
ホームページ >Java >&#&チュートリアル >JAVA開発におけるアノテーションの基本原理の詳細な分析
JAVA開発におけるアノテーションの基本原理の詳細な分析

- 无忌哥哥オリジナル
- 2018-07-20 10:28:441720ブラウズ
これまで、主要なフレームワークでは「XML」が疎結合方式でフレームワーク内のほぼすべての構成を完了していましたが、プロジェクトが大きくなるにつれて、「XML」の内容はますます複雑になり、必要なものも増えてきました。メンテナンス費用が高くなる。
そこで誰かが、マークされた高度に結合された構成方法「アノテーション」を提案しました。メソッドに注釈を付けることも、クラスに注釈を付けることも、フィールド属性に注釈を付けることもできます。いずれにせよ、設定が必要なほとんどの場所に注釈を付けることができます。
「アノテーション」と「XML」の 2 つの異なる構成モードについては、長年にわたって議論されてきました。アノテーションにはそれぞれ独自の長所と短所がありますが、高度な機能を備えています。結合の場合は XML ですが、注釈の場合はその逆が当てはまります。
低結合の追求は高効率の放棄を意味し、効率の追求は必然的に結合に遭遇します。この記事の目的は、この 2 つを区別することではなく、アノテーションに関連する基本的な内容を最も簡単な言語で紹介することです。
アノテーションの本質
「アノテーション」について説明する「java.lang.annotation.Annotation」インターフェースにはこのような文があります。
The common interface extended by all annotation types 所有的注解类型都继承自这个普通的接口(Annotation)
この文は少し抽象的ですが、アノテーションの本質を表しています。 JDK 組み込みアノテーションの定義を見てみましょう:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}これはアノテーション @Override の定義です。実際、本質的には次のとおりです:
public interface Override extends Annotation{
}はい、アノテーションの本質は、アノテーションを継承するインターフェースです。インターフェース。これに関しては、任意のアノテーション クラスを逆コンパイルすると、結果が得られます。
正確な意味では、アノテーションは特別なアノテーションにすぎません。それを解析するコードがなければ、それはアノテーションにも満たない可能性があります。
多くの場合、クラスまたはメソッドのアノテーションの解析には 2 つの形式があり、1 つはコンパイル時の直接スキャンで、もう 1 つは実行時のリフレクションです。リフレクションについては後ほど説明しますが、コンパイラ スキャンとは、Java コードのバイトコードをコンパイルするプロセス中に、特定のクラスまたはメソッドが何らかのアノテーションによって変更されたことをコンパイラが検出することを意味します。 。
典型的なものは、@Override アノテーションです。コンパイラーは、メソッドが @Override アノテーションで変更されたことを検出すると、現在のメソッドのメソッド シグネチャが実際に親クラスのメソッドをオーバーライドするかどうかを確認します。 、親クラスを比較します。クラスが同じメソッド シグネチャを持つかどうか。
