
ホームページ >バックエンド開発 >PHPチュートリアル >PHP クローラーの百万レベルの Zhihu ユーザー データのクローリングと分析
PHP クローラーの百万レベルの Zhihu ユーザー データのクローリングと分析

- 不言オリジナル
- 2018-04-20 11:58:201931ブラウズ
この記事の内容は、PHP クローラーによる 100 万レベルの Zhihu ユーザー データのクローリングと分析に関するもので、必要な友人に参考にしていただけます。
この記事は主にPHP百万レベルのZhihuユーザーデータのクローリングと分析に関する関連情報を紹介します
PHP5.6 以降をインストールします。
curl 拡張機能と pcntl 拡張機能をインストールします。
-
PHPのcurl拡張機能を使用してページデータを取得します
PHPのcurl拡張機能は、さまざまなタイプのプロトコルを使用してさまざまなサーバーに接続して通信できるようにするPHPによってサポートされるライブラリです。 - このプログラムは Zhihu ユーザーデータをキャプチャします。ユーザーの個人ページにアクセスできるようにするには、ユーザーはアクセスする前にログインする必要があります。ブラウザ ページ上のユーザー アバター リンクをクリックしてユーザーのパーソナル センター ページにアクセスすると、ユーザーの情報が表示されるのは、リンクをクリックすると、ブラウザがローカル Cookie を取得して一緒に送信するのに役立つからです。新しいページに移動すると、ユーザーの個人センター ページに入ることができます。したがって、個人ページにアクセスする前に、ユーザーの Cookie 情報を取得し、その Cookie 情報を各 Curl リクエストに含める必要があります。 Cookie 情報の取得に関しては、次のページで自分の Cookie 情報を確認できます:
このフォームを 1 つずつコピーします。クッキー文字列を形成します。この Cookie 文字列は、リクエストの送信に使用できます。
最初の例:
|
1 2 3 4 5 6 7 8 9 |
|
上記のコードを実行して、mora-huユーザーの個人センターページを取得します。この結果を使用し、正規表現を使用してページを処理すると、名前、性別、およびキャプチャする必要があるその他の情報を取得できます。
1. 写真のホットリンク対策
返された結果を正規化して個人情報を出力する場合、ページ上に出力するときにユーザーのアバターを開けないことがわかりました。情報を確認したところ、Zhihu が写真をホットリンクから保護していたためであることがわかりました。解決策は、画像をリクエストするときにリクエスト ヘッダーでリファラーを偽造することです。
正規表現を使用して画像へのリンクを取得した後、今度は画像リクエストのソースを提示して、リクエストが Zhihu Web サイトから転送されたことを示します。具体的な例は次のとおりです。
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
function getImg($url, $u_id)
{
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg';
}
if (empty($url))
{
return '';
}
$context_options = array(
'http' =>
array(
