
ホームページ >データベース >mysql チュートリアル >エディターでは、SQL Server インデックスの原則を詳細に分析します。
エディターでは、SQL Server インデックスの原則を詳細に分析します。

- 无忌哥哥オリジナル
- 2018-07-12 14:11:262260ブラウズ
実際、インデックスを特別なディレクトリとして理解するには、次の記事で主に SQL Server インデックスの原理に関する関連情報をサンプル コードを通じて詳しく紹介しており、皆さんの学習に非常に役立ちます。特定の参照と学習価値がありますので、必要な方は編集者をフォローして一緒に学んでください
この記事は、議論の入り口として私の以前のメモを編集したものです。関連するデータベースの知識 (理解しやすいように変更されています)。しばらく SQL Server を使用したことがない友人は、次の 青 フォントの単語を読むだけで十分です。これはシンプルで時間の節約に役立ちます。優れたデータベース基盤を持っている友人であれば、すべて読んで議論することもできます。 。
インデックスの概念
インデックスの目的: データのクエリと処理速度は、アプリケーション システムの成功または失敗を測定する基準になっており、データ処理を高速化するためにインデックスを使用することが通常最も一般的に使用されます。最適化手法。
インデックスとは: データベースのインデックスは本の目次に似ており、本の目次を使用すると、本全体を読まなくても必要な情報をすぐに見つけることができます。データベースでは、データベース プログラムはインデックスを使用して、テーブル全体をスキャンすることなくテーブル内のデータを取得します。本の目次は単語と各単語が掲載されているページ番号のリストであり、データベースのインデックスはテーブル内の値のリストと各値の格納場所です。
インデックスの長所と短所: クエリ実行のオーバーヘッドのほとんどは I/O であり、インデックスを使用してパフォーマンスを向上させる主な目的の 1 つは、テーブル全体のスキャンを回避することです。これは、テーブル全体のスキャンではテーブルのすべてのデータ ページを読み取る必要があるためです。がある場合、インデックスはデータ値を指すため、クエリはディスクを数回読み取るだけで済みます。したがって、インデックスを適切に使用すると、データ クエリを高速化できます。ただし、インデックスによって常にシステムのパフォーマンスが向上するとは限りません。インデックス付きテーブルでは、データの追加と削除に使用される同じコマンドの実行に時間がかかり、インデックスの維持に必要な処理時間が長くなります。したがって、インデックスを合理的に使用し、適時に更新して最適でないインデックスを削除する必要があります。
1. クラスタードインデックスとノンクラスタードインデックス
インデックスはクラスタードインデックスとノンクラスタードインデックスに分かれています
1.1 クラスタードインデックス
テーブルのデータはデータページに格納されます(データ ページの PageType は 1 とマークされています)、SqlServer の 1 ページは 8k で、1 ページがいっぱいになると、ストレージの次のページが開かれます。 テーブルにクラスター化インデックスがある場合、物理データはクラスター化インデックスのフィールドのサイズに応じて昇順/降順でページに 1 つずつ格納されます。クラスタ化インデックスのフィールドが更新されたり、途中でデータが挿入/削除されたりすると、昇順/降順の並べ替えを維持する必要があるため、テーブル データが移動されます (パフォーマンスに一定の影響を及ぼします)。
主キーはデフォルトではクラスター化インデックスのみであることに注意してください。非クラスター化インデックスとして設定することも、テーブル全体に対してのみクラスター化インデックスとして設定することもできます。クラスタ化インデックスが 1 つあります。
(D). 小さいフィールド長
クラスター化インデックスのキーの長さが小さいほど、1 つのインデックス ページに多くのインデックス レコードを収容できるため、インデックス B ツリー構造の深さが減ります。たとえば、数百万のレコードを持つテーブルには int クラスター化インデックスがあり、3 レベルの B ツリー構造のみが必要な場合があります。クラスター化インデックスがより幅の広い列に定義されている場合 (たとえば、uniqueidentifier 列には 16 バイトが必要です)、インデックスの深さは 4 レベルに増加します。クラスター化インデックスのルックアップには、わずか 3 つの I/O 操作ではなく、4 つの I/O 操作 (正確には 4 つの論理読み取り) が必要です。
同様に、非クラスター化インデックスにはクラスター化インデックスのキー値が含まれます。クラスター化インデックスのキーの長さが小さいほど、1 つの非クラスター化インデックス レコードに収容できるインデックス レコードの数は小さくなります。
1.2 非クラスター化インデックス