この状況は、JDK のいくつかの組み込みアノテーションなど、コンパイラーにとってすでに馴染みのあるアノテーション クラスにのみ当てはまります。カスタム アノテーションについては、コンパイラーはアノテーションの機能を認識しません。関数がわかりません。多くの場合、これに対処する方法は、アノテーションのスコープに基づいて、それをバイトコード ファイルにコンパイルするかどうかを選択するだけです。
メタアノテーション
「メタアノテーション」は、アノテーションを変更するために使用されるアノテーションであり、通常はアノテーションの定義で使用されます。例:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}これは @Override アノテーションの定義です。@Target を確認できます。 , @ Retention の 2 つのアノテーションは「メタ アノテーション」と呼ばれるものです。 「メタ アノテーション」は、一般的にアノテーションのライフサイクルや対象などの情報を指定するために使用されます。 。 2018 年に最新の 0 の基本的な入門チュートリアルと高度なチュートリアルをまとめました。これらは、Java を追加して q-u-n: 678、241、および 563 を追加することで入手できます。含まれているものは、開発ツールとインストール パッケージです。とシステム学習ロードマップ
JAVA には次の「メタアノテーション」があります:
@Target:注解的作用目标 @Retention:注解的生命周期 @Documented:注解是否应当被包含在 JavaDoc 文档中 @Inherited:是否允许子类继承该注解
その中で、@Target は、変更されたアノテーションが最終的に誰をターゲットにできるかを示すために使用されます。つまり、アノテーションが何に使用されるかを示すために使用されます。改造方法?改造タイプ?フィールド属性を変更するためにも使用されます。
@Target は次のように定義されます:
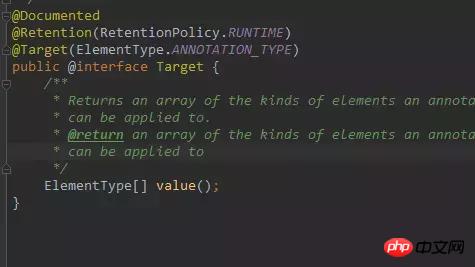
次の方法でこの値に値を渡すことができます:
@Target(value = {ElementType.FIELD})この @Target アノテーションによって変更されたアノテーションはメンバー フィールドにのみ作用し、変更には使用できませんメソッドまたはクラス。このうち、ElementType は次の値を持つ列挙型です。
ElementType.TYPE:允许被修饰的注解作用在类、接口和枚举上 ElementType.FIELD:允许作用在属性字段上 ElementType.METHOD:允许作用在方法上 ElementType.PARAMETER:允许作用在方法参数上 ElementType.CONSTRUCTOR:允许作用在构造器上 ElementType.LOCAL_VARIABLE:允许作用在本地局部变量上 ElementType.ANNOTATION_TYPE:允许作用在注解上 ElementType.PACKAGE:允许作用在包上
@Retention は、現在のアノテーションのライフサイクルを示すために使用されます。その基本的な定義は次のとおりです。
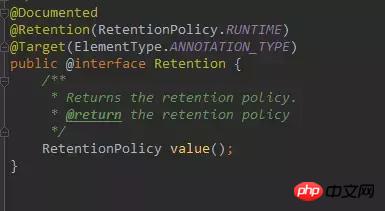
同様に、value 属性もあります。 :
@Retention(value = RetentionPolicy.RUNTIME
ここでの RetentionPolicy はまだ列挙型です。次の列挙値があります:
RetentionPolicy.SOURCE:当前注解编译期可见,不会写入 class 文件 RetentionPolicy.CLASS:类加载阶段丢弃,会写入 class 文件 RetentionPolicy.RUNTIME:永久保存,可以反射获取
@Retention アノテーションは、コンパイル中にのみ表示され、コンパイル後に表示されます。クラス、メソッド、またはフィールドのいずれであっても、コンパイラによってクラス ファイルにコンパイルされます。これらはすべて属性テーブルを持ち、JAVA 仮想マシンもアノテーション情報を保存するためにいくつかのアノテーション属性テーブルを定義します。可視性をメソッド領域に持ち込むことはできず、クラスがロードされるときに破棄されます。最後の可視性は永続的な可視性です。
剩下两种类型的注解我们日常用的不多,也比较简单,这里不再详细的进行介绍了,你只需要知道他们各自的作用即可。@Documented 注解修饰的注解,当我们执行 JavaDoc 文档打包时会被保存进 doc 文档,反之将在打包时丢弃。@Inherited 注解修饰的注解是具有可继承性的,也就说我们的注解修饰了一个类,而该类的子类将自动继承父类的该注解。
JAVA 的内置三大注解
除了上述四种元注解外,JDK 还为我们预定义了另外三种注解,它们是:
@Override
@Deprecated
@SuppressWarnings
@Override 注解想必是大家很熟悉的了,它的定义如下:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}它没有任何的属性,所以并不能存储任何其他信息。它只能作用于方法之上,编译结束后将被丢弃。
所以你看,它就是一种典型的『标记式注解』,仅被编译器可知,编译器在对 java 文件进行编译成字节码的过程中,一旦检测到某个方法上被修饰了该注解,就会去匹对父类中是否具有一个同样方法签名的函数,如果不是,自然不能通过编译。
@Deprecated 的基本定义如下:
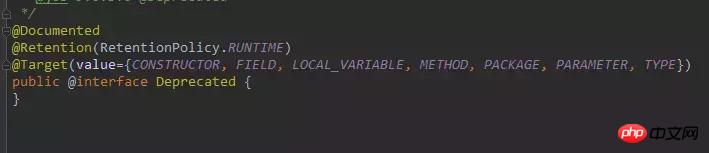
依然是一种『标记式注解』,永久存在,可以修饰所有的类型,作用是,标记当前的类或者方法或者字段等已经不再被推荐使用了,可能下一次的 JDK 版本就会删除。
当然,编译器并不会强制要求你做什么,只是告诉你 JDK 已经不再推荐使用当前的方法或者类了,建议你使用某个替代者。
@SuppressWarnings 主要用来压制 java 的警告,它的基本定义如下:
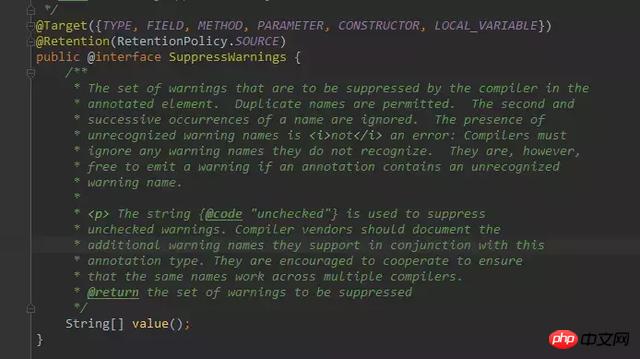
它有一个 value 属性需要你主动的传值,这个 value 代表一个什么意思呢,这个 value 代表的就是需要被压制的警告类型。例如:
public static void main(String[] args) {
Date date = new Date(2018, 7, 11);
}这么一段代码,程序启动时编译器会报一个警告。
Warning:(8, 21) java: java.util.Date 中的 Date(int,int,int) 已过时
而如果我们不希望程序启动时,编译器检查代码中过时的方法,就可以使用 @SuppressWarnings 注解并给它的 value 属性传入一个参数值来压制编译器的检查。
@SuppressWarning(value = "deprecated")
public static void main(String[] args) {
Date date = new Date(2018, 7, 11);