'header' => "Referer:http://www.zhihu.com"//带上referer参数
)
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';
}2. より多くのユーザーをクロールする
個人情報を取得したら、ユーザーのフォロワーとフォローしているユーザーのリストにアクセスして、より多くのユーザー情報を取得する必要があります。次に、レイヤーごとにアクセスします。ご覧のとおり、パーソナル センター ページには次の 2 つのリンクがあります。
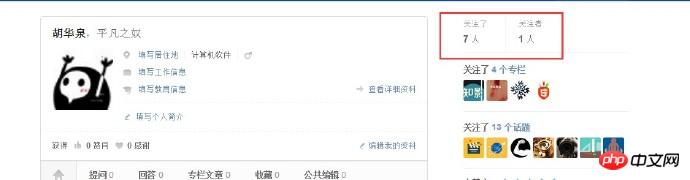
ここには 2 つのリンクがあり、1 つはフォローされており、もう 1 つはフォロワーです。例として「フォローされている」リンクを取り上げます。通常のマッチングを使用して、対応するリンクを照合します。URL を取得した後、curl を使用して Cookie を取得し、別のリクエストを送信します。ユーザーがフォローしたリストページを取得すると、次のページを取得できます:
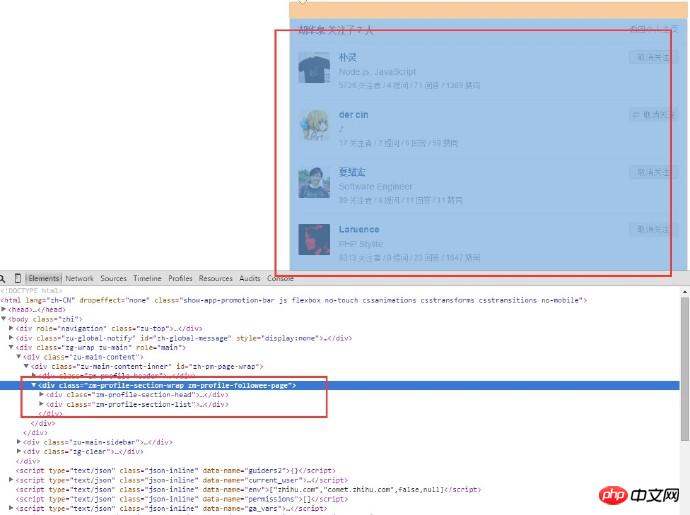
ユーザーの情報のみを取得する必要があるため、ページの HTML 構造を分析します。この作品のフレーム、コンテンツとユーザー名はすべてここにあります。ユーザーがフォローしているページの URL は次のとおりであることがわかります。

異なるユーザーの URL はほぼ同じですが、違いはユーザー名にあります。通常のマッチングを使用してユーザー名のリストを取得し、URL を 1 つずつ入力してから、リクエストを 1 つずつ送信します (もちろん、1 つずつ実行すると時間がかかります。以下に解決策があります。これについては後で説明します)。新しいユーザーのページに入ったら、上記の手順を繰り返し、必要なデータ量に達するまでこのループを続けます。
3. Linux 統計ファイル番号
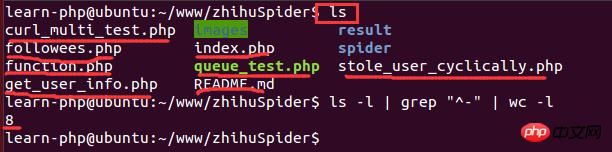
スクリプトをしばらく実行した後、データ量が比較的多い場合、取得した画像の数を確認する必要があります。フォルダーを開いて写真の枚数を確認してください。スクリプトは Linux 環境で実行されるため、Linux コマンドを使用してファイルの数をカウントできます:
1 |
ls-l | grep"^-"wc -l |
その中で、ls -l はディレクトリ内のファイル情報の長いリスト出力です (ここでのファイルはディレクトリ、リンク、デバイス ファイルなどです)。 grep "^-" は長いリストの出力情報をフィルターします。 " 一般ファイルのみを保持する場合、ディレクトリのみを保持する場合は "^d"; wc -l は統計出力情報の行数です。以下は実行例です:
4. MySQL への挿入時の重複データの処理
プログラムを一定期間実行すると、多くのユーザーのデータが重複していることがわかります。 , そのため、処理するには重複したユーザー データ時間を挿入する必要があります。解決策は次のとおりです:
1) データベースに挿入する前に、データがデータベースに既に存在するかどうかを確認します
2) 一意のインデックスを追加し、INSERT INTO...ON DUPLICATE KEY UPDATE...を使用します。 ) 一意のインデックスを追加し、挿入します INSERT IGNORE INTO を使用します...
4) 一意のインデックスを追加し、挿入時に REPLACE INTO を使用します...
