
ホームページ >ウェブフロントエンド >jsチュートリアル >async と enterproxy を使用して同時実行数を制御する方法
async と enterproxy を使用して同時実行数を制御する方法
- 亚连オリジナル
- 2018-06-14 14:53:442588ブラウズ
この記事では、同時実行数を制御するための async と enterproxy の使用に関する関連情報を主に紹介し、サンプル コードを通じて同時実行について詳しく紹介します。学ぶことの大切さ、それを必要とする友人たち、一緒に学んでください。
同時実行性と並列処理について話しましょう
オペレーティング システムにおいて、同時実行性とは、複数のプログラムが開始されて完了するまで実行される期間を指し、これらのプログラムはすべて同時に実行されます。プロセッサ上で実行されますが、プロセッサ上で一度に実行できるプログラムは 1 つだけです。
同時実行性とは、Web サーバーであってもアプリであっても、オペレーティング システムではどこにでも存在し、起動してから実行されるまでの期間内の複数のプログラムを指します。同じプロセスがプロセッサ上で実行され、どの時点でもプロセッサ上で実行されるプログラムは 1 つだけです。多くの Web サイトには同時接続数に制限があるため、リクエストの送信が速すぎると、戻り値が空になるか、エラーが報告されます。さらに、Web サイトによっては、送信する同時接続が多すぎて悪意のあるリクエストを行っていると考えられるため、IP をブロックする場合があります。
並列処理と比較すると、並列処理は、独立した非同期の速度で実行されるプログラムのグループを指します。これは、複数のプログラム (タスク) が時間的に重複することとは異なります。同時にCPUコアを追加することで実現できます。そうです、並列処理により同時にマルチタスクを実現できます
同時実行数を制御するにはenterproxyを使用してください
enterproxyは主にPu Lingdaが貢献したツールであり、イベントベースの考え方に変化をもたらしましたプログラミング、イベント メカニズムを使用して問題を解決する複雑なビジネス ロジックを結合することで、コールバック関数の結合に対する批判が解決され、シリアル待機が並列待機に変わり、複数非同期コラボレーション シナリオでの実行効率が向上します
Enterproxy を使用して番号を制御するにはどうすればよいですか?同時実行の?通常、enterproxy と自家製カウンターを使用しない場合、次の 3 つのソースを取得します:
この深くネストされたシリアル方法
var render = function (template, data) {
_.template(template, data);
};
$.get("template", function (template) {
// something
$.get("data", function (data) {
// something
$.get("l10n", function (l10n) {
// something
render(template, data, l10n);
});
});
});過去のこの深いネスト方法を削除し、通常の書き込み方法は独自のものです カウンタを維持します
(function(){
var count = 0;
var result = {};
$.get('template',function(data){
result.data1 = data;
count++;
handle();
})
$.get('data',function(data){
result.data2 = data;
count++;
handle();
})
$.get('l10n',function(data){
result.data3 = data;
count++;
handle();
})
function handle(){
if(count === 3){
var html = fuck(result.data1,result.data2,result.data3);
render(html);
}
}
})();ここで、enterproxy は、これらの非同期操作が完了したかどうかを管理するのに役立ちます。完了後、取得したデータをパラメーターとして使用します。他の多くのシナリオに必要な API も提供します。この API enterproxy は自分で学習できます
非同期を使用して同時実行数を制御します 送信するリクエストが 40 件ある場合、送信するリクエストが多すぎるため、多くの Web サイトが失敗する可能性があります。同時接続で悪意のあるリクエストを行うと、IP はブロックされます。
そのため、常に同時実行数を制御し、これらの 40 個のリンクをゆっくりとクロールする必要があります。
非同期で mapLimit を使用して、一度に同時実行数を 5 に制御し、一度に 5 つのリンクのみをキャプチャします。
var ep = new enterproxy();
ep.all('data_event1','data_event2','data_event3',function(data1,data2,data3){
var html = fuck(data1,data2,data3);
render(html);
})
$.get('http:example1',function(data){
ep.emit('data_event1',data);
})
$.get('http:example2',function(data){
ep.emit('data_event2',data);
})
$.get('http:example3',function(data){
ep.emit('data_event3',data);
})まず、同時実行とは何か、同時実行の数を制限する必要がある理由、および利用可能な解決策について知る必要があります。次に、ドキュメントにアクセスして API の使用方法を確認できます。 async のドキュメントは、これらの構文を学ぶのに最適な方法です。
データのセットをシミュレートします。ここで返されるデータは false であり、返される遅延はランダムです。
async.mapLimit(arr, 5, function (url, callback) {
// something
}, function (error, result) {
console.log("result: ")
console.log(result);