}这样你就会发现,编译器不再检查 main 方法下是否有过时的方法调用,也就压制了编译器对于这种警告的检查。
当然,JAVA 中还有很多的警告类型,他们都会对应一个字符串,通过设置 value 属性的值即可压制对于这一类警告类型的检查。
自定义注解的相关内容就不再赘述了,比较简单,通过类似以下的语法即可自定义一个注解。
public @interface InnotationName{
}当然,自定义注解的时候也可以选择性的使用元注解进行修饰,这样你可以更加具体的指定你的注解的生命周期、作用范围等信息。
注解与反射
上述内容我们介绍了注解使用上的细节,也简单提到,「注解的本质就是一个继承了 Annotation 接口的接口」,现在我们就来从虚拟机的层面看看,注解的本质到底是什么。
首先,我们自定义一个注解类型:
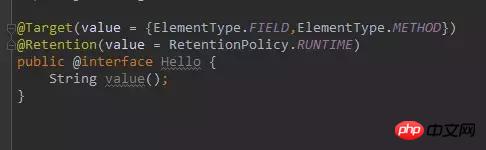
这里我们指定了 Hello 这个注解只能修饰字段和方法,并且该注解永久存活,以便我们反射获取。
之前我们说过,虚拟机规范定义了一系列和注解相关的属性表,也就是说,无论是字段、方法或是类本身,如果被注解修饰了,就可以被写进字节码文件。属性表有以下几种:
RuntimeVisibleAnnotations:运行时可见的注解 RuntimeInVisibleAnnotations:运行时不可见的注解 RuntimeVisibleParameterAnnotations:运行时可见的方法参数注解 RuntimeInVisibleParameterAnnotations:运行时不可见的方法参数注解 AnnotationDefault:注解类元素的默认值
给大家看虚拟机的这几个注解相关的属性表的目的在于,让大家从整体上构建一个基本的印象,注解在字节码文件中是如何存储的。
所以,对于一个类或者接口来说,Class 类中提供了以下一些方法用于反射注解。
getAnnotation:返回指定的注解 isAnnotationPresent:判定当前元素是否被指定注解修饰 getAnnotations:返回所有的注解 getDeclaredAnnotation:返回本元素的指定注解 getDeclaredAnnotations:返回本元素的所有注解,不包含父类继承而来的
方法、字段中相关反射注解的方法基本是类似的,这里不再赘述,我们下面看一个完整的例子。
首先,设置一个虚拟机启动参数,用于捕获 JDK 动态代理类。
-Dsun.misc.ProxyGenerator.saveGeneratedFiles=true
然后 main 函数。
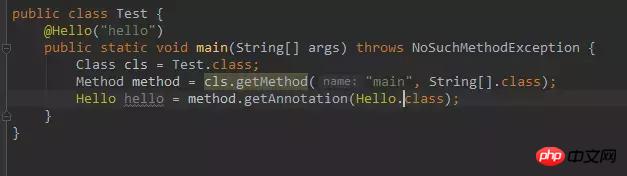
我们说过,注解本质上是继承了 Annotation 接口的接口,而当你通过反射,也就是我们这里的 getAnnotation 方法去获取一个注解类实例的时候,其实 JDK 是通过动态代理机制生成一个实现我们注解(接口)的代理类。
プログラムを実行すると、出力ディレクトリにこのようなプロキシ クラスが表示されます。逆コンパイルすると、次のようになります。
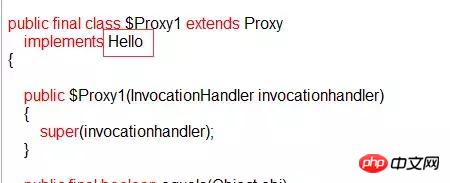

このプロキシ クラスは、インターフェイス Hello を実装して書き換えます。 Annotation インターフェースから継承された value メソッドとインターフェース Hello メソッドを含む、そのすべてのメソッド。
そして、この主要な InvocationHandler インスタンスは誰でしょうか?
