
ホームページ >データベース >mysql チュートリアル >mysql データベースのサブデータベースとテーブルのサブテーブルにおける技術的問題を解決する戦略
mysql データベースのサブデータベースとテーブルのサブテーブルにおける技術的問題を解決する戦略
- php是最好的语言オリジナル
- 2018-07-24 17:02:483895ブラウズ
MySQL データベースのサブデータベースとテーブル スキームでは、データベースが大きすぎると、特に書き込みが頻繁で 1 つのホストでサポートするのが難しい場合、拡張のボトルネックに直面することになります。現時点では、このボトルネックを解決するための他の技術的手段を見つける必要があります。それが、この章で紹介する悪いデータ セグメンテーション テクノロジです。
mysql データベースのシャーディング
はじめに
MySQLReplication 関数によって達成される拡張は、データベースのサイズによって常に制限されます。データベースが大きすぎると、特に書き込みが頻繁で 1 台のホストでサポートするのが難しい場合には、依然として拡張のボトルネックに直面することになります。現時点では、このボトルネックを解決するための他の技術的手段を見つける必要があります。それが、この章で紹介する悪いデータ セグメンテーション テクノロジです。
データシャーディングとは
多くの読者はデータシャーディングに関する関連記事をインターネットや雑誌で何度も目にしたことがあるかもしれませんが、一部の記事では単にデータのシャーディングと呼ばれています。実際、データのシャーディングと呼ばれても、データのセグメント化と呼ばれても、概念は同じです。簡単に言うと、特定の条件によって、同じデータベースに保存されているデータが複数のデータベース (ホスト) に分散して配置され、単一デバイスの分散負荷の効果が得られることを意味します。データのセグメント化により、単一のデバイスがクラッシュした後のシステム全体の可用性も向上します。利用できないのはデータ全体の一部だけであり、すべてのデータが利用できるわけではありません。
データのシャーディングは、シャーディング ルールのタイプに基づきます。 2 つのセグメンテーション モードに分けることができます。
1 つは、異なるテーブル (またはスキーマ) に従って異なるデータベース (ホスト) に分割することです。この種の分割は、データの垂直 (垂直) 分割と呼ばれます。もう 1 つは、テーブル内のデータの論理関係に基づいて、同じテーブル内のデータを特定の条件に従って複数のデータベース (ホスト) に分割することです。このような分割をデータの水平(水平)分割と呼びます。
垂直セグメンテーションの最大の特徴は、ルールがシンプルであり、実装がより便利であることです。ビジネス間の結合が非常に低い場合に特に適しています。インタラクションがほとんどなく、非常に明確なビジネス ロジックを備えたシステム。このようなシステムでは、さまざまなビジネス モジュールで使用されるテーブルをさまざまなデータベースに分割するのが非常に簡単です。異なるテーブルに従って分割します。アプリケーションへの影響も小さくなり、分割ルールがよりシンプルかつ明確になります。
水平セグメンテーションは垂直セグメンテーションと比較されます。比較的に言うと、少し複雑です。同じテーブル内の異なるデータを異なるデータベースに分割する必要があるため、アプリケーションにとっては、テーブル名に基づいて分割するよりも分割ルール自体が複雑になり、その後のデータのメンテナンスも複雑になります。
データの量と 1 つ (または一部) のテーブルへのアクセスが特に大きく、垂直方向にスライスして独立したデバイスに配置した後でもパフォーマンス要件を満たせない場合は、垂直方向にシャード分割と水平方向の分割を組み合わせて行う必要があります。スライス。まず縦に切り、次に横に切ります。この方法でのみ、このような非常に大きなテーブルのパフォーマンスの問題を解決できます。以下では、垂直分割、水平分割、複合分割分割の 3 つのデータ切り出し方法の実装について分析します。
データの垂直セグメント化
まず、データの垂直セグメント化とは何かを見てみましょう。データの垂直スライス。垂直セグメンテーションとも呼ばれます。データベースは、一度に 1 つのチャンクが多数の「データ チャンク」(テーブル) で構成されていると考えてください。これらの「データ チャンク」を垂直に分割し、複数のデータベース ホストに分散させます。このような分割方法は、垂直(縦方向)データ分割です。
優れたアーキテクチャ設計を備えたアプリケーション システム。その全体的な機能は、多くの機能モジュールで構成されている必要があります。各機能モジュールが必要とするデータは、データベース内の 1 つ以上のテーブルに対応します。
そして、アーキテクチャ設計では、各機能モジュール間の相互作用点がより統合され、少なくなるほど、システムの結合度が低くなり、システムの各モジュールの保守性と拡張性が向上します。そんなシステム。データの垂直セグメント化を実現するのが容易になります。
機能モジュールがより明確になり、結合が低ければ、垂直方向のデータセグメンテーションのルールを定義するのが簡単になります。データは機能モジュールに従ってセグメント化でき、異なる機能モジュールのデータは異なるデータベース ホストに保存されるため、データベース間の結合の存在を簡単に回避できます。同時に、システムアーキテクチャも非常に明確です。