})次に、async.mapLimit を使用して同時にクロールし、結果を取得します。
var concurreyCount = 0;
var fetchUrl = function(url,callback){
// delay 的值在 2000 以内,是个随机的整数 模拟延时
var delay = parseInt((Math.random()* 10000000) % 2000,10);
concurreyCount++;
console.log('现在并发数是 ' , concurreyCount , ' 正在抓取的是' , url , ' 耗时' + delay + '毫秒');
setTimeout(function(){
concurreyCount--;
callback(null,url + ' html content');
},delay);
}
var urls = [];
for(var i = 0;i<30;i++){
urls.push('http://datasource_' + i)
}シミュレーションは alsotang からの抜粋です
出力を実行すると、次の結果が得られます
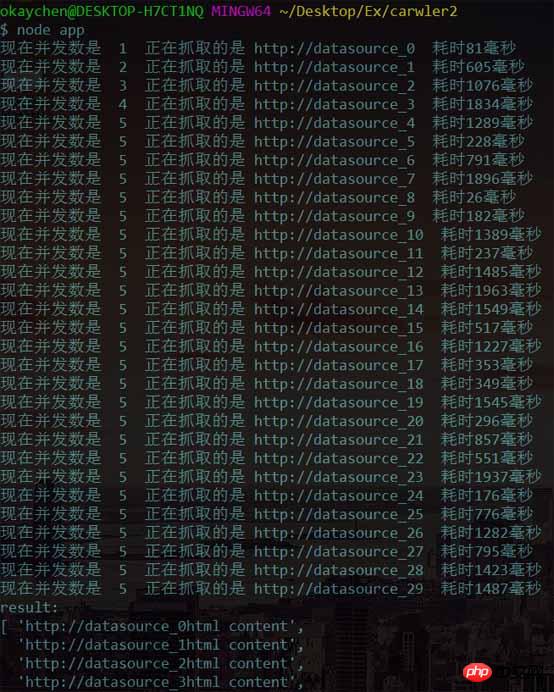 同時実行数は 1 から増加し始めますが、5 に増加すると増加が止まることがわかりました。タスクがある場合はクロールを継続し、同時接続数は常に 5 に制御されます。
同時実行数は 1 から増加し始めますが、5 に増加すると増加が止まることがわかりました。タスクがある場合はクロールを継続し、同時接続数は常に 5 に制御されます。
ノードシンプルクローラシステムを完成させます alsotangシニアによる「ノードティーチングは含まれていません」のチュートリアル例で使用されているeventproxyが同時実行数を制御するため、非同期を使用してノードシンプルクローラシステムを完成させます同時実行の数を制御します。
クロールのターゲットは、この Web サイトのホームページです (手動顔面保護)
最初のステップとして、まず次のモジュールを使用する必要があります:
- url: URL 解析に使用され、ここでは url.resolve( を使用して生成されます) ) 正当なドメイン名
- async: 強力な機能と非同期 JavaScript 作業を提供する実用的なモジュール
- cheerio: サーバー用に特別にカスタマイズされた高速で柔軟な実装された jQuery コア実装
- superagent : A Nodejs の非常に便利なクライアント リクエスト プロキシ モジュール
- npm を介して依存モジュールをインストールします
 2 番目のステップは、require を介して依存モジュールを導入し、クローリング オブジェクトの URL を決定することです:
2 番目のステップは、require を介して依存モジュールを導入し、クローリング オブジェクトの URL を決定することです:
async.mapLimit(urls,5,function(url,callback){
fetchUrl(url,callbcak);
},function(err,result){
console.log('result: ');
console.log(result);
})3 番目のステップ: を使用します。 superagent はターゲット URL をリクエストし、cheerio を使用して BaseUrl を処理してターゲット コンテンツ URL を取得し、それを配列に保存します
var url = require("url");
var async = require("async");
var cheerio = require("cheerio");
var superagent = require("superagent");
var baseUrl = 'http://www.chenqaq.com';必要なのは、キャプチャされた URL オブジェクトを検証する関数だけです。 arr を走査して出力する関数:
function output(arr){
for(var i = 0;i<arr.length;i++){
console.log(arr[i]);
}
}第四步:我们需要遍历得到的URL对象,解析每一个页面需要的信息。
这里就需要用到async控制并发数量,如果你上一步获取了一个庞大的arr数组,有多个url需要请求,如果同时发出多个请求,一些网站就可能会把你的行为当做恶意请求而封掉你的ip
async.mapLimit(arr,3,function(url,callback){
superagent.get(url)
.end(function(err,mes){
if(err){
console.error(err);
console.log('message info ' + JSON.stringify(mes));
}
console.log('「fetch」' + url + ' successful!');
var $ = cheerio.load(mes.text);
var jsonData = {
title:$('.post-card-title').text().trim(),
href: url,
};
callback(null,jsonData);
},function(error,results){
console.log('results ');
console.log(results);
})
})得到上一步保存url地址的数组arr,限制最大并发数量为3,然后用一个回调函数处理 「该回调函数比较特殊,在iteratee方法中一定要调用该回调函数,有三种方式」
callback(null)调用成功callback(null,data)调用成功,并且返回数据data追加到resultscallback(data)调用失败,不会再继续循环,直接到最后的callback
好了,到这里我们的node简易的小爬虫就完成了,来看看效果吧

嗨呀,首页数据好少,但是成功了呢。
参考资料
Node.js 包教不包会 - alsotang
enterproxy
async
async Documentation
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
以上がasync と enterproxy を使用して同時実行数を制御する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。