もページに格納されます (PageType 2 でマークされたページはインデックス ページと呼ばれます)。 たとえば、テーブル T に非クラスター化インデックス Index_A が設定されています。テーブル T に 100 個のデータがある場合、インデックス Index_A にも 100 個のデータ (正確には 100 個のリーフ ノード データ) が含まれます。インデックスは B です。 -tree 構造。ツリーの高さが 0 より大きい場合、ルート ノード ページまたは中間ノード ページ データがあり、この時点でインデックス データが 100 を超えている場合)、テーブル T にも非クラスター化インデックス Index_B がある場合、 Index_B にも少なくとも 100 個のデータがあるため、インデックスの構築にかかるオーバーヘッドが大きくなります。
インデックスフィールドの更新、データの挿入、またはデータの削除を行うと、インデックスのメンテナンスが発生し、パフォーマンスに一定の影響を与えます。 状況が異なれば、パフォーマンスへの影響も異なります。たとえば、クラスター化インデックスがある場合、挿入されたデータはすべて最後にあり、データの移動が発生することはほとんどありませんが、挿入されたデータが中央にある場合は、通常、データの移動が発生する可能性があります。ページングと断片化が発生すると、影響は若干大きくなります (挿入された中間ページに、挿入されたデータを収容するのに十分な空き領域があり、その位置がページの最後にある場合、データの移動は発生しません)
2. インデックス構造
SqlServer のインデックスは B-tree 構造であると言われています (B-tree 構造についてはある程度理解していることが前提です)。 SQL ステートメントを使用して、その論理表現を表示できます。
新しいクエリ実行構文: DBCC IND(Test,OrderBo,-1) -- Test ライブラリの OrderBo テーブルには 10,000 個のデータがあり、クラスター化インデックス ID の主キー フィールドがあります
(自分でテーブルを作成し、クラスタリングインデックスフィールドを使用して、10,000 のテーブルデータを挿入し、この構文を実行して確認してください。多くのことが得られます。一度確認することをお勧めします)
実行結果:
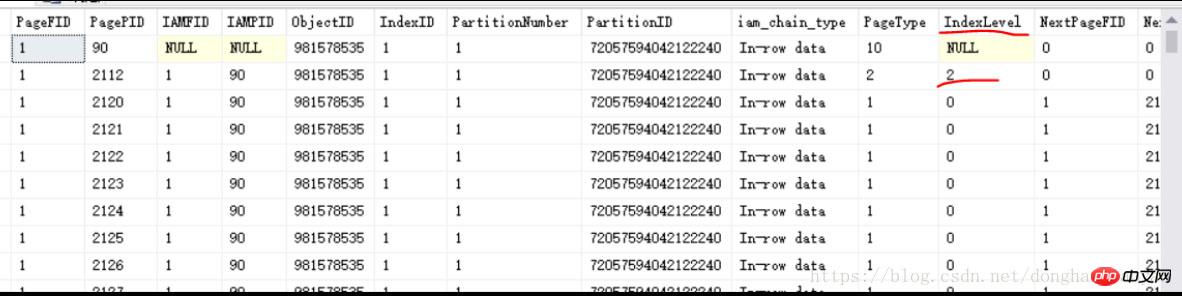
上に示すようにIndexLevel=2 2112 のインデックス ページが表示されます (ここでは、B ツリーのルート ノードです。最大の IndexLevel がルート ノードであり、その下にサブレベル、サブサブレベルがあります...これは、IndexLevel=1 のインデックス ページと IndexLevel=0 のリーフ ページが存在する必要があることを示します。クラスタードインデックスなので、IndexLevel=0のときのリーフページがデータページとなり、物理データを1つずつ格納します。上の図からわかるように、IndexLevel=0 の行の PageType は 1 に等しく、これは上記の第 1.1 章でクラスタード インデックスについて説明するときに、PageType=1 についても言及されています。は非クラスター化インデックスであり、 IndexLevel=0 のリーフ ページ、 PageType は 2 に等しく、依然としてインデックス ページです。
同様に、SQL コマンド DBCC PAGE を使用して調べます
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

上に示すように、IndexLevel=2 のページ 2112 には、IndexLevel=1 の 2 つの子ノード 2280 と 2448 があります。ノードの下にはサブノードがあり、各ノードはさまざまなインデックス キー値の範囲を担当します (つまり、上図の「Id (キー)」フィールド、最初の行の値は Null であることを示します)最小値または最大値の逆順)。このような階層関係は B ツリー構造ですか。IndexLevel は実際には B ツリー構造の高さです。
SqlServer がインデックス内の特定のレコードを検索すると、すべてのデータ アドレスにリーフ ノードがあるため、ルート ノードから下方向にリーフ ノードが見つかります。これは実際には B+ ツリーの特性の 1 つです (B の特性)。ツリーは、非リーフ ノードで値が見つかった場合に、その値を直接返すことができます。これを確認するには、統計 io をオンに設定してから、統計をオンにします。論理読み取りの数を参照してください)。
リーフ ノードは確実に見つかるため、列を含むインデックスはリーフ ノードでのみ記録する必要があります。つまり、非リーフ ノードの列を含むインデックスは記録されません。「列を含むインデックス」については、以下の第 3 章を参照してください。 」。
B+ ツリーのこの機能 (すべてのデータ アドレスにリーフ ノードがある) は、value1 と value2 (リーフ ノードで) を見つけてそれらを文字列に結合する限り、value1 と value2 の間の間隔クエリにも役立ちます。望ましい結果が得られます。
SqlServer のインデックス構造は B+ ツリーに似ており、最終的には B ツリーと B+ ツリーのハイブリッド バージョンであり、データ構造は必ずしも純粋な B ツリーである必要はありません。純粋なB+ツリー。
3. インデックスに列が含まれるとブックマーク検索
インデックスといえば、SqlServer2005 以降に追加された、非常に実用的な「インデックスに列が含まれる」機能について説明します。