もちろんです。システムが、結合操作のためにお互いのテーブルや 2 つのモジュールのテーブルにアクセスする必要なしに、すべての機能モジュールによって使用されるテーブルを完全に独立させることは非常に困難です。この場合、実際のアプリケーション シナリオに基づいて評価し、検討する必要があります。同じデータベースに結合する必要があるテーブルのすべての関連データをアプリケーションに格納できるようにするか、アプリケーションに他の多くのことを実行させるか、つまりプログラムが完全にモジュール インターフェイスを通じて異なるデータベースからデータを取得できるようにするかを決定します。その後、プログラム内で結合操作が完了します。
一般的に言えば。負荷が比較的軽いシステムで、テーブルの関連付けが非常に頻繁に行われるとします。そうなると、データベースが機能しなくなる可能性があります。複数の関連モジュールをマージしてアプリケーションの作業を軽減するソリューションを使用すると、作業負荷をさらに軽減できます。実現可能な解決策です。
もちろんです。データベースの譲歩により、複数のモジュールがデータ ソースを一元的に共有できるようになりますが、実際には、各モジュール アーキテクチャの結合が増大する開発が簡単に導入され、将来のアーキテクチャがますます悪化する可能性があります。特に、開発の特定の段階に達すると、データベースがこれらのテーブルによってもたらされる圧力に耐えられないことがわかります。また別れの時を迎えなければなりません。構造変更のコストは初期コストよりもはるかに高くなる可能性があります。
それで。データベースが垂直に分割されている場合、それをどのように分割するか、どの範囲まで分割するかは難しい問題です。これは、実際のアプリケーション シナリオにおけるあらゆる側面のコストと利点のバランスを取ることによってのみ実現できます。そうして初めて、本当に自分に合った分割プランを分析することができます。
たとえば、本書で使用されているデモ システムで使用されているサンプル データベースを簡単に分析してみましょう。次に、垂直分割を実行するための単純なセグメンテーション ルールを設計します。
システム機能は基本的に、ユーザー、グループメッセージ、フォトアルバム、イベントの 4 つの機能モジュールに分けることができます。たとえば、次のテーブルに対応します:
1. ユーザー モジュール テーブル: user、user_profile、user_group、user_photo_album
2. グループ ディスカッション テーブル: groups、group_message、group_message_content、top_message
3. フォト アルバム関連テーブル: photo 、photo_album 、photo_album_relation、photo_comment
4. イベント情報テーブル:event
一見すると、どのモジュールも他のモジュールから独立して存在することはできず、モジュール間には関係があります。もしかして分割できないのでしょうか? もちろんそうではありません。もう少し詳しく分析してみましょう。各モジュールで使用されるテーブルは関連していますが、その関係は比較的明確で単純であることがわかります。 ◆ グループ ディスカッション モジュールとユーザー モジュールは、主にユーザーまたはグループの関係を通じて関連付けられます。通常、関連付けはユーザーの ID またはニックネームとグループの ID を通じて行われます。モジュール間のインターフェースを介して実装しても、それほど問題は発生しません。 ◆ フォトアルバムモジュールはユーザーを通じてのみユーザーモジュールと関連付けられます。これら 2 つのモジュール間の関連付けは、基本的にユーザー ID を通じてコンテンツに関連付けられます。シンプルで明確なインターフェイスです。◆ イベント モジュールは各モジュールに関連付けられていますが、各モジュール内のオブジェクトの ID 情報のみに焦点を当てており、非常に簡単に分割することもできます。 それで。最初のステップは、機能モジュールに関連するテーブルに従ってデータベースを垂直に分割することです。各モジュールに含まれるテーブルは別のデータベースに保存され、モジュール間のテーブルの関係はアプリケーション システム側のインターフェイスを通じて処理されます。たとえば、以下の図でわかるように:
これによりデータベース上の全体的な操作数が確かに増加しますが、システム全体のスケーラビリティとアーキテクチャのモジュール性の観点からは意図的なものです。一部の操作の単一応答時間はわずかに増加する場合があります。ただし、システムの全体的なパフォーマンスはある程度向上する可能性が非常に高くなります。そして拡張のボトルネック問題。これは、次のセクションで紹介するデータ水平セグメンテーション アーキテクチャに依存することによってのみ克服できます。
データの水平方向のセグメント化
上のセクションではデータの垂直方向のセグメント化を分析および紹介します。このセクションではデータの水平方向のセグメント化を分析します。データの垂直方向のセグメント化は、基本的にテーブルとモジュールに従ってデータをセグメント化することとして単純に理解できますが、水平方向のセグメント化はテーブルや機能モジュールに従ってセグメント化されなくなります。一般的に、単純な水平シャーディングとは、アクセスが極めて平凡なテーブルを、ある分野の一定のルールに従って複数のテーブルに分散させることが主です。各テーブルにはデータの一部が含まれています。
簡単に言えば。データの水平方向の分割は、データ行に応じた分割として理解できます。これは、テーブル内の一部の行が 1 つのデータベースに分割され、他の行が他のデータベースに分割されることを意味します。もちろん、各行のデータがどのデータベースに分割されるかを簡単に判断するには、必ず一定のルールに従って分割を行う必要があります。