最初のオプションは最も単純ですが、最も効率が低いものでもあるため、採用されました。 2 番目と 4 番目の解決策の実行結果は同じです。違いは、同じデータが見つかった場合、INSERT INTO ... ON DUPLICATE KEY UPDATE は直接更新されるのに対し、REPLACE INTO は最初に古いデータを削除してから新しいデータを挿入することです。このプロセス中、インデックスを再メンテナンスする必要があるため、速度が遅くなります。そこで私は 2 と 4 の間で 2 番目のオプションを選択しました。 3 番目のオプション INSERT IGNORE は、INSERT ステートメントの実行時に発生するエラーを無視し、構文の問題は無視しませんが、主キーの存在を無視します。この場合、INSERT IGNORE を使用する方が適切です。最終的に、データベースに記録される重複データの数を考慮して、プログラムでは 2 番目の解決策が採用されました。
5.curl_multiを使用してマルチスレッドのページキャプチャを実現しますデータをキャプチャするために単一のプロセスと単一のcurlを使用し始めたところ、一晩電話を切った後、速度が非常に遅くなりました。 2W のデータしかキャプチャできないため、新しいユーザー ページに入ってカール リクエストを行うときに複数のユーザーを同時にリクエストできるかどうかを考えました。後で、curl_multi という優れものを発見しました。 curl_multi などの関数は、複数の URL を 1 つずつ要求するのではなく、同時に要求できます。これは、実行のために複数のスレッドを開く Linux システムのプロセスの機能と似ています。以下は、curl_multi を使用してマルチスレッド クローラーを実装する例です:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
$mh = curl_multi_init(); //返回一个新cURL批处理句柄
for ($i = 0; $i < $max_size; $i++)
{
$ch = curl_init(); //初始化单个cURL会话
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄
}
$user_arr = array();
do {
//运行当前 cURL 句柄的子连接
while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);
if ($cme != CURLM_OK) {break;}
//获取当前解析的cURL的相关传输信息
while ($done = curl_multi_info_read($mh))
{
$info = curl_getinfo($done['handle']);
$tmp_result = curl_multi_getcontent($done['handle']);
$error = curl_error($done['handle']);
$user_arr[] = array_values(getUserInfo($tmp_result));
//保证同时有$max_size个请求在处理
if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list))
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch);
$i++;
}
curl_multi_remove_handle($mh, $done['handle']);
}
if ($active)
curl_multi_select($mh, 10);
} while ($active);
curl_multi_close($mh);
return $user_arr; |
6. HTTP 429 リクエストが多すぎます
