
ホームページ >バックエンド開発 >Python チュートリアル >Python シミュレートされたログインの複数の方法
Python シミュレートされたログインの複数の方法

- 不言オリジナル
- 2018-06-02 14:46:361829ブラウズ
この記事では主に Python の模擬ログインのさまざまな方法を紹介します。それぞれの方法について詳しく紹介しますので、興味のある方はぜひご覧ください
方法1: 既知の Cookie を直接使用して
にアクセスします 特徴: シンプルですが、最初にブラウザにログインする必要があります 原則:
簡単に言うと、Cookie はリクエストを開始したクライアントに保存されます。サーバーは Cookie を使用してさまざまなクライアントを区別します。 HTTP はステートレス接続であるため、サーバーが複数のリクエストを同時に受信すると、どのリクエストが同じクライアントによって開始されたかを判断できません。 「ログイン後にのみ表示されるページにアクセスする」という動作では、クライアントはサーバーに対して「私はログインしたばかりのクライアントです」ということを証明する必要があります。したがって、クライアントを識別し、その情報 (ログイン ステータスなど) を保存するには Cookie が必要です。
もちろん、これは、別のクライアントの Cookie を取得する限り、そのクライアントのふりをしてサーバーと通信できることも意味します。これは私たちのプログラムにチャンスを与えます。
最初にブラウザでログインし、開発者ツールを使用してCookieを表示します。次に、プログラムに Cookie を組み込んで Web サイトにリクエストを送信すると、プログラムはログインしたばかりのブラウザになりすまして、ログイン後にのみ表示されるページを取得できます。
具体的な手順:
1. ブラウザでログインし、ブラウザで Cookie 文字列を取得します まず、ブラウザを使用してログインします。開発者ツールを再度開き、[ネットワーク]タブに移動します。左側の [名前] 列で現在の URL を見つけ、右側の [ヘッダー] タブを選択して、Web サイトによってブラウザーに発行された Cookie を含むリクエスト ヘッダーを表示します。はい、後ろにある文字列です。これをコピーします。後でコード内で使用します。 プログラムを実行する前にログインすることが最善であることに注意してください。ログインするのが早すぎたり、ブラウザを閉じたりすると、コピーされた Cookie の有効期限が切れてしまう可能性があります。
2. コードを書く urllib ライブラリのバージョン: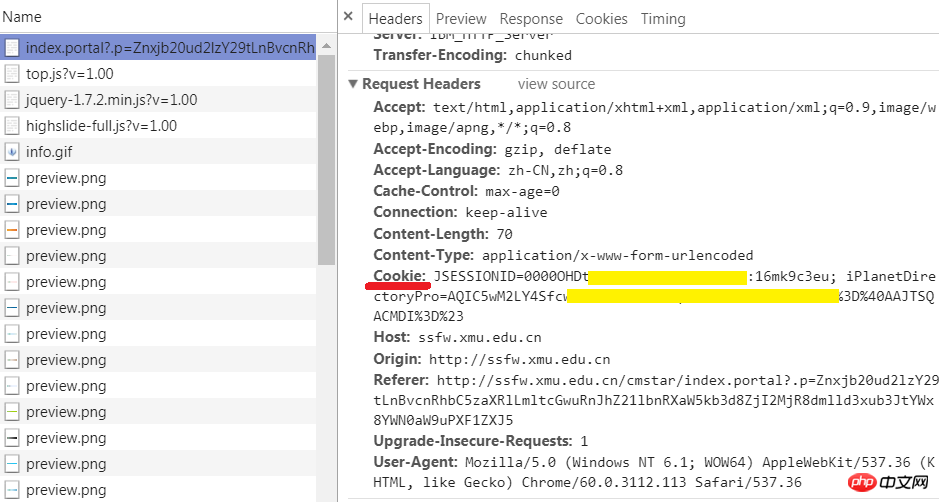
import sys import io from urllib import request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码 #登录后才能访问的网站 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' #浏览器登录后得到的cookie,也就是刚才复制的字符串 cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx' #登录后才能访问的网页 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' req = request.Request(url) #设置cookie req.add_header('cookie', raw_cookies) #设置请求头 req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36') resp = request.urlopen(req) print(resp.read().decode('utf-8'))
リクエスト ライブラリのバージョン:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
方法 2: ログインをシミュレートして実行するクッキーアクセス
原則:
まず、プログラム内の Web サイトにログイン要求を送信します。つまり、ログイン情報 (ユーザー名、パスワードなど) を含むフォームを送信します。応答から Cookie を取得し、今後他のページにアクセスするときにこの Cookie を持参すると、ログイン後にのみ表示されるページを取得できます。 具体的な手順:
1. フォームが送信されるページを確認します 引き続きブラウザの開発者ツールを使用する必要があります。 [ネットワーク] タブに移動し、[ログの保存] をオンにします (重要!)。ブラウザで Web サイトにログインします。次に、左側の [名前] 列でフォームが送信されたページを見つけます。どうやって見つけますか?右側を見て、「ヘッダー」タブに移動します。まず、[全般] セクションで、リクエスト メソッドを POST にする必要があります。次に、下部に「フォーム データ」というセクションがあり、入力したばかりのユーザー名とパスワードが表示されます。左側の名前に「login」という単語が含まれている場合は、それがフォームが送信されたページである可能性があります (必ずしもそうであるとは限りません)。
ここで強調しておきたいのは、「フォームが送信されるページ」は通常、ユーザー名とパスワードを入力するページではないということです。したがって、ツールを使用してそれを見つけてください。 2. 送信するデータを確認します ブラウザにログインするときにユーザー名とパスワードを入力するだけですが、フォームにはそれ以上のデータが含まれています。フォームデータから送信する必要があるすべてのデータを確認できます。
ブラウザにログインするときにユーザー名とパスワードを入力するだけですが、フォームにはそれ以上のデータが含まれています。フォームデータから送信する必要があるすべてのデータを確認できます。
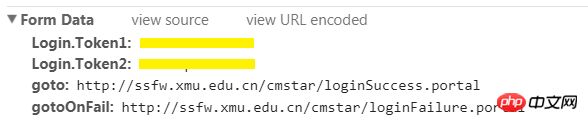
import sys
import io
import urllib.request