_数値型フィールド、特定の時間型フィールドの範囲。または文字型フィールドのハッシュ値。システム全体のほとんどのコア テーブルは、特定のフィールドを通じて関連付けることができると想定されています。もちろん、このフィールドは水平分割に最適です。非常に特殊で使用できない場合は、別のフィールドを選択するしかありません。
一般に、今日のインターネットでは Web2.0 タイプのサイトが非常に人気があります。基本的に、ほとんどのデータはメンバー ユーザー情報を通じて関連付けることができ、多くのコア テーブルはメンバー ID によるデータの水平セグメント化に非常に適しています。
フォーラム コミュニティ ディスカッション システムのようなものもあります。フォーラム番号に従ってデータを水平にセグメント化するのはさらに簡単です。
分割後のライブラリ間の相互作用は基本的にありません。样 当社のデモサンプルシステムとして。すべてのデータはユーザーに関連付けられています。次に、ユーザーに基づいて水平分割を実行し、異なるユーザーのデータを異なるデータベースに分割できます。もちろん、唯一の違いは、ユーザー モジュールのグループ テーブルがユーザーに直接関連していないことです。したがって、グループをユーザーに基づいて水平に分割することはできません。このような特殊な場合には、完全に単独で対応できます。別のデータベースに個別に配置されます。
実際、このアプローチは、前のセクションで紹介した「データの垂直分割」手法を利用していると言えます。次のセクションでは、垂直分割と水平分割を同時に使用する結合分割方法をさらに詳しく紹介します。
したがって、デモ サンプル データベースでは、ほとんどのテーブルはユーザー ID に基づいて水平方向にセグメント化できます。さまざまなユーザーに関連するデータはセグメント化され、さまざまなデータベースに保存されます。たとえば、すべてのユーザー ID は 2 を法として取得され、2 つの異なるデータベースに保存されます。
ユーザー ID に関連付けられたすべてのテーブルは、この方法でセグメント化できます。このようにして、基本的にすべてのユーザー関連データが収集されます。これらはすべて同じデータベース内にあるため、関連付ける必要がある場合でも、非常に簡単に関連付けることができます。
次の図を使用して、水平シャーディングの関連情報をより直感的に表示できます: 水平シャーディングの利点
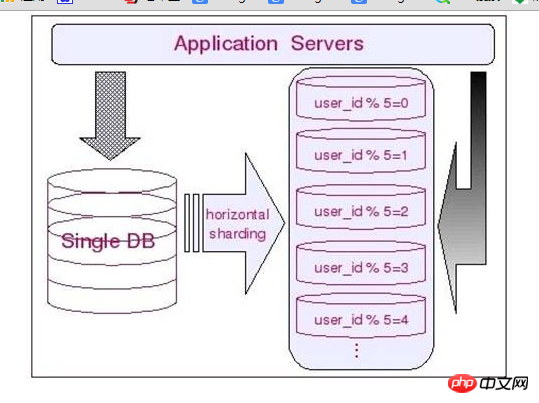 ◆ テーブルの関連付けは基本的にデータベース側で完了できます
◆ テーブルの関連付けは基本的にデータベース側で完了できます
◆ 超大規模なものはありません。大量のデータと高負荷を含むテーブルでは、ボトルネックの問題が発生します。
◆ アプリケーション側の全体的なアーキテクチャの変更は比較的少ないです
◆ 定義できるのはセグメント化ルールのみです。基本的にスケーラビリティの制限が発生しにくいです。
水平シャーディングの欠点
◆ シャーディング ルールは比較的複雑で、データベース全体を満たすシャーディング ルールを抽象化するのが非常に困難です
◆ 後で保守するのが困難です。データ データを手動で見つけるのはさらに困難であることが追加されました。
◆ アプリケーション システムの各モジュールの結合度が高いため、後続のデータの移行や分割に特定の困難が生じる可能性があります。
上記 2 つのセクションでは、垂直切断と水平切断の組み合わせが使用されます。 「縦」と「横」の2つの分割方法の実装と分割後のアーキテクチャ情報についてそれぞれ学びました。同時に、2 つのアーキテクチャの長所と短所も分析されました。しかし、実際のアプリケーションシナリオでは、それらを除いて負荷はそれほど大きくありません。比較的単純なビジネス ロジックを備えたシステムは、上記の 2 つのセグメント化方法のいずれかを使用してスケーラビリティの問題を解決できます。もう少し複雑なビジネス ロジックと大きなシステム負荷を備えた他のほとんどのシステムでは、上記のデータ セグメンテーション方法のいずれを使用しても優れたスケーラビリティを実現できないのではないかと思います。上記 2 つのセグメンテーション方法を組み合わせて、異なるシナリオでは異なるセグメンテーション方法を使用する必要があります。 このセクションでは。垂直スライシングと水平スライシングの長所と短所を組み合わせて、アーキテクチャ全体をさらに改善し、システムのスケーラビリティをさらに向上させます。 一般的に言えば。 1 つ (またはいくつか) のフィールドを介してデータベース内のすべてのテーブルを接続することは非常に困難であるため、データを水平にセグメンテーションするだけですべての問題を解決することは非常に困難です。垂直シャーディングでは問題の一部しか解決できません。負荷が非常に高いシステムでは、単一のテーブルですら単一のデータベース ホストの負荷に耐えることができません。垂 「縦」と「横」の2つのカット方法を同時に使用し、それぞれの長所を活かして短所を回避する必要があります。 すべてのアプリケーション システムの負荷が段階的に増加し、パフォーマンスのボトルネックが発生し始めると、ほとんどのアーキテクトや DBA はコストが高いため、まずデータを垂直分割することを選択します。これは、この期間に追求された最大入出力比と最も一致しています。しかし。ビジネスが拡大し続けるにつれて。システム負荷が増大し続けると、システムが一定期間安定した後、垂直分割されたデータベース クラスターが再び過負荷になり、パフォーマンスのボトルネックが発生する可能性があります。この時、私たちは何を選択すべきでしょうか?モジュールを再度さらに細分化するか、それとも他の解決策を模索する必要がありますか?最初と同じようにモジュールを細分化し、データの垂直セグメント化を実行し続けると仮定すると、近い将来、現在直面しているのと同じ問題に遭遇する可能性があります。