッドを要求した後、メソッドが応答するまで待機し、応答しない場合は実行を続行しません。
非同期は、ある程度マルチスレッドであるとみなすことができます (ナンセンスです。メソッドを要求した後、スレッドは無視され、他のメソッドの実行が継続されます)。
同期は 1 つの作業であり、一度に 1 つの作業を実行します。
非同期とは、他の処理を行わずに 1 つの処理を実行することを意味します。
例:
口は 1 つしかないため、食べたり話したりできるのは一度に 1 つだけです。しかし、音楽を聴くことで食事ができるわけではないため、食べることと音楽を聴くことは非同期です。
Java プログラマーにとって、同期監視オブジェクトがクラスの場合、オブジェクトがクラス内の同期メソッドにアクセスする場合、他のオブジェクトにアクセスし続ける場合は、同期キーワード synchronized をよく耳にします。クラス内の同期メソッドがブロック状態になるのは、前のオブジェクトが同期メソッドの実行を終了した後でのみ、現在のオブジェクトはメソッドの実行を続行できます。これが同期です。逆に、メソッドの前に同期キーワードの変更がない場合、異なるオブジェクトが同時に同じメソッドにアクセスでき、これは非同期になります。
追加 (ダーティ データと非反復読み取りの関連概念):
ダーティ データ
ダーティ読み取りとは、トランザクションがデータにアクセスしており、データがこの時点では、変更はまだデータベースにコミットされていません。別のトランザクションもデータにアクセスし、そのデータを使用します。このデータはまだコミットされていないため、別のトランザクションによって読み取られたデータはダーティ データであり、ダーティ データに基づく操作は正しく行われない可能性があります。
非反復読み取り
非反復読み取りとは、トランザクション内で同じデータを複数回読み取ることを指します。このトランザクションが終了する前に、別のトランザクションも同じデータにアクセスします。その後、最初のトランザクションの 2 回のデータ読み取りの間で、2 番目のトランザクションの変更により、最初のトランザクションで 2 回読み取られたデータが異なる可能性があります。このように、1 つのトランザクションで 2 回読み取られるデータは異なるため、Non-repeatable readと呼ばれます。2. 同時実行性と同期に対処する方法
今日の話 How to同時実行性と同期の問題は主にロック メカニズムを通じて処理されます。
ロック機構には 2 つのレベルがあることを理解する必要があります。
1 つは、Java の同期ロックなどのコード レベルです。
もう 1 つは、ここではあまり説明しません。上記のより典型的なものは、悲観的ロックと楽観的ロックです。ここで注目するのは、悲観的ロック (従来の物理的ロック) と楽観的ロックです。
悲観的ロック:
悲観的ロックは、その名前が示すように、外部 (このシステムの他の現在のトランザクションや外部システムからのトランザクションを含む) によってブロックされているデータの処理を指します。 ) 変更のため、データはデータ処理プロセス全体を通じてロックされます。
悲観的ロックの実装は、多くの場合、データベースによって提供されるロック メカニズムに依存します (データ アクセスの排他性を真に保証できるのは、データベース層によって提供されるロック メカニズムだけです。それ以外の場合は、ロック メカニズムがこのシステムでは、外部システムがデータを変更しないことを保証できません)。
データベースに依存する典型的な悲観的ロック呼び出し:
select * from account where name=”Erica” for update
この SQL ステートメントは、アカウント テーブル内の取得条件 (name="Erica") を満たすすべてのレコードをロックします。
本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。
Hibernate 的悲观锁,也是基于数据库的锁机制实现。
下面的代码实现了对查询记录的加锁:
String hqlStr ="from TUser as user where user.name='Erica'";
Query query = session.createQuery(hqlStr);
query.setLockMode("user",LockMode.UPGRADE); // 加锁
List userList = query.list();// 执行查询,获取数据query.setLockMode 对查询语句中,特定别名所对应的记录进行加锁(我们为 TUser 类指定了一个别名 “user” ),这里也就是对返回的所有 user 记录进行加锁。
观察运行期 Hibernate 生成的 SQL 语句:
select tuser0_.id as id, tuser0_.name as name, tuser0_.group_id as group_id, tuser0_.user_type as user_type, tuser0_.sex as sex from t_user tuser0_ where (tuser0_.name='Erica' ) for update
这里 Hibernate 通过使用数据库的 for update 子句实现了悲观锁机制。
Hibernate 的加锁模式有:
? LockMode.NONE : 无锁机制。
? LockMode.WRITE : Hibernate 在 Insert 和 Update 记录的时候会自动获取
? LockMode.READ : Hibernate 在读取记录的时候会自动获取。
以上这三种锁机制一般由 Hibernate 内部使用,如 Hibernate 为了保证 Update
过程中对象不会被外界修改,会在 save 方法实现中自动为目标对象加上 WRITE 锁。
? LockMode.UPGRADE :利用数据库的 for update 子句加锁。
? LockMode. UPGRADE_NOWAIT : Oracle 的特定实现,利用 Oracle 的 for
update nowait 子句实现加锁。
上面这两种锁机制是我们在应用层较为常用的,加锁一般通过以下方法实现:
Criteria.setLockMode
Query.setLockMode
Session.lock
注意,只有在查询开始之前(也就是 Hiberate 生成 SQL 之前)设定加锁,才会 真正通过数据库的锁机制进行加锁处理,否则,数据已经通过不包含 for update子句的 Select SQL 加载进来,所谓数据库加锁也就无从谈起。
