
ホームページ >バックエンド開発 >Python チュートリアル >Python ビデオ クローラーはヘッドライン ビデオのダウンロードを実装します
Python ビデオ クローラーはヘッドライン ビデオのダウンロードを実装します

- 不言オリジナル
- 2018-05-07 13:49:152181ブラウズ
この記事では主に、Python の定期的なマッチング、ネットワーク送信、ファイルの読み取りと書き込み、およびその他の関連操作スキルを含む、見出しビデオをダウンロードする機能を実装する Python ビデオ クローラーを紹介します。この記事では、その例について説明します。 Python ビデオ クローラーのヘッドライン ビデオ機能のダウンロードを実装します。参考までに皆さんと共有してください。詳細は次のとおりです:
1. 需要分析見出しの短いビデオをキャプチャします
アイデア:Web ページのソース コードを分析し、ビデオ リソースを検索して解析しますURL (ソース コードの表示、mp4 の検索)
URL へのリクエストを開始し、バイナリ データを返します バイナリ データをビデオ形式で保存します
http://video.eastday.com/a/170612170956054127565 .html
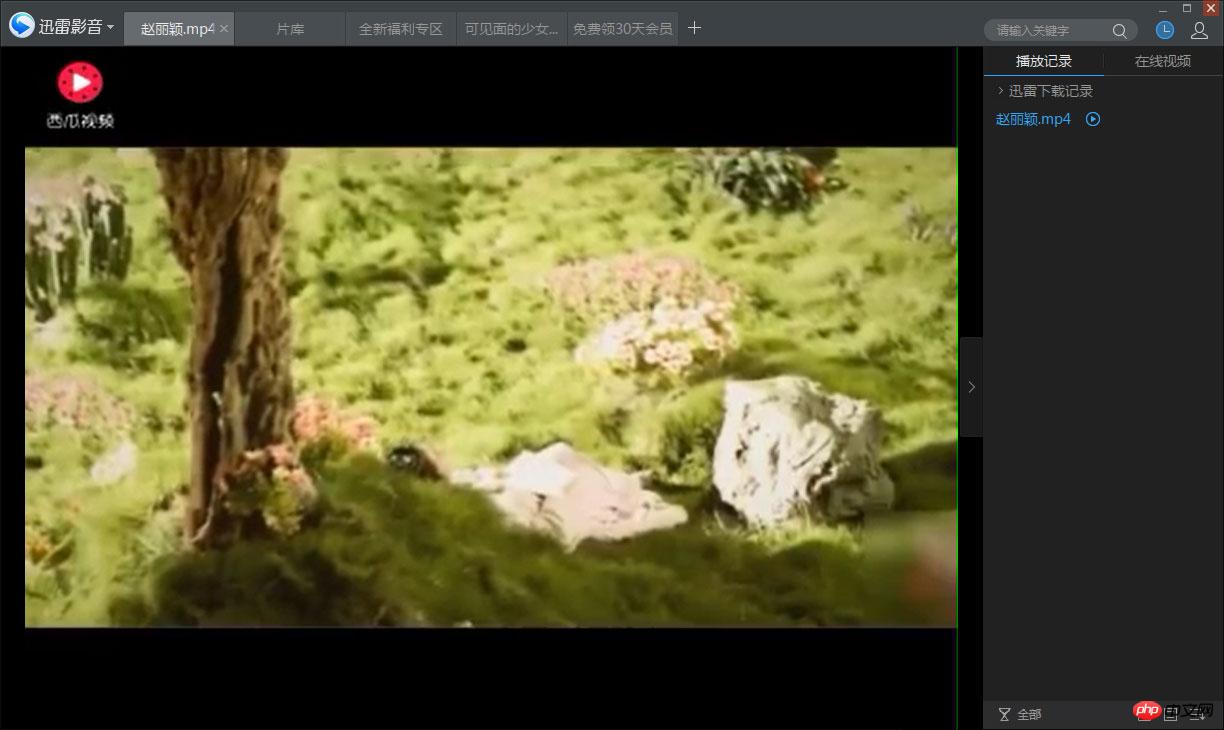
# encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import requests import re import time time1=time.time() main_url = 'http://video.eastday.com/a/170612170956054127565.html' resp = requests.get(main_url) #没有这行,打印的结果中文是乱码 resp.encoding = 'utf-8' html = resp.text link = re.findall(r'var mp4 = "(.*?)";', html)[0] link = 'http:'+link dest_resp = requests.get(link) #视频是二进制数据流,content就是为了获取二进制数据的方法 data = dest_resp.content #保存数据的路径及文件名 path = u'C:/赵丽颖.mp4' f = open(path, 'wb') f.write(data) f.close() time2 = time.time() print u'ok,下载完成!' print u'总共耗时:' + str(time2 - time1) + 's"D:Program FilesPython27python.exe" D:/PycharmProjects/learn2017/testwechat.py
、ダウンロードは完了しました!合計所要時間: 0499992371s
ダウンロードに成功し、再生できます~
終了コード0でプロセスが終了しました
関連推奨事項:
Pythonビデオ高速転送プログラムを作成するビデオキャプチャライブラリ以上がPython ビデオ クローラーはヘッドライン ビデオのダウンロードを実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。