そして、モジュールが継続的に改良されるにつれて、アプリケーション システムのアーキテクチャはますます複雑になり、システム全体が制御不能になる可能性が非常に高くなります。 現時点で、ここで発生する問題を解決するには、データの水平セグメント化を利用する必要があります。さらに、水平データ セグメンテーションを使用する場合、垂直データ セグメンテーションの以前の結果を覆す必要はありません。代わりに、水平セグメンテーションの利点を利用して垂直セグメンテーションの欠点を回避します。システムの複雑さが増大するという問題を解決します。 horizontal水平分割の欠点(ルールを統一するのは困難です)も、以前の垂直分割によって解決されました。水平分割を簡単にします。样 当社のデモサンプルデータベース用。初めに仮定します。データの垂直セグメンテーションを実行しましたが、ビジネスが成長し続けるにつれてデータベース システムがボトルネックに遭遇したため、データベース クラスターのアーキテクチャを再構築することにしました。リファクタリングするにはどうすればよいですか?データの垂直分割は以前にも行われていることを考慮すると、モジュール構造は明確です。 そして、ビジネス成長の勢いはますます強くなっています。今さらにモジュールを分割しても長くは続かないでしょう。 垂直方向のセグメンテーションに基づいて水平方向に分割することを選択しました。垂直分割後の各データベース クラスターには、機能モジュールが 1 つだけあります。基本的に、各機能モジュール内のすべてのテーブルは特定のフィールドに関連付けられています。たとえば、すべてのユーザー モジュールはユーザー ID によってセグメント化でき、グループ ディスカッション モジュールはすべてグループ ID によってセグメント化できます。フォト アルバム モジュールは、アルバム ID に基づいてセグメント化されます。最終的なイベント通知情報テーブルは、データの期限を考慮して(最近のイベントセグメントの情報のみにアクセスする)、時間ごとに分割されていると考えられます。 次の図は、セグメンテーション後のアーキテクチャ全体を示しています:実際、多くの大規模アプリケーション システムでは、基本的に垂直セグメンテーションと水平セグメンテーションの 2 つのデータ セグメンテーション方法が共存しています。そして、これらはシステムの拡張機能を継続的に追加するために交互に実行されることがよくあります。さまざまなアプリケーション シナリオに対処するときは、これら 2 つのセグメント化方法の制限と利点も十分に考慮する必要があります。異なるタイミング (負荷圧力) で異なる接着方法を使用します。
ジョイントシャーディングの利点
◆ 垂直スライスと水平スライスの利点を最大限に活用し、それぞれの欠点を回避できます
◆ システムのスケーラビリティを最大化します。
関節セグメンテーションの欠点
◆ データベース システム アーキテクチャは比較的複雑です。メンテナンスはさらに困難になります。
◆ アプリケーション アーキテクチャも、前の章で説明したように、
データのセグメント化と統合のソリューション
よりも比較的複雑です。データベースによるデータのセグメント化によりシステムのスケーラビリティが大幅に向上することはすでに明確にしました。ただし、データベース内のデータが垂直および/または水平セグメンテーションを通じて異なるデータベース ホストに保存された後、アプリケーション システムが直面する最大の問題は、これらのデータ ソースをより適切に統合する方法です。おそらくこれは、多くの読者が非常に懸念している問題でもあります。このセクションの主な焦点は、データのセグメンテーションとデータ統合の実現に役立つさまざまな全体的なソリューションを分析することです。
この効果を達成するためにデータベース自体に依存してデータを統合することは非常に困難ですが、MySQL には同様の問題をいくつか解決できる Federated Storage エンジンがあります。ただし、実際のアプリケーションシナリオでそれをうまく使用することは非常に困難です。では、さまざまな MySQL ホストに分散しているこれらのデータ ソースをどのように統合するのでしょうか?
一般に、次の 2 つの解決策があります:
1. 各アプリケーション モジュールで必要な 1 つ (または複数) のデータ ソースを構成および管理します。各データベースに直接アクセスし、モジュール内でデータ統合を完了します。
2. 中間プロキシ層を介してすべてのデータ ソースを統合します。バックエンド データベース クラスターはフロントエンド アプリケーションに対して透過的です
おそらく 90% 以上の人は、特にシステムが大規模で複雑になり続ける場合、上記の 2 つのソリューションに直面した場合、もう一方を選択する傾向があるでしょう。
確かに。これは非常に正しい選択ですが、短期的なコストは比較的大きくなる可能性がありますが、システム全体のスケーラビリティには非常に役立ちます。したがって、ここでは最初のソリューションについてはあまり多くの分析を準備しません。以下では、別のソリューションでのいくつかのソリューションの分析に焦点を当てます。
★ 独自の中間プロキシ レイヤーを開発する
データ ソース統合のアーキテクチャの方向性を解決するためにデータベースの中間プロキシ レイヤーを使用することを決定した後、多くの企業 (または企業) は、固有の要件を満たす独自のプロキシ レイヤーを開発することを選択しました。アプリケーションシナリオアプリ。 ingly中間プロキシ層を単独で開発することにより、独自のアプリケーションの特異性に最大限の程度に対処できること。個々のニーズに合わせた最大限のカスタマイズで変化にも柔軟に対応します。これが独自のプロキシ層を開発する最大のメリットと言えるでしょう。
