
ホームページ >データベース >mysql チュートリアル >[MySQL データベース] 第 4 章の解釈: スキーマとデータ型の最適化 (パート 1)
[MySQL データベース] 第 4 章の解釈: スキーマとデータ型の最適化 (パート 1)
- php是最好的语言オリジナル
- 2018-08-07 13:53:421833ブラウズ
まえがき:
高パフォーマンスの基礎: 優れた論理設計と物理設計、およびシステムによって実行されるクエリ文に基づくスキーマ設計
この章では MySQL データベース設計に焦点を当て、mysql データベースを紹介します設計とその他のリレーショナル データベース管理 システムの違い
スキーマ: [出典]
スキーマは、データベース オブジェクトのコレクションです。このコレクションには、テーブル、ビュー、ストアド プロシージャ、インデックスなどのさまざまなオブジェクトが含まれています。異なるコレクションを区別するには、異なるコレクションに異なる名前を付ける必要があります。デフォルトでは、1 人のユーザーが 1 つのコレクションに対応し、ユーザーのデフォルトのスキーマとして使用されます。したがって、スキーマ コレクションはユーザー名のように見えます。 データベースを倉庫として考えると、倉庫には多くの部屋 (スキーマ) があり、1 つのスキーマが部屋を表し、テーブルは各部屋のロッカーとして見ることができ、ユーザーは各スキーマの所有者であり、各ルームの権限は、データベースにマップされた各ユーザーが各スキーマ (ルーム) のキーを持っていることを意味します。 SQL サーバーと Oracle mysql の違い
4.1 最適化されたデータ型を選択する
原則:
1、
パスは小さいほど良い、データを正しく保存できる最小のデータ型を使用するようにしてください (CPU キャッシュが必要とするディスク メモリの占有量が少なくなります)処理の CPU サイクルが少ない: 高速)、データをカバーできますが、保存できないと恥ずかしいです。 2. シンプルが良いです。シンプルなタイプ (CPU サイクルが少ない)、MySQL 組み込み型のストレージを使用します。 時間、整数。型は IP を格納します。整数型は文字より安価です (文字セットと照合ソート規則により文字が複雑になります) 3. null を避けるようにしてください: null ではないことを指定するのが最善です
*) Null 列はより多くのストレージを使用します 特別なスペースが必要ですmysql での処理
*) Null はインデックス作成、インデックス統計、および値の比較をより複雑にします; Null 許容カラムがインデックス付けされると、各インデックス レコードに追加のバイトが必要になります
例外: InnoDB は null を格納する別のビットを使用するため、スパースのスペース効率が優れていますデータ(null値が多い)、MyISAM
4.1.1整数型には適さない 【参考】
整数整数
tinyint(8ビット記憶空間) smallint(16)mediumint(24)int (32) bigint(64)
1. 保存される値の範囲:
、N は保存スペースの桁数です 2. 符号なし: オプション、負の値は許可されません。制限は 2 倍になります: tinyint unsigned 0~255、tinyint-128~127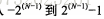 3。符号の有無にかかわらず同じ記憶領域を使用し、同じパフォーマンスを実現します
3。符号の有無にかかわらず同じ記憶領域を使用し、同じパフォーマンスを実現します
INT(11) などの整数の幅を指定できます。このアプリケーションには意味がなく、対話型ツールで表示される文字数を指定するだけです。int (1) と int (20) は同じです。 10 進数
float と double を使用する場合、mysql は内部浮動小数点計算のタイプとして duble を使用します
10 進数: 正確な小数点を格納します。mysql サーバー自体がそれを実装します。 10 進数 (18,9) 18 ビット、小数点以下 9 桁、9 バイト (最初4 と最後) 4 つのポイント 1)
財務データなど、小数の正確な計算 (追加のスペースと計算オーバーヘッド) を実行する場合にのみ使用するようにしてください
データ量が多い場合は、代わりに bigint の使用を検討し、変換します桁数は、対応する倍数で乗算されます。