import http.cookiejar
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
post_data = urllib.parse.urlencode(data).encode('utf-8')
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = ' http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal
#构造登录请求
req = urllib.request.Request(login_url, headers = headers, data = post_data)
#构造cookie
cookie = http.cookiejar.CookieJar()
#由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
#发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#构造访问请求
req = urllib.request.Request(url, headers = headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))
リクエスト ライブラリのバージョン:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8'))
リクエスト ライブラリの方が使いやすいことは明らかです~~ ~
方法 3: ログインをシミュレートした後、セッションを使用してログインを維持する
原則: セッションとはセッションを意味します。 Cookie と同様に、サーバーがクライアントを「認識」できるようになります。簡単に理解すると、クライアントとサーバー間のすべての対話を「セッション」として扱うことになります。それらは同じ「セッション」内にあるため、サーバーはクライアントがログインしたかどうかを自然に認識します。 具体的な手順:
1. フォームが送信されるページを見つけます
2. 送信されるデータを見つけます
这两步和方法二的前两步是一样的
3.写代码
requests库的版本
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal'
#构造Session
session = requests.Session()
#在session中发送登录请求,此后这个session里就存储了cookie
#可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#发送访问请求
resp = session.get(url)
print(resp.content.decode('utf-8'))
方法四:使用无头浏览器访问
特点:
功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。在Python中可以使用Selenium库来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,但最常用的还是PhantomJS这个无头(没有界面)浏览器。也就是说,只要把填写用户名密码、点击“登录”按钮、打开另一个网页等操作写到程序中,PhamtomJS就能确确实实地让你登录上去,并把响应返回给你。
具体步骤:
1.安装selenium库、PhantomJS浏览器
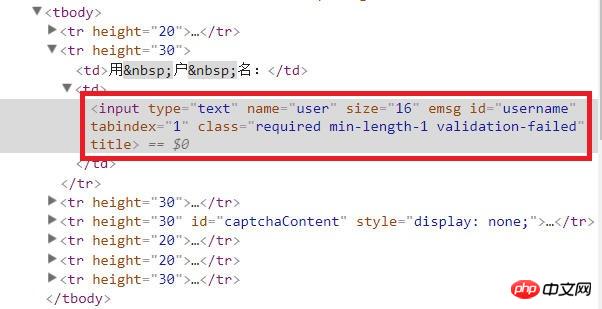
2.在源代码中找到登录时的输入文本框、按钮这些元素
因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
3.考虑如何在程序中找到上述元素
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
4.写代码
import requests import sys import io from selenium import webdriver sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码 #建立Phantomjs浏览器对象,括号里是phantomjs.exe在你的电脑上的路径 browser = webdriver.PhantomJS('d:/tool/07-net/phantomjs-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe') #登录页面 url = r'http://ssfw.xmu.edu.cn/cmstar/index.portal' # 访问登录页面 browser.get(url) # 等待一定时间,让js脚本加载完毕 browser.implicitly_wait(3) #输入用户名 username = browser.find_element_by_name('user') username.send_keys('学号') #输入密码 password = browser.find_element_by_name('pwd') password.send_keys('密码') #选择“学生”单选按钮 student = browser.find_element_by_xpath('//input[@value="student"]') student.click() #点击“登录”按钮 login_button = browser.find_element_by_name('btn') login_button.submit() #网页截图 browser.save_screenshot('picture1.png') #打印网页源代码 print(browser.page_source.encode('utf-8').decode()) browser.quit()
相关推荐:
以上がPython シミュレートされたログインの複数の方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。