もちろん、自分で開発してパーソナライズされたカスタマイズを最大限に楽しむことを選択する一方で、当然のことながら、初期の研究開発とその後の継続的なアップグレードと改善に多額の他のコストを投資する必要があります。また、技術的な敷居自体が単純な Web アプリケーションよりも高い場合があります。したがって、独自に開発することを決定する前に、より包括的な評価を行う必要があります。独自のアプリケーション システムに適切に適応し、ビジネス シナリオに対処する方法を検討するために多くの時間を費やしているため、ここで分析するのは簡単ではありません。後で、現在人気のあるいくつかのデータ ソース統合ソリューションを主に分析します。
★MySQLProxyを使用してデータのセグメント化と統合を実現します
MySQLProxyはMySQLが公式に提供するデータベースプロキシ層製品であり、MySQLServerと同様にGPLオープンソース契約に基づくオープンソース製品です。それらの間の通信情報を監視、分析、または送信するために使用できます。その柔軟性により、現在の機能には主に接続ルーティング、クエリ分析、クエリのフィルタリングと変更、ロード バランシングが含まれます。主要な HA メカニズムなどと同様に、
実際、MySQLProxy 自体には上記の機能がすべて備わっているわけではありません。代わりに、上記の機能を実装するための基盤を提供します。
これらの機能を実現するには、独自の LUA スクリプトを記述する必要もあります。
MySQLProxy は実際にクライアントリクエストと MySQLServer の間に接続プールを確立します。すべてのクライアント リクエストは MySQLProxy に送信され、対応する分析が MySQLProxy を通じて実行されます。読み取り操作であるか書き込み操作であるかが推測され、対応する MySQL Server に配信されます。マルチノードのスレーブ クラスターの場合、負荷分散も実現できます。以下は MySQLProxy の基本的なアーキテクチャ図です:
上記のアーキテクチャ図を通して。実際のアプリケーションにおける MySQLProxy の位置と、MySQLProxy で実行できる基本的なことが非常に明確にわかります。 ただし、MySQLProxy のより具体的な実装の詳細については、 MySQL 公式ドキュメントには、非常に具体的な導入例とデモ例が記載されています。興味のある読者は、MySQL 公式 Web サイトから直接無料でダウンロードするか、オンラインで読むことができます。ここでは紙の無駄については触れません。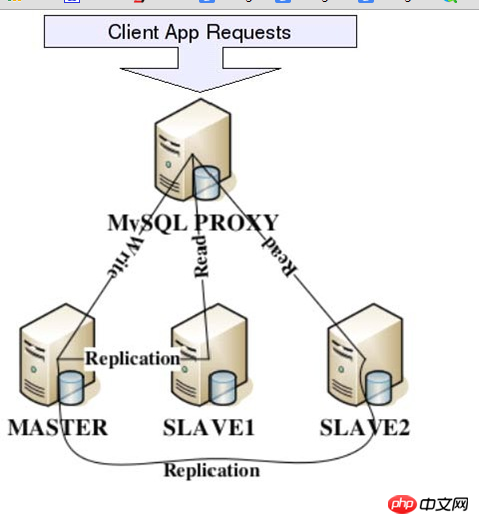 ★アメーバを活用してデータの細分化と統合を実現
★アメーバを活用してデータの細分化と統合を実現
Amoeba は Java に基づいて開発されたオープンソース フレームワークであり、分散データベース データ ソース統合プロキシ プログラムの解決に焦点を当てています。GPL3 オープンソース契約に基づいています。現在、Amoeba には、クエリ ルーティング、クエリ フィルタリング、読み書き分離、ロード バランシング、HA メカニズム、およびその他の関連コンテンツがすでに含まれています。
Amoeba は主に次の問題を解決します:
1. データセグメント化後に複雑なデータソースを統合します。
2. データセグメント化ルールを提供し、データベースに対するデータセグメント化ルールの影響を軽減します。
3. データベースとクライアント間の接続の数を減らします。
4. 読み取りと書き込みの分離ルーティング
Ameba が行っていることは、まさにデータのセグメント化を通じてデータベースのスケーラビリティを向上させるために必要なことであることがわかります。
Amoeba はプロキシ層 Proxy プログラムではなく、データベース プロキシ層 Proxy プログラムを開発するための開発フレームワークです。現在、Amoeba に基づいて開発された Proxy プログラムは AmoebaForMySQL と AmoebaForAladin の 2 つです。
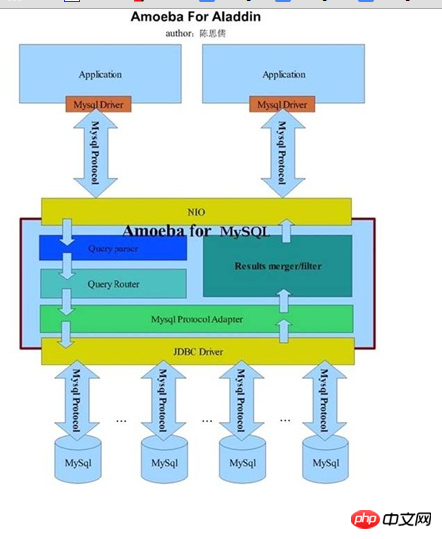
AmoebaForMySQL は主に MySQL データベースに特化したソリューションです。フロントエンド アプリケーションとバックエンドによって接続されるデータ ソース データベースが要求するプロトコルは MySQL である必要があります。どのクライアント アプリケーションにおいても、AmoebaForMySQL と MySQL データベースの間に違いはありません。 MySQL プロトコルを使用するクライアント リクエストは、AmoebaForMySQL によって解析され、それに応じて処理されます。以下は、AmoebaForMySQL のアーキテクチャ情報を示しています (Amoeba 開発者ブログより):
AmoebaForAladin は、より広範囲に適用できるものです。より強力なプロキシ プログラム。
異なるデータベースのデータ ソースに同時に接続してフロントエンド アプリケーションにサービスを提供できますが、受け入れられるのは MySQL プロトコルに準拠するクライアント アプリケーションのリクエストのみです。つまり、フロントエンド アプリケーションが MySQL プロトコルを通じて接続されている限り、AmoebaForAladin はクエリ ステートメントをアクティブに分析し、物理ホスト上のクエリ ステートメントで要求されたデータに基づいてクエリのデータ ソースを自動的に識別します。次の図は、AmoebaForAladin のアーキテクチャの詳細を示しています (Amoeba 開発者ブログから):