浮動小数点:
推奨事項: 型と不定の精度 (mysql) のみを指定します。これらの精度は、MySQL では標準ではありません。保存時にサイレントに型を選択するか値を四捨五入する
値を同じ範囲に格納する 10 進数よりもスペースが少ない場合、float4 バイトは double8 バイトを格納します (高精度範囲)
4.1.3 文字列型
varchar と char :
前提: innodb および myisam エンジン、最も重要な文字列タイプ
ディスクストレージ: ストレージエンジンのストレージ方法はメモリやディスクのストレージ方法とは異なる必要があるため、mysql サーバーはエンジンからの値を次の形式に変換する必要があります形式
varchar:1. 変数文字列を格納すると、比率は固定されます。スペースが節約されます (必要なスペースのみが使用されます)。ただし、テーブルが row_format=fixed を使用している場合、行は固定長で格納されます
2. 文字列の長さを記録するには、追加の 1/2 バイトを使用する必要があります。1) 列の最大長 3. ストレージ領域を節約し、パフォーマンスを向上させます。ただし、更新中に行が元より長くなる可能性があり、追加の作業が必要になります
。 :1) 文字列列の最大長は平均の長さよりもはるかに長くなります。2) 列の更新が少なくなります (断片化の心配はありません)。3) UTF-8 文字列を使用し、各文字は異なる番号を使用して保存されます。バイト数
文字:
1. 固定長、長さに応じてスペースを割り当て、長さが足りない場合はスペースを埋めます。
2. char(1) は Y N のみを格納します。 1 バイト、varchar2 バイトの値、レコード長もあります
適切な状況:
1) 非常に短い文字列を格納するのに適しています。2) またはすべての値が同じ長さに近い。頻繁に変更されるデータは、保存時に簡単に断片化されません
対応するスペースとストレージ:
char 型が保存される場合、末尾のスペースは削除されます。データの保存方法は、メモリ エンジンが固定長のみをサポートします。行数 (最大長によりスペースが割り当てられます)
binary、varbinary: バイナリ文字列、bytecodeを格納しますが、長さが足りません。
4.1.5 ビット
ビット: mysql5.0
以前は tinyint と同義であった新機能
ビット (1) シングルビット フィールド、ビット (2) 2 ビット、最大長 64 ビット
動作要因 ストレージ エンジンMyISAM はすべての BIT 列をパックして格納します (17 個の個別のビット列には 17 ビットのストレージのみが必要ですが、myisam3 バイトは問題ありません)。他のエンジン、Memory および innoDB は、各ビット列を格納するのに十分な最小の整数型を使用します。ストレージ領域を節約しません。
Mysql はビットを文字列型 として扱い、ビット (1) 値を取得し、結果はバイナリ 0/1 を含む文字列になります。ほとんどのアプリケーションでは、これを使用しないことをお勧めします。 '... ,'値 n')、「値 n」パラメータはリスト内の n 番目の値を表します。これらの値の末尾のスペースは、フィールド要素シーケンス システムによって自動的に削除されます。重複を定義された順序で表示し、一度だけ保存します。
基本的な形式はENUM型と同じです。 SET 型の値は、リスト内の 1 つの要素または複数の要素の組み合わせを取ることができます。複数の要素を取得する場合は、要素をカンマで区切ります。 SET 型の値は最大 64 個の要素の組み合わせしかできません。メンバーに応じて、ストレージも異なります: [参考、enum と同じ] ![[MySQL データベース] 第 4 章の解釈: スキーマとデータ型の最適化 (パート 1)](https://img.php.cn//upload/image/636/907/440/1533621119495187.png "1533621119495187.png")
1~8成员的集合,占1个字节。 9~16成员的集合,占2个字节。 17~24成员的集合,占3个字节。 25~32成员的集合,占4个字节。 33~64成员的集合,占8个字节。多くの true と false の値を保持する必要があります。これらの列を にマージすることを検討できます。 set タイプは、mysql によって内部的に一連の
