
ホームページ >Java >&#&チュートリアル >JVM ガベージ コレクション アルゴリズムと JVM のヒープ メモリ内の 3 つの領域
JVM ガベージ コレクション アルゴリズムと JVM のヒープ メモリ内の 3 つの領域
- php是最好的语言オリジナル
- 2018-07-30 11:24:372114ブラウズ
一般的な JVM ガベージ コレクション アルゴリズム
jdk1.7.0_79
ご存知のとおり、Java はプログラマが手動でメモリを管理する必要がなく、JVM に完全に依存して自動的にメモリを管理します。メモリは自動的に管理されるため、ガベージメモリのリサイクルメカニズムまたはリサイクルアルゴリズムが必要です。この記事では、いくつかの一般的なガベージ コレクション (以下、GC) アルゴリズムを紹介します。
Javaヒープ上のインスタンスオブジェクトにメモリが割り当てられると、仮想マシンスタック上の参照変数にはインスタンスオブジェクトの開始アドレスが格納されます。
Object obj = new Object();

今度は変数にnullを代入してみましょう。
obj = null;
この時点で、Javaヒープ上のインスタンスオブジェクトが再度参照できないことがわかります。その場合、それはGCされたオブジェクトです。このオブジェクトを「デッド」と呼びます。仮想マシン スタック上の obj 変数はどうなるのでしょうか? 「JVM の概要 - ランタイム データ領域」で説明したように、仮想マシン スタックはスレッドに対して排他的です。つまり、スレッドが破棄されると、仮想マシン スタックは初期化され、スレッドが初期化されると終了します。スタック 当然リサイクルされます。これは、仮想マシン スタック上のメモリ領域が仮想マシン GC の範囲内にないことを意味します。次の図は、ガベージコレクションのメモリ範囲を示しています。

参照カウンタが0の場合、オブジェクトに参照カウンタが追加されます。他に引用する場所がないことを意味します。ローカル参照がある場合は +1、参照が無効な場合は -1。これは面白くて単純なアルゴリズムのように思えますが、実際には、このアルゴリズムはオブジェクト循環参照という致命的な問題を引き起こすため、ほとんどの Java 仮想マシンでは使用されていません。オブジェクト A は B を指し、オブジェクト B は今度は A を指します。このとき、それらの参照カウンタは 0 ではありませんが、実際には両方とも何も指していないため意味がありません。そこで、次のアルゴリズムを導入します。
2.
オブジェクトは「死んでいる」アルゴリズム - 到達可能性分析アルゴリズム このアルゴリズムは、オブジェクトの循環参照の状況を効果的に回避できます。オブジェクトインスタンス全体がツリーとして表示され、ルートノードが「GC ルート」と呼ばれるオブジェクトは、このオブジェクトから開始され、下方向に検索され、ツリーを横断した後、マークされていないオブジェクトは「デッド」と判断され、リサイクルできます。
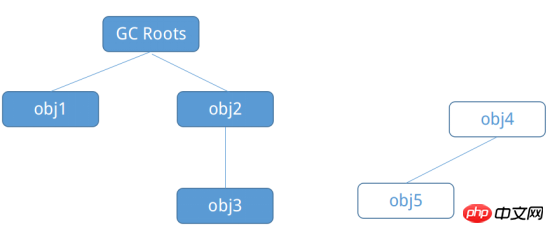
1.
マーククリアアルゴリズムリサイクルされるオブジェクトの「マーク」プロセスを待機することは、マークされた直後にオブジェクトがクリアされる場合に前述しました。メモリの断片化という新たな問題が発生します。より大きなオブジェクト インスタンスが次回、ヒープ上により大きなメモリ領域を割り当てる必要がある場合、十分な連続メモリを見つけることができない可能性があり、ガベージ コレクションを再度トリガーする必要があります。
2.
コピーアルゴリズム(Javaヒープにおける新世代のガベージコレクションアルゴリズム)このGCアルゴリズムは、マーククリアアルゴリズムによって引き起こされる「メモリの断片化」問題を実際に解決します。まず、リサイクルするメモリとリサイクルする必要のないメモリをマークします。次のステップでは、古いメモリ領域を完全にリサイクルできるように、リサイクルする必要のないメモリを新しいメモリ領域にコピーします。 、新しいメモリ領域は連続しています。欠点は、コピーのために常に一部のメモリを解放する必要があるため、システム メモリの一部が失われることです。
「JVM入門 - ランタイムデータ領域」で述べたように、Javaヒープは新世代と旧世代に分割されています。この分割はGCを容易にするためのものです。 Java ヒープの新しい世代では、GC コピー アルゴリズムが使用されます。新しい世代は、Eden スペース、To Survivor スペース、From Survivor スペースの 3 つのエリアに分割されており、From Survivor スペースと To Survivor スペースは同じサイズであり、1 つは空であることが保証されています。この図の左側にある新しい世代の部分に注目してください:
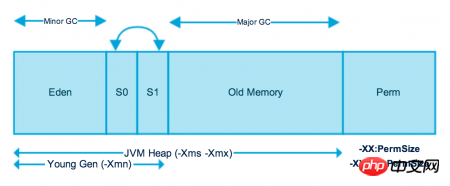 新しいオブジェクト インスタンスが作成されるとき、それは通常 Eden 空間にあります。Eden 空間で発生する GC は次のとおりです。新しい世代の場合、GC が発生した後、
新しいオブジェクト インスタンスが作成されるとき、それは通常 Eden 空間にあります。Eden 空間で発生する GC は次のとおりです。新しい世代の場合、GC が発生した後、
は Eden のメモリと Survivor スペースの 1 つを別の Survivor にコピーします。オブジェクトが複数回存続すると、メモリ オブジェクトはコピーされます。古い世代に移動されます。エデンが新世代の大部分を占めているのに対し、2人の生存者は実際には非常に小さな部分を占めていることがわかります。これは、ほとんどのオブジェクトが作成後すぐに GC されるためです (ここでは 80/20 原則が使用される可能性があります)。
3.标记-压缩算法(或称为标记-整理算法,Java堆中老年代的垃圾回收算法)
对于新生代,大部分对象都不会存活,所以在新生代中使用复制算法较为高效,而对于老年代来讲,大部分对象可能会继续存活下去,如果此时还是利用复制算法,效率则会降低。标记-压缩算法首先还是“标记”,标记过后,将不用回收的内存对象压缩到内存一端,此时即可直接清除边界处的内存,这样就能避免复制算法带来的效率问题,同时也能避免内存碎片化的问题。老年代的垃圾回收称为“Major GC”。
不积跬步,无以至千里;不积小流,无以成江海。
1.JVM的堆栈
栈:在jvm中栈用来存储一些对象的引用、局部变量以及计算过程的中间数据,在方法退出后那么这些变量也会被销毁。它的存储比堆快得多,只比CPU里的寄存器慢
堆:用来存储程序中的一些对象,比如你用new关键字创建的对象,它就会被存储在堆内存中,但是这个对象在堆内存中的首地址会存储在栈中。
栈内存在JVM中默认是1M,可以通过下面的参数进行设置
-Xss
1
最小堆内存在JVM中默认物理内存的64分之1,最大堆内存在JVM中默认物理内存4分之一,且建议最大堆内存不大于4G,并且设置-Xms=-Xmx避免每次GC后,调整堆的大小,减少系统内存分配开销
-Xms -Xmx
1
2
3
在jvm的堆内存中有三个区域:
1.年轻代:用于存放新产生的对象。
2.老年代:用于存放被长期引用的对象。
3.持久带:用于存放Class,method元信息。
如图:

一.年轻代
年轻代中包含两个区:Eden 和survivor,并且用于存储新产生的对象,其中有两个survivor区如图:

可以使用参数配置年轻代的大小,如果配置它为100M那么就相当于2*survivor+Eden = 100M
-Xmn
1
可以配置Eden 和survivor区的大小,这里配置的是比值,jvm中默认为8,意思就是Eden区的内存比上survivor的内存等于8,如果年轻代的Xmn配置的100M,那么Eden就会被分配80M内存,每个survivor分配10M内存
-XX:SurvivorRatio
1
还可以配置年轻代和老年代的比值,这里需要注意:老年代的内存就是通过这个比值设置,jvm没有给你直接设置老年代内存大小的参数;如果整个堆内存设为100M并且在这里设置年轻代和老年代的比值为7,如果持久代占用了10M,那么100M-10M=90M这里的90M就是老年代和年轻代的内存总和,且年轻代占用(90/(7+1)*7)的内存,老年代就占用(90/(7+1)*1)的内存。
-XX:NewRatio
1
二.老年代
年轻代在垃圾回收多次都没有被GC回收的时候就会被放到老年代,以及一些大的对象(比如缓存,这里的缓存是弱引用),这些大对象可以不进入年轻代就直接进入老年代(1.防止新生代有大量剩余的空间,而大对象创建导致提前发生GC;2.防止在eden区和survivor区的大对象复制造成性能问题),这个可以通过如下参数设置,表示单个对象超过了这个值就会直接到老年带(默认为0):
-XX:PretenureSizeThreshold
1
并且大的数组对象也会直接放到老年代,比如array和arrayList(底层用数组实现),因为数组需要连续的空间存储数据。
三.持久代
持久代用来存储class,method元信息,大小配置和项目规模,类和方法的数量有关,一般配置128M就够了,设置原则是预留30%空间,它可以通过如下参数进行大小配置:
-XX: PermSize -XX: MaxPermSize
1
2
持久代也可能会被GC回收,如果持久代理的常量池没有被引用以及一些无用的类信息和类的Class对象也会被回收。
相关文章:
Java ガベージ コレクションとオブジェクトのライフ サイクルの詳細な説明
関連動画:
以上がJVM ガベージ コレクション アルゴリズムと JVM のヒープ メモリ内の 3 つの領域の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。