たとえば、大規模なレポートのデータをクエリする場合、where 条件ではインデックス フィールド Name2 が使用されますが、このとき選択されるフィールドは Name1 です。このとき、「インデックスを含む列」を使用して、Name1 をレポートに含めることができます。インデックス フィールド Name2 により、クエリのパフォーマンスが大幅に向上します。
構文: Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
次に、インデックス包含列によってパフォーマンスが大幅に向上する理由を分析します。引き続き DBCC PAGE コマンドを使用して、列を含むインデックス データを持つ非クラスター化インデックスを表示します。

上の図からわかるように、含まれる列 Name1 もインデックス データに格納されています。したがって、データベースがインデックス フィールド Name2 を使用して検索対象の特定の行を見つける場合、RID に基づいてデータ ページ内で Name1 の値を見つける必要がなく、Name1 の値を直接返すことができます (上の図は [HEAP RID ( Key)] 列) 値を取得するため、ブックマークの検索が軽減されます。もちろん、クエリによって返されるデータが 1 つだけで、ブックマーク検索が 1 つだけである場合は問題ありません。クエリによって返されるデータが大きい場合は、データ ページに移動して 1,000 件のデータを取得する必要があります。レコードは 1,000 件のブックマーク検索を意味します。このとき、「インデックスに列が含まれる」という値が大きく反映され、パフォーマンスの消費が非常に大きくなることが想像できます。
ブックマーク検索に関しては、テーブルにクラスター化インデックス(Idなど)がある場合、クラスター化インデックスのキーIdを使ってselect Name1 from Table1 where Id=1を実行して検索するのと似ています(検索方法はインデックス ID の B ツリー構造検索。テーブルにクラスター化インデックスがない場合、検索はデータ行ポインター (「ファイル番号 2 バイト: ページ番号 4 バイト: スロット番号 2 バイト」で構成される) に基づいて行われます。クラスター化インデックス キーと行ポインターは、一般に RID (行 ID) ポインターと呼ばれます。ここから、次のように考えることができます。 テーブルに適切なクラスター化インデックス フィールドがない場合は、自己成長する ID フィールドをクラスター化インデックスの主キーとして使用することをお勧めします (冗長な ID フィールドも許容されます)。自己成長性、不変性、一意性と一貫性があり、長さが短いという特徴は、クラスター化インデックスに適しています。
特殊な場合には、特定のニーズに応じて、自己増加 ID が適用されます。また、自己増加 ID には考慮すべき欠陥があり、大量のデータを含むレコードをテーブルに同時に挿入する場合、各スレッドが最後のページまで挿入する必要があり、競合や待機が発生することが考えられます。この状況を解決するには、uniqueidentifier タイプのフィールド (16 バイト。使用はお勧めしません) またはハッシュ パーティショニング (つまり、1 つのテーブルが複数のテーブルに分割されます。ビッグ データ処理ではデータベースとテーブルを分割するのが通常です) を使用できます。 、など。ただし、シンプルで安定した効率的な自己増加 ID メソッドを維持するために、最初に挿入効率を最適化し (挿入パフォーマンス自体は非常に高速です)、1 秒あたりの同時挿入数が実稼働環境を満たしているかどうかをテストすることをお勧めします。
自己増加 ID は、必ずしもデータベースによって提供される自己増加 ID を使用することを意味するわけではありません。同時に使用できる一意の ID を生成する独自のアルゴリズムを作成することもできます (この場合、一般的な長さは bitint です)。この場合、適切なシナリオは、分散データベースでのマスター/スレーブ レプリケーション中に ID フィールドが間違ってはいけない状況です (マスター/スレーブ レプリケーションの一般的なモードでは、マスター データベースの ID が増加します)。マスター データベースに応じて増加し、マスターとスレーブのレプリケーションが同期しない原因となるデッドロックまたはその他の理由がある場合、スレーブ データベースの ID もスレーブ データベース自体に応じて増加します。ライブラリの ID は増加するため、メイン ライブラリの ID と一致しなくなります)。自己増加 ID が冗長主キーの場合、マスター/スレーブ データベース ID がその番号と一致しなくても影響はありません。
さらに、上の図の最後の列 [行サイズ] は、インデックス列またはインデックスを含む列のサイズが長すぎてはいけないことも示しています。そうしないと、1 つのページに複数のレコードを収容できなくなります。インデックス ページの数が増加し、インデックス データが占有するスペースも大幅に増加しました。
以上がエディターでは、SQL Server インデックスの原則を詳細に分析します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。