为了更好的理解select... for update的锁表的过程,本人将要以mysql为例,进行相应的讲解
1、要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。
表的基本结构如下:
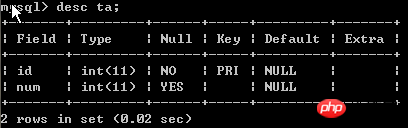
表中内容如下:
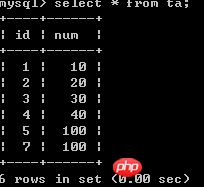
开启两个测试窗口,在其中一个窗口执行select * from ta for update0
然后在另外一个窗口执行update操作如下图:

等到一个窗口commit后的图片如下:

到这里,悲观锁机制你应该了解一些了吧~
需要注意的是for update要放到mysql的事务中,即begin和commit中,否者不起作用。
至于是锁住整个表还是锁住选中的行。
至于hibernate中的悲观锁使用起来比较简单,这里就不写demo了~感兴趣的自己查一下就ok了~
乐观锁(Optimistic Locking):
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依 靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库 性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。 如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进 行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过 程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作 员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几 百上千个并发,这样的情况将导致怎样的后果。 乐观锁机制在一定程度上解决了这个问题。
乐观锁,大多是基于数据版本 Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来 实现。 读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提 交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据 版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 2 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( version=1 ),并 从其帐户余额中扣除 $20 ( $100-$20 )。 3 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣 除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大 于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。 4 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数 据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的 数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记 录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。 这样,就避免了操作员 B 用基于version=1 的旧数据修改的结果覆盖操作 员 A 的操作结果的可能。 从上面的例子可以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系 统整体性能表现。 需要注意的是,乐观锁机制往往基于系统中的数据存储逻辑,因此也具备一定的局 限性,如在上例中,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户 余额更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。在 系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整(如 将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途 径,而不是将数据库表直接对外公开)。 Hibernate 在其数据访问引擎中内置了乐观锁实现。如果不用考虑外部系统对数 据库的更新操作,利用 Hibernate 提供的透明化乐观锁实现,将大大提升我们的 生产力。
User.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.xiaohao.test">
<class name="User" table="user" optimistic-lock="version" >
<id name="id">
<generator class="native" />
</id>
<!--version标签必须跟在id标签后面-->
<version column="version" name="version" />
<property name="userName"/>
<property name="password"/>
</class>
</hibernate-mapping>注意 version 节点必须出现在 ID 节点之后。
这里我们声明了一个 version 属性,用于存放用户的版本信息,保存在 User 表的version中
optimistic-lock 属性有如下可选取值:
? none无乐观锁
? version通过版本机制实现乐观锁
? dirty通过检查发生变动过的属性实现乐观锁
? all通过检查所有属性实现乐观锁
其中通过 version 实现的乐观锁机制是 Hibernate 官方推荐的乐观锁实现,同时也 是 Hibernate 中,目前唯一在数据对象脱离 Session 发生修改的情况下依然有效的锁机 制。因此,一般情况下,我们都选择 version 方式作为 Hibernate 乐观锁实现机制。
2 、配置文件hibernate.cfg.xml和UserTest测试类
hibernate.cfg.xml