curl_multi関数を使用すると、同時に複数のリクエストを送信できますが、実行プロセス中に同時に200のリクエストが送信されることが判明しました。多くのリクエストが返されない、つまりパケットロスが発見されたケース。さらに分析するには、curl_getinfo 関数を使用して、各リクエスト ハンドル情報を出力します。この関数は、HTTP 応答情報を含む連想配列を返します。フィールドの 1 つは、リクエストによって返された HTTP ステータス コードを表します。多くのリクエストの http_code は 429 であることがわかりました。このリターン コードは、送信されたリクエストが多すぎることを意味します。 Zhihu がクローラー対策保護を実装していると推測したため、他の Web サイトでテストしたところ、一度に 200 件のリクエストを送信しても問題がないことがわかり、Zhihu がこの点で保護を実装していることが証明されました。 1 回限りのリクエストの数には制限があります。そこで、リクエストの数を減らし続けたところ、5 回の時点ではパケットロスが発生していないことがわかりました。このプログラムでは一度に最大 5 つのリクエストしか送信できないことがわかりますが、それほど多くはありませんが、小さな改善です。
7. Redisを使用して訪問したユーザーを保存する
ユーザーを取得するプロセス中に、重複したデータが処理されているにもかかわらず、一部のユーザーがすでに訪問しており、そのフォロワーとフォローしているユーザーがすでに取得されていることがわかりました。データベース レベルでは、プログラムは引き続きカールを使用してリクエストを送信するため、繰り返しリクエストを送信すると、大量のネットワーク オーバーヘッドが繰り返し発生します。もう 1 つは、キャプチャするユーザーを次の実行のために 1 つの場所に一時的に保存する必要があることです。後で、マルチプロセスで複数のプロセスを追加する必要があることがわかりました。プログラミングでは、サブプロセスはプログラム コード、関数ライブラリを共有しますが、プロセスで使用される変数は他のプロセスで使用される変数とはまったく異なります。異なるプロセス間の変数は分離されており、他のプロセスから読み込むことができないため、配列は使用できません。そこで、Redisキャッシュを利用して、処理済みのユーザーとキャプチャ対象のユーザーを保存することを考えました。このようにして、実行が完了するたびに、ユーザーは selected_request_queue キューにプッシュされ、キャプチャされるユーザー (つまり、各ユーザーのフォロワーとフォローされているユーザーのリスト) が request_queue にプッシュされ、その後、それぞれのキューにプッシュされます。実行すると、ユーザーは、ready_request_queue キューにプッシュされ、ready_request_queue にあるかどうかを判断し、存在する場合は次のキューに進み、そうでない場合は実行を続行します。
PHP での Redis の使用例:
|
1 2 3 4 5 6 7 8 |
<?php
$redis = new Redis();
$redis->connect('127.0.0.1', '6379');
$redis->set('tmp', 'value');
if ($redis->exists('tmp'))
{
echo $redis->get('tmp') . "\n";
} |
8. PHPのpcntl拡張機能を使用してマルチプロセスを実装します
ユーザー情報のマルチスレッドキャプチャを実装するためにcurl_multi関数に切り替えた後、プログラムは一晩実行され、最終的に取得されたデータは10Wでした。まだ理想的な目標を達成できず、最適化を続けましたが、その後、PHP にマルチプロセス プログラミングを実現できる pcntl 拡張機能があることを発見しました。マルチプログラムプログラミングの例を次に示します:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//PHP多进程demo
//fork10个进程
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
echo "child process $i running\n";
//子进程执行完毕之后就退出,以免继续fork出新的子进程
exit($i);
}
}
//等待子进程执行完毕,避免出现僵尸进程
while (pcntl_waitpid(0, $status) != -1) {
$status = pcntl_wexitstatus($status);
echo "Child $status completed\n";
} |
9、在Linux下查看系统的cpu信息
