
ホームページ >ウェブフロントエンド >jsチュートリアル >Nodejsクローラーを使ったスーパーエージェントとチェリオの使い方
Nodejsクローラーを使ったスーパーエージェントとチェリオの使い方
- 亚连オリジナル
- 2018-06-01 14:38:382582ブラウズ
この記事は、nodejs クローラーの初期トライアル用に、主にスーパーエージェントとチェリオに関する知識を紹介します。非常に優れており、必要な友人は参考にしてください。ここ数日から長い間、nodejs を学び、記事のタイトル、ユーザー名、読み取り数、数値をクロールするクローラ https://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo を作成しましたブログパークのホームページ上のおすすめとユーザーアバターの簡単な概要が完成しました。
これらのポイントを使用してください: 1. ノードのコアモジュール - ファイルシステム 2. http リクエスト用のサードパーティモジュール - スーパーエージェント
3. DOM を解析するサードパーティモジュール - Cheerio
どうぞデモでは簡単な使用法のみを示しています。
準備
npmを使用して依存関係を管理すると、依存関係情報はpackage.jsonに保存されます
//安装用到的第三方模块 cnpm install --save superagent cheerio
必要な機能モジュールを紹介します//引入第三方模块,superagent用于http请求,cheerio用于解析DOM
const request = require('superagent');
const cheerio = require('cheerio');
const fs = require('fs');
リクエスト+解析ページ
クロールしたいブログパークのホームページのコンテンツにアクセスするには、まずホームページのアドレスをリクエストし、返された HTML を取得する必要があります。ここでは、スーパーエージェントを使用して http リクエストを実行します。指定された URL への get リクエスト。リクエストが正しくない場合はエラーが返されます (エラーがない場合、エラーは null または未定義)。res は返されるデータです。
HTMLコンテンツを取得した後、必要なデータを取得する必要があります。このとき、Cheerioを使用してDOMを解析する必要があります。Cheerioは、最初にターゲットのHTMLをロードしてから、それを解析する必要があります。 jquery の API に慣れている場合は、すぐに使い始めることができます。コードサンプルを直接見てくださいrequest.get(url)
.end(error,res){
//do something
}データの保存
上記のDOMを解析した後、必要な情報コンテンツが結合され、画像のURLが取得されたので、それが保存され、コンテンツが保存されます。指定したディレクトリに txt ファイルを作成し、指定したディレクトリに画像をダウンロードします
最初にディレクトリを作成し、nodejs コア ファイル システムを使用します
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
}) 指定したディレクトリを作成したら、データを書き込むことができます。 txt ファイルは既に存在しますので、それを直接書いて使用します。 writeFile()//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
} 画像へのリンクを取得するので、スーパーエージェントを使用して画像をダウンロードしてローカルに保存する必要があります。スーパーエージェントは応答ストリームを直接返すことができ、その後、nodejs パイプラインと連携して画像コンテンツをローカルに直接書き込むことができます//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}Effect
デモを実行して効果を確認すると、データは正常に下降しています
シンプルなもの デモはそれほど厳密ではないかもしれませんが、常にノードに向けた最初の小さなステップです。 上記は私があなたのためにまとめたものです。 関連記事:Vueのルーティング動的リダイレクトとナビゲーションガードの例 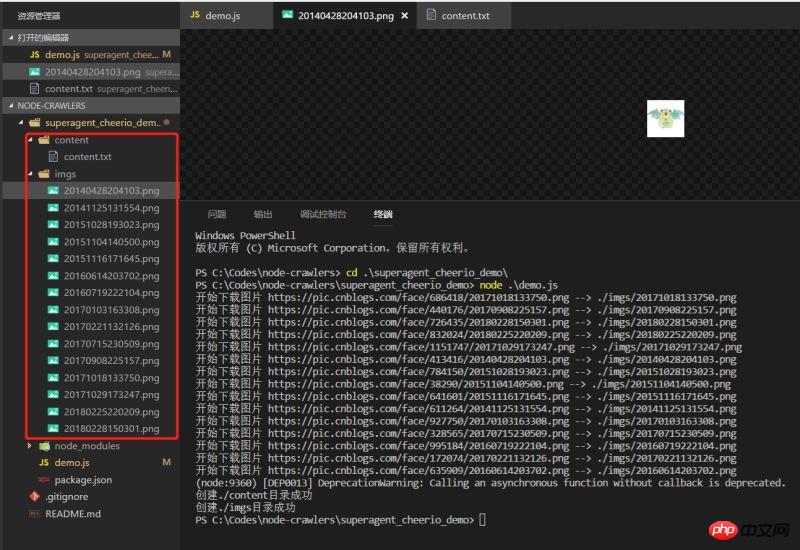
以上がNodejsクローラーを使ったスーパーエージェントとチェリオの使い方の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。