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 指定数据库方言 如果使用jbpm的话,数据库方言只能是InnoDB-->
<property name="dialect">org.hibernate.dialect.MySQL5InnoDBDialect</property>
<!-- 根据需要自动创建数据表 -->
<property name="hbm2ddl.auto">update</property>
<!-- 显示Hibernate持久化操作所生成的SQL -->
<property name="show_sql">true</property>
<!-- 将SQL脚本进行格式化后再输出 -->
<property name="format_sql">false</property>
<property name="current_session_context_class">thread</property>
<!-- 导入映射配置 -->
<property name="connection.url">jdbc:mysql:///user</property>
<property name="connection.username">root</property>
<property name="connection.password">123456</property>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<mapping resource="com/xiaohao/test/User.hbm.xml" />
</session-factory>
</hibernate-configuration>UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.getCurrentSession();
Transaction tx=session.beginTransaction();
// User user=new User("小浩","英雄");
// session.save(user);
// session.createSQLQuery("insert into user(userName,password) value('张英雄16','123')")
// .executeUpdate();
User user=(User) session.get(User.class, 1);
user.setUserName("221");
// session.save(user);
System.out.println("恭喜您,用户的数据插入成功了哦~~");
tx.commit();
}
}每次对 TUser 进行更新的时候,我们可以发现,数据库中的 version 都在递增。
下面我们将要通过乐观锁来实现一下并发和同步的测试用例:
这里需要使用两个测试类,分别运行在不同的虚拟机上面,以此来模拟多个用户同时操作一张表,同时其中一个测试类需要模拟长事务
UserTest.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest {
public static void main(String[] args) {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("101");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}UserTest2.java
package com.xiaohao.test;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
public class UserTest2 {
public static void main(String[] args) throws InterruptedException {
Configuration conf=new Configuration().configure();
SessionFactory sf=conf.buildSessionFactory();
Session session=sf.openSession();
// Session session2=sf.openSession();
User user=(User) session.createQuery(" from User user where user=5").uniqueResult();
Thread.sleep(10000);
// User user2=(User) session.createQuery(" from User user where user=5").uniqueResult();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
Transaction tx=session.beginTransaction();
user.setUserName("100");
tx.commit();
System.out.println(user.getVersion());
// System.out.println(user2.getVersion());
// System.out.println(user.getVersion()==user2.getVersion());
// Transaction tx2=session2.beginTransaction();
// user2.setUserName("4468");
// tx2.commit();
}
}操作流程及简单讲解: 首先启动UserTest2.java测试类,在执行到Thread.sleep(10000);这条语句的时候,当前线程会进入睡眠状态。在10秒钟之内启动UserTest这个类,在到达10秒的时候,我们将会在UserTest.java中抛出下面的异常:
Exception in thread "main" org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [com.xiaohao.test.User#5]
at org.hibernate.persister.entity.AbstractEntityPersister.check(AbstractEntityPersister.java:1932)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2576)