AnnotationInvocationHandler は、JAVA でアノテーションを処理するために特に使用されるハンドラーです。このクラスの設計も非常に興味深いものです。
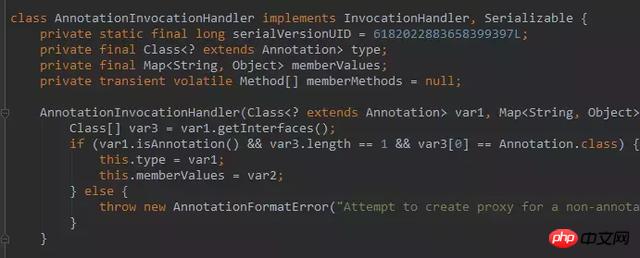
ここには、Map のキーと値のペアである memberValues があります。キーはアノテーション属性の名前で、値は属性に割り当てられた値です。
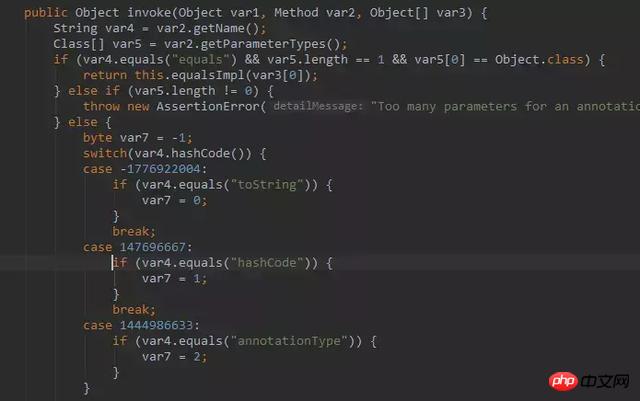

そして、この呼び出しメソッドは非常に興味深いものです。プロキシ クラスは Hello インターフェイス内のすべてのメソッドをプロキシするため、プロキシ クラス内のメソッドの呼び出しはここに転送されることに注意してください。
var2 は呼び出されるメソッドのインスタンスを指します。ここでは、まず変数 var4 を使用してメソッドの簡潔な名前を取得し、次に switch 構造を使用して、現在の呼び出しメソッドが 4 つの主要なメソッドの 1 つであるかどうかを判断します。 Annotation のメソッドでは、var7 を特定の値に割り当てます。
現在呼び出されるメソッドが toString、equals、hashCode、annotationType の場合、これらのメソッドの実装は AnnotationInvocationHandler インスタンスで事前定義されているため、直接呼び出すことができます。
そして、var7 がこれら 4 つのメソッドと一致しない場合は、現在のメソッドが、Hello アノテーションの value メソッドなど、カスタム アノテーション バイトによって宣言されたメソッドを呼び出すことを意味します。 この場合、このアノテーション属性に対応する値はアノテーション マップから取得されます。
実際、JAVA のアノテーションの設計は少し反人間的であると個人的に感じています。これは明らかに属性操作であり、メソッドを使用して実装する必要があります。もちろん、異なる意見がある場合は、メッセージを残して議論してください。
最後に、リフレクション アノテーション全体の動作原理をまとめてみましょう:
まず、次のように、キーと値のペアの形式でアノテーション属性に値を割り当てることができます: @Hello (value = "hello ")。
次に、アノテーションを使用して要素を変更します。コンパイラは、コンパイル中に各クラスまたはメソッドのアノテーションをスキャンし、現在の位置にアノテーションを適用できるかどうかを確認します。注釈は次のようになります。情報は要素の属性テーブルに書き込まれます。
その後、リフレクションを実行すると、仮想マシンは RUNTIME ライフサイクル内のすべてのアノテーションを取り出してマップに配置し、AnnotationInvocationHandler インスタンスを作成して、それにマップを渡します。
最後に、仮想マシンは JDK 動的プロキシ メカニズムを使用して、ターゲット アノテーション付きプロキシ クラスを生成し、プロセッサを初期化します。
このようにして、本質的にはプロキシ クラスであるアノテーション インスタンスが作成されます。コアとなる AnnotationInvocationHandler の呼び出しメソッドの実装ロジックを理解する必要があります。一文で言えば、 はメソッド名を通じてアノテーション属性値 を返します。
以上がJAVA開発におけるアノテーションの基本原理の詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- 適切なバージョン化と依存関係管理を備えたカスタムJavaライブラリ(JARファイル)を作成および使用するにはどうすればよいですか?
- Javaのクラスロードメカニズムは、さまざまなクラスローダーやその委任モデルを含むどのように機能しますか?
- キャッシュや怠zyなロードなどの高度な機能を備えたオブジェクトリレーショナルマッピングにJPA(Java Persistence API)を使用するにはどうすればよいですか?
- カフェインやグアバキャッシュなどのライブラリを使用して、Javaアプリケーションにマルチレベルキャッシュを実装するにはどうすればよいですか?
- 高度なJavaプロジェクト管理、自動化の構築、依存関係の解像度にMavenまたはGradleを使用するにはどうすればよいですか?