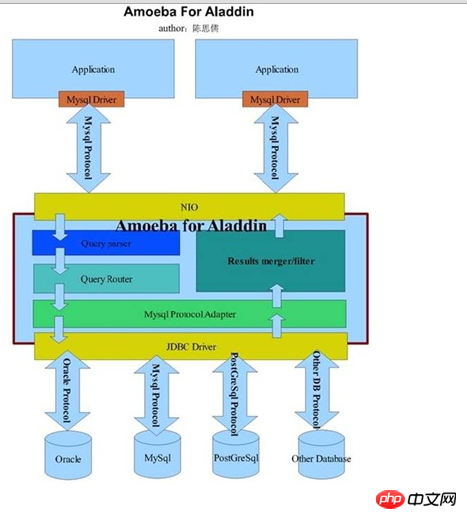
一見すると、この 2 つはまったく同じように見えます。詳しく見てみると、この 2 つの主な違いは、MySQLProtocalAdapter による処理後のみであることがわかります。分析結果に基づいてデータ ソース データベースが推測されます。次に、特定の JDBC ドライバーと対応するプロトコルを選択して、バックエンド データベースに接続します。
実際、上記の 2 つのアーキテクチャ図を通して、Amoeba は単なる開発フレームワークであることがわかったかもしれません。彼が提供した 2 つの製品、ForMySQL と ForAladin に加えて。独自のニーズに基づいて、対応する二次開発を実行することもできます。独自のアプリケーション特性により適したプロキシ プログラムを入手してください。
MySQLデータベースを使用する場合。 AmebaForMySQL と AmoebaForAladin はどちらも非常にうまく使用できます。もちろん、システムが複雑になるほど性能は確実に低下し、維持コストも相対的に高くなります。したがって、MySQL データベースのみを使用する必要がある場合には、AmoebaForMySQL を使用することをお勧めします。
AmoebaForMySQL の使い方は非常に簡単です。すべての設定ファイルは標準の XML ファイルであり、合計 4 つの設定ファイルがあります。それらは次のとおりです:
◆ amoeba.xml: メイン設定ファイル。すべてのデータ ソースと Amoeba 独自のパラメーター設定を構成します。
◆ rules.xml: すべてのクエリルーティングルール情報を設定します。
◆ functionMap.xml: クエリ内の関数に対応する Java 実装クラスを構成します。
◆ RullFunctionMap.xml: ルーティング ルールで使用する必要がある特定の関数の実装クラスを構成します。基本的に、すべての作業を完了するには、上記の 4 つの構成ファイルのうち最初の 2 つを使用するだけで済みます。プロキシ プログラムでよく使用される機能には、読み取りと書き込みの分離が含まれます。負荷分散やその他の設定は、amoeba.xml で実行されます。また。 Ameba は、データの垂直および水平シャーディングを実装する独自のアクティブ ルーティングをすでにサポートしています。ルーティングルールはrule.xmlで設定できます。現時点では AMOEBA は珍しく、オンライン管理機能とトランザクションのサポートがメインであり、関連する開発者とのコミュニケーションの過程で、オンライン保守管理を提供できるコマンドライン管理を提供したいと考えています。オンラインメンテナンスに便利なツールが開発スケジュールに専用の管理モジュールが含まれているというフィードバックが寄せられました。また、クライアントアプリケーションがアメーバに送信したリクエストに取引情報が含まれている場合でも、アメーバは取引関連情報を無視するため、一時的に取引をサポートできなくなります。もちろん、継続的な改善を経て、トランザクションサポートはアメーバが追加を検討する機能であることは間違いないと思います。
アメーバのより具体的な使用法をお持ちの読者は、アメーバ開発者ブログ (http://amoeba.sf.net) で提供されるユーザー マニュアルを通じて入手できますが、ここでは詳しく説明しません。
★HiveDB を使用してデータのセグメント化と統合を実現します
以前の MySQLProxy や Amoeba と同様、HiveDB もデータのセグメント化と統合を提供する Java ベースのオープンソース フレームワークです。ただし、現在の HiveDB はデータの分割のみをサポートしています。水平方向に。
データの冗長性とメインの HA メカニズムをサポートしながら、主にデータベースのスケーラビリティと大容量データ下での高パフォーマンスのデータ アクセスの問題を解決します。
HiveDB の実装メカニズムは、MySQLProxy や Amoeba とは若干異なります。データ冗長性を実現するために MySQL のレプリケーション機能を使用するのではなく、独自のデータ冗長性メカニズムを実装しており、その基礎となる層は主に HibernateShards によって実装されたデータに基づいています。作品。 B HiveDB では、ユーザー独自の定義によるさまざまな PartitionKey (実際にはデータ分割ルールを策定するため) を介して、データが複数の MySQLServer に分散されます。訪問時。 Queryリクエストを実行するとき。フィルター条件を自ら積極的に分析し、複数の MySQL サーバーから並行してデータを読み取り、結果セットをマージしてクライアント アプリケーションに返します。機能の観点から見ると、HiveDB は MySQLProxy や Amoeba ほど強力ではないかもしれませんが、データ切断の考え方は前の 2 つと本質的に変わりません。さらに、HiveDB はオープンソース愛好家によって共有される単なるコンテンツではなく、営利企業によってサポートされるオープンソース プロジェクトです。
以下は、HiveDB がデータを編成する方法に関する基本情報を説明している章の写真です。具体的にはあまり多くのアーキテクチャ情報を示すことはできませんが、基本的にはデータ セグメンテーションの面でその独自性を示すことができます。