at org.hibernate.persister.entity.AbstractEntityPersister.updateOrInsert(AbstractEntityPersister.java:2476)
at org.hibernate.persister.entity.AbstractEntityPersister.update(AbstractEntityPersister.java:2803)
at org.hibernate.action.EntityUpdateAction.execute(EntityUpdateAction.java:113)
at org.hibernate.engine.ActionQueue.execute(ActionQueue.java:273)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:265)
at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:185)
at org.hibernate.event.def.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:321)
at org.hibernate.event.def.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:51)
at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216)
at org.hibernate.impl.SessionImpl.managedFlush(SessionImpl.java:383)
at org.hibernate.transaction.JDBCTransaction.commit(JDBCTransaction.java:133)
at com.xiaohao.test.UserTest2.main(UserTest2.java:21)UserTest2代码将在 tx.commit() 处抛出 StaleObjectStateException 异 常,并指出版本检查失败,当前事务正在试图提交一个过期数据。通过捕捉这个异常,我 们就可以在乐观锁校验失败时进行相应处理
3. 一般的な同時同期ケースの分析
ケース 1: 予約システムのケース。10,000 人がチケットを予約するために Web サイトを開いたと仮定すると、特定のフライトにはチケットが 1 枚しかありません。 、同時実行の問題をどのように解決しますか (同時実行性の高い Web サイトで考慮する必要がある同時読み取りおよび書き込みの問題に拡張できます)
問題、チケットが期限切れになる前に 10,000 人が訪問しますチケットを発行するには、全員がチケットがあることを確認できるようにする必要があります。1 人がチケットを見たときに、他の人がそれを見ることは不可能です。誰がそれを獲得できるかは、その人の「運」 (ネットワーク速度など) によって異なります。2 番目に考慮すべき点は、10,000 人が同時に購入をクリックした場合、誰が取引できるかということです。チケットは合計で 1 枚のみです。
まず第一に、同時実行性に関連するいくつかの解決策を簡単に考えることができます。
ロック同期 同期とは、よりアプリケーション レベルを指しますが、1 つずつしかアクセスできません。 Java 中指は syncrinized キーワードを指します。ロックにも 2 つのレベルがあり、1 つは Java で言及されるオブジェクト ロックで、スレッドの同期に使用されます。もう 1 つはデータベース ロックで、分散システムの場合は明らかにデータベースのロックを使用することによってのみ実現できます。側。
同期メカニズムまたはデータベースの物理ロック メカニズムを使用すると仮定すると、10,000 人が同時にチケットを参照できるようにする方法は明らかにパフォーマンスを犠牲にすることになりますが、これは同時実行性の高い Web サイトでは推奨できません。 Hibernate を使用した後、楽観的ロックと悲観的ロック (つまり、従来の物理ロック) という別の概念を思いつきました。楽観的ロックを使用すると、この問題を解決できます。オプティミスティック ロックとは、ビジネス コントロールを使用してテーブルをロックせずに同時実行の問題を解決することを意味します。これにより、同時実行によって発生するダーティ データの問題を解決しながら、データの同時読み取り可能性と保存されたデータの排他性が保証されます。
休止状態でオプティミスティックロックを実装する方法:
前提: 既存のテーブル、バージョンバージョン番号、long 型に冗長フィールドを追加します
原則:
1) 現在のバージョン番号 = データベース テーブルのバージョン番号のみを送信できます
2) 送信が成功すると、バージョン番号 version
実装は非常に簡単です。属性 optimistic-lock を追加します。 ormapping ="version" だけで十分です。 以下はサンプル スニペットです。
fcbe3e9142a5aba58f59285a7d211ac7
6d72d6da462390accae85f9a412bc92f
ケース 2、株式取引システム、銀行システム、大規模なデータの量をどのように考慮しますか?
まず、株式取引システムの相場状況 表では、相場レコードは数秒ごとに生成され、1日に1件(3秒に1相場と仮定)の銘柄数×20×60レコードとなります。 1 か月でこのテーブルには多くのレコードが含まれるでしょうか? Oracle のテーブル内のレコード数が 100 万を超えると、クエリのパフォーマンスが非常に低下します。システムのパフォーマンスを確保するにはどうすればよいですか?
別の例として、チャイナ モバイルには数億人のユーザーがいます。テーブルはどのように設計するのでしょうか?すべてを 1 つのテーブルにまとめますか?したがって、多数のシステムでは、テーブルの分割を考慮する必要があります (テーブル名は異なりますが、構造はまったく同じです)。 (状況に応じて) いくつかの一般的な方法があります。 ) 携帯電話番号のテーブルの場合、130 で始まるテーブルを 1 つのテーブル、131 で始まるテーブルを 1 つのテーブルとして考えるなど、業務ごとに分割します。
2) Oracle のテーブル分割メカニズムを使用します。別のテーブルを作成するには
