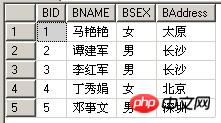
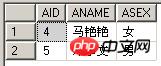
テーブル A の例: TableIn | テーブル B の例: TableEx |

|
|
(1)。サブクエリで NULL を使用しても、結果セット
select * from TableIn where exists(select null)
等同于: select * from TableIn
が返されます (2)。両方のクエリが同じ結果を返すことに注意してください。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME in(select BNAME from TableEx)
(3) EXISTS と = ANY を使用してクエリを比較します。両方のクエリが同じ結果を返すことに注意してください。
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME)
select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS は EXISTS の正反対のことを行います。サブクエリが行を返さない場合、NOT EXISTS の WHERE 句は満たされます。
結論:
EXISTS (NOT EXISTS を含む) 句の戻り値は BOOL 値です。 EXISTS 内にサブクエリ ステートメント (SELECT ... FROM...) があり、これを EXIST の内部クエリ ステートメントと呼びます。その中のクエリ ステートメントは結果セットを返します。 EXISTS 句は、その中のクエリ ステートメントの結果セットが空か空ではないかに基づいてブール値を返します。
これを理解する一般的な方法は次のとおりです。テストとして、外部クエリ テーブルの各行を内部クエリに代入します。内部クエリから返された結果が null 以外の値を取る場合、EXISTS 句は TRUE を返し、この行は返されます。外部クエリの結果行として使用できます。それ以外の場合は結果として使用できません。
アナライザーはまずステートメントの最初の単語を調べ、最初の単語が SELECT キーワードであることを検出すると、FROM キーワードにジャンプし、FROM キーワードを通じてテーブル名を検索し、テーブルをメモリにロードします。 。次のステップでは、WHERE キーワードが見つからない場合は SELECT に戻り、WHERE が見つかった場合はその中の条件を分析します。フィールドを分析します。最後に、仮想テーブルが形成される。
WHEREキーワードに続くのは条件式です。条件式が計算されると、非ゼロまたは 0 の戻り値が返されます。非ゼロは真 (真) を意味し、0 は偽 (偽) を意味します。同様に、WHERE の後の条件にも戻り値 (true または false) があり、次に SELECT を実行するかどうかを決定します。
アナライザーは最初にキーワード SELECT を見つけ、次に FROM キーワードにジャンプして STUDENT テーブルをメモリにインポートし、ポインターを介して最初のレコードを見つけて、次に WHERE キーワードを見つけてその条件式を計算します。それが true の場合、このレコードは仮想テーブルにロードされ、ポインタは次のレコードを指します。 false の場合、ポインタは他の操作を実行せずに次のレコードを直接指します。常にテーブル全体を取得し、取得した仮想テーブルをユーザーに返します。 EXISTS は条件式の一部であり、戻り値 (true または false) も持ちます。
レコードを挿入する前に、レコードが既に存在するかどうかを確認する必要があります。レコードが存在しない場合にのみ挿入操作が実行されます。EXISTS 条件ステートメントを使用すると、重複レコードの挿入を防ぐことができます。
TableIn (ANAME,ASEX) に挿入
TableIn からトップ 1 'Zhang San'、'Mr' を選択
存在しない場所 (TableIn.AID = 7 の TableIn から * を選択)
EXISTS および IN の使用効率の問題、通常の場合状況では、IN はインデックスを使用しないため、exists を使用する方が効率的ですが、具体的な使用方法は実際の状況によって異なります。
IN は、外側の表面が大きく、内側のテーブルが小さい場合に適しています。外側の表面が小さく、内側のテーブルが大きい状況。
in、not in、exists、notexists の違い:
まず in とexistes の違いについて話しましょう: exists: サブクエリが続き、サブクエリが数値を返す場合行数が存在する場合は true を返します。
select * from class where names (select'x"form stu where stu.cid=class.cid)
クエリ効率の観点からinとexistsを比較すると、inクエリの効率はexists
existsのクエリ効率よりも高速です(xxxxx) 次のサブクエリは相関サブクエリと呼ばれます。これはリストの値を返しません
単に true または false の結果を返します (これが、サブクエリが「x」を選択する理由です。もちろん、これも使用できます
)。
何でも選択) つまり、括弧内のデータが見つかるかどうか、およびそのようなレコードが存在するかどうかのみを考慮します。
その動作方法は、メインクエリを一度実行し、サブクエリで対応する結果をクエリすることです。存在する場合、それが true を返す場合は出力されます
。それ以外の場合は、false を返す場合は出力されます。実行シーケンスは次のとおりです。 1. まず、サブクエリを 1 回実行します。外部クエリの各行であり、サブクエリが実行されるたびに参照されます。 外部クエリで
のときに進む値。
3. サブクエリの結果を使用して、外側のクエリの結果セットを決定します。 外側のクエリが 100 行を返す場合、SQL はクエリを 101 回実行します (外側のクエリに対して 1 回、次に外側のクエリによって返される各行に対して 1 回)
。
in: すべての女の子と同じ年齢の男の子に対するクエリが含まれていますselect * from stu where sex='male' and age in (select age from stu where sex=' Female')in( ) サブクエリは結果セットを返します。つまり、サブクエリは最初に結果セットを生成し、次にメイン クエリがその結果セットにアクセスして要件を満たすフィールドのリストを検索します。要件を満たす出力。それ以外の場合は出力されません。
not in と not存在する場合の違い:
not in は、サブクエリの select キーワードの後のフィールドにnot null 制約がある場合、またはそのようなヒントがある場合は、not in を使用します。メインクエリのテーブルが大きく、サブクエリのテーブルが小さいがレコードが多い場合は、not in を使用する必要があります。例:学生がいないクラスをクエリします。 cid が入っていないクラスから * を選択します (stu から個別の cid を選択します) テーブルに cid に null 値がある場合、not in は null 値を処理しません
解決策: select * from class
where cid not in
(cid が null ではない stu から個別の cid を選択します)
not in の実行順序は次のとおりです。テーブル (各レコードを照会) 要件が満たされている場合は、結果セットが返されます。要件を満たしていない場合は、テーブル内のレコードの照会が完了するまで次のレコードの照会を続けます。つまり、見つからないことを証明するには、すべてのレコードをクエリすることによってのみ証明できます。インデックスは使用されません。 存在しない: メインクエリテーブルにレコードがほとんどなく、サブクエリテーブルに多数のレコードがあり、インデックスがある場合。
例: 生徒がいないクラスをクエリするには、select * from class2
存在しない場所
(stu1 where stu1.cid =class2.cid)
not exists的执行顺序是:在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。
之所以要多用not exists,而不用not in,也就是not exists查询的效率远远高与not in查询的效率。
实例:
exists,not exists的使用方法示例,需要的朋友可以参考下。
学生表:create table student
(
id number(8) primary key,
name varchar2(10),deptment number(8)
)
选课表:create table select_course
(
ID NUMBER(8) primary key,
STUDENT_ID NUMBER(8) foreign key (COURSE_ID) references course(ID),
COURSE_ID NUMBER(8) foreign key (STUDENT_ID) references student(ID)
)
课程表:create table COURSE
(
ID NUMBER(8) not null,
C_NAME VARCHAR2(20),
C_NO VARCHAR2(10)
)
student表的数据:
ID NAME DEPTMENT_ID
---------- --------------- -----------
1 echo 1000
2 spring 2000
3 smith 1000
4 liter 2000
course表的数据:
ID C_NAME C_NO
---------- -------------------- --------
1 数据库 data1
2 数学 month1
3 英语 english1
select_course表的数据:
ID STUDENT_ID COURSE_ID
---------- ---------- ----------
1 1 1
2 1 2
3 1 3
4 2 1
5 2 2
6 3 2
1.查询选修了所有课程的学生id、name:(即这一个学生没有一门课程他没有选的。)
分析:如果有一门课没有选,则此时(1)select * from select_course sc where sc.student_id=ts.id
and sc.course_id=c.id存在null,
这说明(2)select * from course c 的查询结果中确实有记录不存在(1查询中),查询结果返回没有选的课程,
此时select * from t_student ts 后的not exists 判断结果为false,不执行查询。
SQL> select * from t_student ts where not exists
(select * from course c where not exists
(select * from select_course sc where sc.student_id=ts.id and sc.course_id=c.id));
ID NAME DEPTMENT_ID
---------- --------------- -----------
1 echo 1000
2.查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选),
分析:只要有一个门没有选,即select * from select_course sc where student_id=t_student.id and course_id
=course.id 有一条为空,即not exists null 为true,此时select * from course有查询结果(id为子查询中的course.id ),
因此select id,name from t_student 将执行查询(id为子查询中t_student.id )。
SQL> select id,name from t_student where exists
(select * from course where not exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
2 spring
3 smith
4 liter
3.查询一门课也没有选的学生。(不存这样的一个学生,他至少选修一门课程),
分析:如果他选修了一门select * from course结果集不为空,not exists 判断结果为false;
select id,name from t_student 不执行查询。
SQL> select id,name from t_student where not exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
4 liter
4.查询至少选修了一门课程的学生。
SQL> select id,name from t_student where exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
1 echo
2 spring
3 smith本文介绍了SQL中EXISTS的用法 ,更多相关内容请关注php中文网。
相关推荐:
Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介
Mysql常用基准测试工具
Mysql函数 的相关讲解


 (3) EXISTS と = ANY を使用してクエリを比較します。両方のクエリが同じ結果を返すことに注意してください。
(3) EXISTS と = ANY を使用してクエリを比較します。両方のクエリが同じ結果を返すことに注意してください。