实现了多进程编程之后,就想着多开几条进程不断地抓取用户的数据,后来开了8调进程跑了一个晚上后发现只能拿到20W的数据,没有多大的提升。于是查阅资料发现,根据系统优化的CPU性能调优,程序的最大进程数不能随便给的,要根据CPU的核数和来给,最大进程数最好是cpu核数的2倍。因此需要查看cpu的信息来看看cpu的核数。在Linux下查看cpu的信息的命令:
1 |
cat /proc/cpuinfo |
結果は以下の通りです:
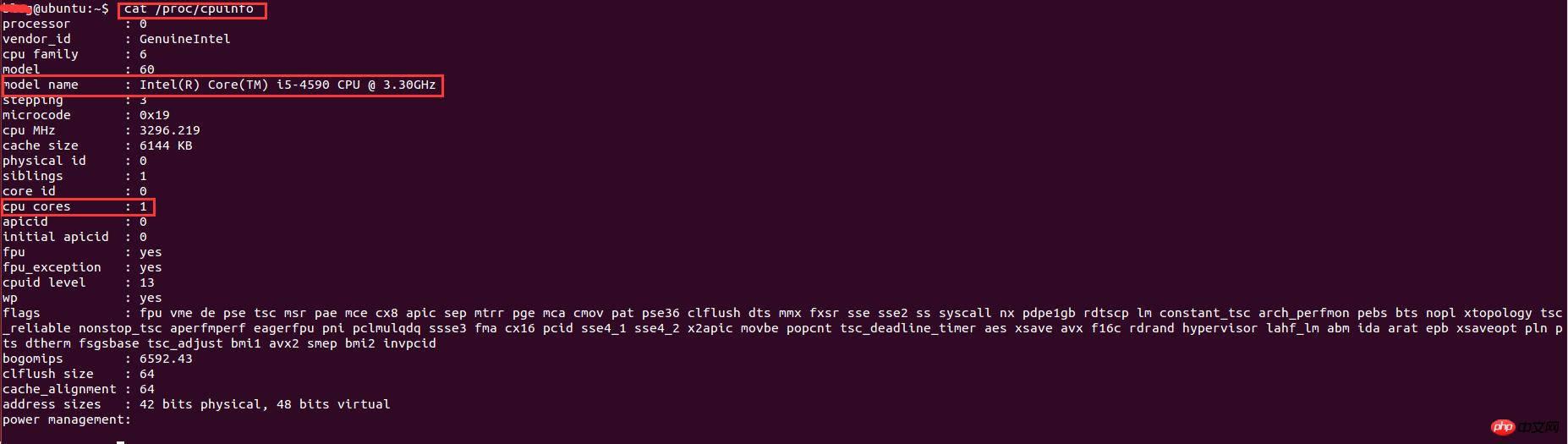
このうち、モデル名はCPUの種類情報を表し、CPUコアはCPUコアの数を表します。ここでのコア数は 1 です。仮想マシンで実行されているため、割り当てられる CPU コアの数が比較的少なく、2 つのプロセスしか開くことができません。最終結果は、わずか 1 週間で 110 万件のユーザー データが収集されたということです。
10. マルチプロセスプログラミングにおける Redis と MySQL の接続の問題
マルチプロセス条件下で、プログラムが一定期間実行された後、データをデータベースに挿入できないことがわかります。このように、mysql の接続が多すぎるというエラーが報告されます。
次のコードは実行に失敗します:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<?php
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
$redis = PRedis::getInstance();
// do something
exit;
}
} |
基本的な理由は、各子プロセスが作成されるときに、親プロセスの同一のコピーを継承しているためです。オブジェクトはコピーできますが、作成された接続を複数の接続にコピーすることはできません。その結果、各プロセスが同じ Redis 接続を使用して独自の処理を実行し、最終的には説明できない競合が発生します。
解決策: >プログラムは、プロセスをフォークする前に親プロセスが Redis 接続インスタンスを作成しないことを完全には保証できません。したがって、この問題を解決する唯一の方法は、子プロセス自体によって解決することです。想像してみてください、子プロセスで取得されたインスタンスが現在のプロセスにのみ関連している場合、この問題は存在しません。したがって、解決策は、redis クラスのインスタンス化の静的メソッドをわずかに変更し、それを現在のプロセス ID にバインドすることです。
変更されたコードは次のとおりです:
|
1 2 3 4 5 6 7 8 9 10 |
<?php
public static function getInstance() {
static $instances = array();
$key = getmypid();//获取当前进程ID
if ($empty($instances[$key])) {
$inctances[$key] = new self();
}
return $instances[$key];
} |
11. PHP統計スクリプトの実行時間
各プロセスにどれくらいの時間がかかるかを知りたいので、スクリプトの実行時間をカウントする関数を書きます:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function microtime_float()
{
list($u_sec, $sec) = explode(' ', microtime());
return (floatval($u_sec) + floatval($sec));
}
$start_time = microtime_float();
//do something
usleep(100);
$end_time = microtime_float();
$total_time = $end_time - $start_time;
$time_cost = sprintf("%.10f", $total_time);
echo "program cost total " . $time_cost . "s\n"; |
上記はこの記事の全内容ですので、ご参考になれば幸いです。
関連する推奨事項:
以上がPHP クローラーの百万レベルの Zhihu ユーザー データのクローリングと分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。