3 ) トレーディング システムの場合は、タイムラインに従って分割し、当日のデータを 1 つのテーブルに、履歴データを別のテーブルに置くことを検討できます。ここでの履歴データのレポートやクエリは、その日の取引には影響しません。
もちろん、テーブルを分割した後は、アプリケーションをそれに応じて調整する必要があります。単純な or マッピングを変更する必要がある場合があります。たとえば、一部の企業ではストアド プロシージャなどを実行する必要があります。
さらに、キャッシュについても考慮する必要があります
ここでいうキャッシュとは休止状態だけを指すのではなく、休止状態自体が第 1 レベルの機能を提供します。そして二次キャッシュ。ここでのキャッシュはアプリケーションから独立しており、データベースへの頻繁なアクセスを減らすことができれば、システムにとって大きなメリットとなることは間違いありません。たとえば、電子商取引システムの商品検索で、特定のキーワードを含む商品が頻繁に検索される場合、商品リストのこの部分をキャッシュ (メモリ内) に保存して、アクセスする必要がないようにすることを検討できます。毎回データベースを更新するので、パフォーマンスが大幅に向上します。
単純なキャッシュは、自分でハッシュマップを作成し、頻繁にアクセスされるデータのキーを作成すると理解できます。値は、データベースから初めて検索され、次回マップから読み取ることができます。データベースを読み取る代わりに、現在、より専門的なものには、キャッシュ サーバーとして独立してデプロイできる memcached などの独立したキャッシュ フレームワークがあります。
4. 高同時アクセスの効率を向上させる一般的な方法
まず、高同時アクセスのボトルネックがどこにあるのかを理解する必要があります。
1. サーバーのネットワーク帯域幅が不足している可能性があります。
2. 十分な Web スレッド接続がない可能性があります。
3. データベース接続クエリにアクセスできない可能性があります。
状況に応じて、解決策のアイデアも異なります。
最初のケースと同様に、ネットワーク帯域幅を増やすことができ、DNS ドメイン名解決を複数のサーバーに分散できます。
ロード バランシング、フロント プロキシ サーバー nginx、Apache など。
データベース クエリの最適化、読み取りと書き込みの分離、テーブルのパーティショニングなど。
最後に必要なものをいくつかコピーします。高い同時実行性の下で頻繁に処理する必要があるコンテンツ:
ユーザー キャッシュ、情報キャッシュなどのキャッシュを使用してみてください。キャッシュに多くのメモリを費やすと、データベースとの対話が大幅に削減され、パフォーマンスが向上します。
jprofiler などのツールを使用してパフォーマンスのボトルネックを見つけ、追加のオーバーヘッドを削減します。
データベース クエリ ステートメントを最適化し、休止状態やその他のツールを使用して直接生成されるステートメントの数を減らします (長期クエリのみが最適化されます)。
データベース構造を最適化し、より多くのインデックスを作成し、クエリ効率を向上させます。
統計関数は可能な限りキャッシュする必要があります。あるいは、統計が必要なときに統計を取得しないように、統計を 1 日に 1 回または定期的に収集する必要があります。
コンテナの解析を減らすために、可能な限り静的ページを使用してください (表示用に動的コンテンツの静的 HTML を生成するようにしてください)。
上記の問題を解決した後、サーバー クラスターを使用して、単一サーバーのボトルネックの問題を解決します。
Java の高い同時実行性、その解決方法、解決方法
以前は、高い同時実行性の解決策はスレッドまたはキューによって解決できると誤解していました。同時実行性が高いため、多くのユーザーがアクセスする場合があり、その結果、不正なシステムデータやデータ損失が発生するため、 この問題を解決するためにキューが使用されます。たとえば、商品の入札、Weibo でのコメントの転送、または商品のフラッシュ販売の場合、同時にアクセス数が特に多くなります。キューはここで特別な役割を果たします。 すべてのリクエストはキューに入れられ、ミリ秒単位で整然と処理されるため、データ損失や不正なシステム データが発生することはありません。
今日情報を確認したところ、同時実行性を高めるには 2 つの解決策があることがわかりました。
1 つはキャッシュを使用することで、もう 1 つは静的ページから開始することです。最も基本的な場所 リソースの不必要な浪費を減らすために作成するコードを最適化します: (
1. 新しいオブジェクトを頻繁に使用しないでください。アプリケーション全体で 1 つのインスタンスのみが必要なクラスにはシングルトン モードを使用してください。文字列接続操作の場合)ユーティリティ型クラスの場合は、静的メソッド
2 を介してアクセスします。 間違ったメソッドの使用を避けてください。たとえば、Exception はメソッドの起動を制御できますが、パフォーマンスを消費するために Exception はスタックトレースを保持する必要があります。必要な場合以外は使用しないでください。 たとえば、instanceof で条件判定を行う場合は、Vector よりも性能の良い ArrayList などの JAVA の効率的なクラスを使用してください。 )
まず第一に、私はキャッシュ技術を使用したことがありません。ユーザーがリクエストしたときにデータをキャッシュに保存して、複数のリクエストを防ぐためにキャッシュにデータがあるかどうかを検出する必要があると思います。これは私の個人的な理解ですが、静的ページを生成する方法は使用しないでください。ページがリクエストされると、ほとんどの Web サイトが変更されます。このページは、実際には HTM に変換された後のサーバー リクエスト アドレスです。静的ページにはサーバー コンポーネントがないため、アクセス速度が向上します。ここで詳しく紹介します:
1. ページの静的化とは:
簡単に言えば、リンクにアクセスすると サーバーの対応するモジュールがこのリクエストを処理し、対応する JSP インターフェイスに移動し、最後に確認したいデータを生成します。この欠点は明らかです。サーバーへのすべてのリクエストが処理されるためです。 同時リクエストが多すぎると、アプリケーション サーバーへの負荷が増大し、サーバーがダウンする可能性もあります。では、それを避けるにはどうすればよいでしょうか? test.do のペアを置くと リクエスト後の結果がhtmlファイルに保存され、ユーザーが毎回アクセスすることでアプリケーションサーバーへの負荷が軽減されるのではないでしょうか?