★ mycat データ統合: 詳細 http://www.songwie.com/articlelist/11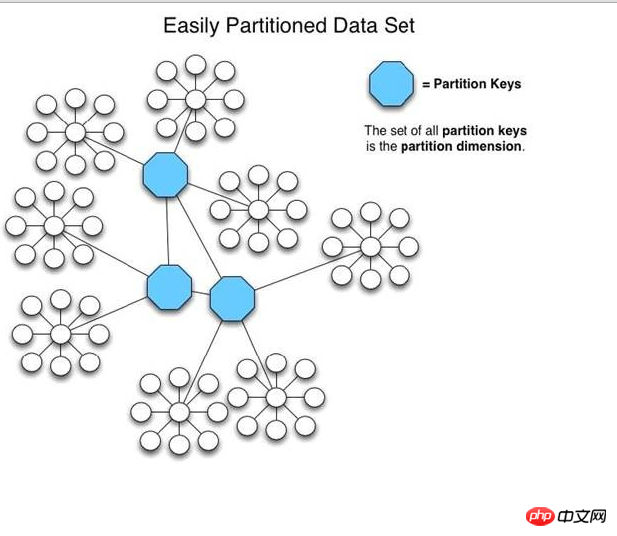 ★ データのセグメント化と統合を実現するその他のソリューション
★ データのセグメント化と統合を実現するその他のソリューション
上記で紹介したいくつかのデータのセグメント化と統合に加えてソリューション全体に加えて、データのセグメント化と統合を提供するソリューションは他にも多数あります。たとえば、HSCALE は MySQLProxy に基づいてさらに拡張されており、SpockProxy は Rails を通じて構築されています。 Pathon ベースの Pyshards なども同様です。
どのソリューションを使用することを選択しても、基本的に全体的な設計のアイデアに変更はありません。それは、データの垂直方向および水平方向のセグメント化を通じてデータベースの全体的なサービス機能を強化し、アプリケーション システム全体のスケーラビリティを可能な限り向上させることです。拡張方法はできるだけ便利です。 bed中間層プロキシアプリケーションを介して私たちのみを置くことで、データセグメンテーションとデータソースの統合の問題をよりよく克服できます。そうすれば、データベースの線形スケーラビリティは、アプリケーションと同様に非常に簡単になります。安価な PCServer サーバーを追加するだけで、データベース クラスターの全体的なサービス容量が直線的に増加するため、データベースがアプリケーション システムのパフォーマンスのボトルネックになりにくくなります。合データカットと統合問題
こちら。誰もがデータのセグメント化と統合の実装について一定の理解を持っている必要があります。おそらく多くの読者や友人は、さまざまなソリューションのそれぞれの特性の長所と短所に基づいて、自分のアプリケーション シナリオに適したソリューションを基本的に選択しているでしょう。その後の作業は主に実装の準備です。
データセグメンテーション計画を実装する前に、考えられるいくつかの問題について分析を行う必要があります。
一般的に、私たちが遭遇する可能性のある主な問題は次のとおりです。
◆ 分散トランザクションの導入の問題。
◆ クロスノード結合の問題;
◆ クロスノードマージのソートとページングの問題。
1. 分散トランザクションの問題の紹介
データが複数の MySQL サーバーに分割されて保存されると、パーティショニング ルールがどれほど完璧に設計されていたとしても (実際には完璧なパーティショニング ルールはありません)、関係するデータが以前の一部のトランザクションでは、同じ MySQL サーバーに存在しなくなりました。
このシナリオでは、アプリケーションが依然として古いソリューションに従っていると仮定します。それを解決するには分散トランザクションを導入する必要があります。 MySQL のさまざまなバージョンのうち、分散トランザクションのサポートを提供し始めているのは MySQL 5.0 以降のバージョンのみであり、現在、分散トランザクションのサポートを提供しているのは Innodb だけです。それだけでなく。たとえ分散トランザクションをサポートする MySQL バージョンを使用していたとしてもです。同時に、Innodbストレージエンジンも使用されており、分散トランザクション自体は多くのシステムリソースを消費し、パフォーマンス自体はそれほど高くありません。そして、分散トランザクションの導入自体も、例外処理の点で制御が困難な要因をさらにもたらします。
どうすればいいですか?実際、この問題は回避策によって解決できます。最初に考慮すべきことは、トランザクションを解決できる唯一の場所はデータベースかどうかということです。実際には、そうではありません。データベースとアプリケーションの両方を組み合わせることで、問題を完全に解決できます。各データベースは独自の処理を行います。次に、アプリケーションを使用して複数のデータベース上のトランザクションを制御します。
つまり。望むなら。複数のデータベースにわたる分散トランザクションを、単一のデータベース上にのみ存在する複数の小さなトランザクションに分割することは完全に可能です。また、アプリケーションを使用してさまざまな小規模トランザクションを制御します。
もちろん、そのための要件は、ロシアのアプリケーションが十分に堅牢である必要があるということです。もちろん、アプリケーションに技術的な問題も発生します。
2. クロスノード結合の問題
上記では、分散トランザクションを引き起こす可能性のある問題を紹介しました。次に、クロスノード結合を必要とする問題を見てみましょう。
データのセグメント化後。これにより、一部の古い Join ステートメントが使用されなくなる可能性があります。 Join で使用されるデータ ソースが複数の MySQL Server に分割される可能性があるためです。
どうすればいいですか? MySQL データベースの観点から見ると、この問題をデータベース側で直接解決する必要がある場合、MySQL の特別なストレージ エンジンである Federated を介してのみ解決できるのではないかと思います。 Federated Storage エンジンは、Oracle の DBLink と同様の問題に対する MySQL のソリューションです。