パックされたビット
(ストレージスペースの効率的な使用) として表され、mysql にはクエリでの使用に便利な find_in_set 関数と field 関数があります
。欠点: 列の定義を変更するコストが高く、テーブルの変更が必要で、set を介してインデックス検索を実行できません。 整数列のビット単位の操作:
set の代わりに、整数を使用して一連のビットをパックします。 tinyint には 8 ビットを詰めることができ、ビットごとの演算を行うには、ビットの名前定数を定義して作業を簡略化しますが、このクエリ文は記述が難しく、4.1.6 識別子の識別子を選択する識別列です。 : 自動増加列 [ソース]
1) 手動で値を挿入する必要はありません。システムによってデフォルトのシーケンス値が提供されます。2) 主キーと一致する必要はありません。3) 一意のキーである必要があります。
4) 最大 1 つのテーブル; 5) タイプは数値のみです。 5) set auto_increment_increment=3 ;
ID 列のタイプを選択するときは、ストレージのタイプと mysql の計算方法を考慮してください。この型を決定した後は、すべての関連テーブルで同じ型を使用し、型が正確に一致している必要があります。ヒント:
1. 整数型: 通常、整数が最良の選択です。高速で auto_increment を使用できます 2. 列挙型とセット型、固定情報を保存します3. 文字列: 数値よりもスペースを消費するのが遅く、myisam テーブルには特に注意してください (デフォルトの文字列圧縮、クエリが遅い)
1) 新しい完全に「ランダム」な文字列 MD5/SHA1/UUID 関数によって生成された値は、広いスペースに任意に分散され、挿入と一部の選択の変更が発生します。 遅い:挿入値はインデックス内の異なる場所にランダムに書き込まれます
。 、挿入が遅くなります (ページ分割ディスクはクラスター化インデックスのフラグメントにランダムにアクセスします)、選択が遅くなります。論理的に隣接する行がディスクとメモリ上の異なる場所に分散されます。 ランダムな値により、あらゆる種類のクエリに対してキャッシュの効率が低下します。ステートメント (アクセス局所性原則
を無効にする)クラスター化インデックス
、実際に格納されているシーケンシャル構造、およびデータストレージの物理構造
一般的に、物理的なシーケンス構造は 1 つだけ存在し、唯一存在することができます。テーブルの 1 つのクラスター化インデックス。通常、デフォルトは主キーです。主キーを設定すると、システムはデフォルトでクラスター化インデックスを追加します。レコードの物理的な順序。また、論理順序は必ずしも接続されているわけではなく、データのストレージ物理構造とは関係がありません。テーブルに対応する非クラスター インデックスが多数存在する可能性があり、必要な非クラスター インデックスが確立される可能性があります。クラスター化インデックス; 2) uuid を格納し、- 記号を削除するか、unhex を使用して uuid 値を 16 バイトの数値に変換し、取得時に 16 進数形式で格納します。 ; UUID によって生成される値は、暗号化ハッシュ関数 (sha1) によって生成される値とは異なります。 特徴: uuid は不均等に分散されており、一定の順序を持っています。 自動生成されるスキーマに注意してください。 深刻なパフォーマンスの問題、非常に大きな varchar、関連するさまざまな型の列
orm は、あらゆる種類のバックエンド データ ストレージにあらゆる種類のデータを保存しますが、より優れた種類のストレージを使用するように設計されていない場合があり、各オブジェクトの属性ごとに個別の行を使用し、タイムスタンプを使用するように設定されます。 -ベースのバージョン管理。単一の属性の複数のバージョンがトレードオフになります
4.1.7 特殊な型のデータ: 空
関連記事:
第 3 章の解釈: サーバー パフォーマンス分析 (パート 1)
[MySQL データベース] 第 3 章の解釈: サーバー パフォーマンス分析 (パート 2)
以上が[MySQL データベース] 第 4 章の解釈: スキーマとデータ型の最適化 (パート 1)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。