では、静的ページはどこから来たのでしょうか?各ページを手動で処理させることはできませんよね?これには、これから説明する静的ページ生成ソリューションが含まれます。必要なのは、ユーザーがアクセスすると、静的ページを自動的に生成し、ユーザーに表示することです。
2. ページの静的スキームをマスターする場合にマスターする必要がある知識ポイントを簡単に紹介します。
1. 基本 - URL リライト
URL リライトとは? ? URL の書き換え。簡単な例を使用して問題を説明しましょう。URL を入力しますが、実際には abc.com/test.action にアクセスすると、URL が書き換えられたと言えます。このテクノロジーは広く使用されており、この機能を実現できるオープンソース ツールが多数あります。
2. 基本 - サーブレット web.xml
web.xml でリクエストとサーブレットがどのように一致するかがまだわからない場合は、サーブレットのドキュメントを検索してください。これはナンセンスではありません。多くの人は、マッチング方法 /xyz/*.do が効果的であると考えています。
それでもサーブレットの書き方がわからない場合は、サーブレットの書き方を検索してください。これは冗談ではありません。さまざまな統合ツールが飛び交っているため、多くの人は最初からサーブレットを作成することはありません。 .サーブレット。
3. 基本的なソリューションの紹介

このうち、URL リライター部分については、有料またはオープンソースのツールを使用して、 URL が特に複雑でない場合は、サーブレットに実装することを検討できます。その場合、次のようになります。

总 结:其实我们在开发中都很少考虑这种问题,直接都是先将功能实现,当一个程序员在干到1到2年,就会感觉光实现功能不是最主要的,安全性能、质量等等才是 一个开发人员最该关心的。今天我所说的是高并发。
我的解决思路是:
1、采用分布式应用设计
2、分布式缓存数据库
3、代码优化
Java高并发的例子:
具体情况是这样: 通过java和数据库,自己实现序列自动增长。
实现代码大致如下:
id_table表结构, 主要字段:
id_name varchar2(16); id_val number(16,0); id_prefix varchar2(4);
//操作DB
public synchronized String nextStringValue(String id){
SqlSession sqlSess = SqlSessionUtil.getSqlSession();
sqlSess.update("update id_table set id_val = id_val + 1 where id_name="+id);
Map map = sqlSess.getOne("select id_name, id_prefix, id_val from id_table where id_name="+ id);
BigDecimal val = (BigDecimal) map.get("id_val");
//id_val是具体数字,rePack主要是统一返回固定长度的字符串;如:Y0000001, F0000001, T0000001等
String idValue = rePack(val, map);
return idValue;
}
//公共方法
public class IdHelpTool{
public static String getNextStringValue(String idName){
return getXX().nextStringValue(idName);
}
}具体使用者,都是通过类似这种方式:IdHelpTool.getNextStringValue("PAY_LOG");来调用。
问题:
(1) 当出现并发时, 有时会获取重复的ID;
(2) 由于服务器做了相关一些设置,有时调用这个方法,好像还会导致超时。
为了解决问题(1), 考虑过在方法getNextStringValue上,也加上synchronized , 同步关键字过多,会不会更导致超时?
跪求大侠提供个解决问题的大概思路!!!
解决思路一:
1、推荐 https://github.com/adyliu/idcenter
2、可以通过第三方redis来实现。
解决思路一:
1、出现重复ID,是因为脏读了,并发的时候不加 synchronized 比如会出现问题
2、但是加了 synchronized ,性能急剧下降了,本身 java 就是多线程的,你把它单线程使用,不是明智的选择,同时,如果分布式部署的时候,加了 synchronized 也无法控制并发
3、调用这个方法,出现超时的情况,说明你的并发已经超过了数据库所能处理的极限,数据库无限等待导致超时
基于上面的分析,建议采用线程池的方案,支付宝的单号就是用的线程池的方案进行的。
数据库 update 不是一次加1,而是一次加几百甚至上千,然后取到的这 1000个序号,放在线程池里慢慢分配即可,能应付任意大的并发,同时保证数据库没任何压力。
以上がJava での高い同時実行性を解決するにはどうすればよいですか? Java の高同時実行ソリューションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。