と OracleDBLink の主な違いは、Federated がリモート表構造の定義情報のコピーをローカルに保存することです。一見したところ、Federated は確かにクロスノード結合に対する非常に優れたソリューションです。ただし、リモート テーブルの構造が変更されても、ローカル テーブルの定義情報はそれに応じて変更されないことも明確にしておく必要があります。リモートテーブルの構造を更新する際、ローカルのFederatedテーブル定義情報は更新されないものとします。クエリ実行エラーが発生し、正しい結果が得られない可能性が非常に高くなります。このような問題を解決するには、やはりアプリケーションを介して処理することをお勧めします。まず、ドライバーが配置されている mysqlserver 内の対応する駆動結果セットを取り出します。次に、ドライバーの結果セットに基づいて、駆動テーブルが配置されている MySQL サーバーから対応するデータを取得します。多くの読者は、これがパフォーマンスに一定の影響を与えると考えるかもしれません。確かに、これはパフォーマンスに一定の悪影響を及ぼしますが、この方法以外に、より良い解決策は基本的にあまりありません。
また、データベースがより適切に拡張されたため、各 MySQL サーバーの負荷をより適切に制御できるようになりました。単一のクエリの場合、セグメント化されない前よりも応答時間が長くなる可能性があるため、パフォーマンスへの悪影響はそれほど大きくありません。言うまでもなく。これと同様のクロスノード結合の要件はそれほど多くありません。全体的なパフォーマンスと比較すると、それはごく一部にすぎない可能性があります。したがって、全体的なパフォーマンスを向上させるために、時々少し犠牲にしてください。実際にそれだけの価値があります。結局のところ、システムの最適化自体は、多くのトレードオフとバランスを伴うプロセスです。
3. クロスノードマージのソートとページングの問題
データが水平に分割されると、クロスノード結合が正常に実行できないだけでなく、ソートとページングのための一部のクエリステートメントのデータソースも実行できない可能性があります。複数のノードに分割することもできます。この直接的な結果は、これらの並べ替えクエリとページング クエリが正常に実行し続けることができなくなることです。実際、これはクロスノード結合と同じです。データ ソースは複数のノードに存在し、クエリを通じて解決する必要があります。これは、クロスノード結合と同じ操作です。同様に、Federated も部分的に解決できます。もちろんリスクもあります。
まだ同じ問題が発生します。どうすればよいですか?私は引き続きアプリケーションを通じて問題を解決することをお勧めします。
どうやって解決しますか?ソリューションの考え方は一般的にクロスノード結合のソリューションと似ていますが、クロスノード結合とは異なる点が 1 つあります。多くの場合、結合はドライバー主導の関係になります。したがって、結合自体に関与する複数のテーブル間のデータ読み取りには、通常、順次的な関係があります。ただし、ソート ページングは異なります。ソート ページングのデータ ソースは、基本的にテーブル (または結果セット) であると言えます。それ自体には順序関係がないため、複数のデータ ソースからデータをフェッチするプロセスは完全に並列化できます。
以上です。ソートされたページング データを取得する場合、データベース間の結合よりも高い効率を実現できます。したがって、発生するパフォーマンスの損失は比較的小さく、場合によっては、データ分割を行わない元のデータベースよりも効率が高くなる可能性があります。
もちろん、クロスノード結合であっても、クロスノードソートやページングであっても。これにより、結果セットの読み取り、アクセス、マージのプロセスで以前よりも多くのデータを処理する必要があるため、アプリケーション サーバーは他のリソース、特にメモリ リソースを大量に消費することになります。
非常にここでの分析は、多くの読者や友人が、上記の問題すべて、私が提示した提案は基本的にアプリケーションを通じて解決されることに気づくかもしれません。誰もが心の中でつぶやき始めているかもしれない。私が DBA であるため、多くのことをアプリケーション アーキテクトや開発者に任せているのでしょうか? 実際、これはまったく当てはまりません。第一に、このアプリケーションはその特殊性によるものです。非常に優れたスケーラビリティを実現するのは非常に簡単ですが、データベースは異なります。拡大は他の多くの方法で達成する必要があります。そして、この拡張プロセスでは、集中型データベースでは解決できても、データベース クラスターに分割すると困難な問題になるという状況を回避することが非常に困難です。 applicationアプリケーションが他の多くのことを行うことを可能にすることにより、システムを最大限に拡張するように作られています。データベースクラスターではうまく解決できない問題を解決する。 概要 データ セグメンテーション テクノロジーを使用して大規模な MySQLServer を複数の小さな MySQLServer に分割すると、書き込みパフォーマンスのボトルネック問題が克服されるだけでなく、データベース クラスター全体のスケーラビリティも再び向上します。垂直セグメンテーションまたは水平セグメンテーションを通じて。これらすべてにより、システムがボトルネックに遭遇する可能性が低くなります。特に垂直方向と水平方向のスライス方法を組み合わせて使用すると、理論的には拡張のボトルネックが発生しなくなります。 関連する推奨事項:Mysql データベースのサブデータベースとサブテーブルのメソッド (一般的に使用される)_MySQL
mysql マスター/スレーブ データベース、サブデータベース、サブテーブルのメモ_MySQL
オールドボーイmysql ビデオ: MySQL データベースのマルチインスタンス起動の問題のトラブルシューティング方法と実践的なトラブルシューティング
以上がmysql データベースのサブデータベースとテーブルのサブテーブルにおける技術的問題を解決する戦略の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。