
ホームページ >バックエンド開発 >Python チュートリアル >Python を使用して NetEase Cloud Music で人気のあるコメントをクロールする方法
Python を使用して NetEase Cloud Music で人気のあるコメントをクロールする方法

- 零到壹度オリジナル
- 2018-04-11 17:33:253394ブラウズ
この記事の内容は、Python を使用して NetEase Cloud Music で人気のコメントをクロールする方法を共有することです。必要な友人は参考にしてください。
最近、私はテキストマイニングに関連するコンテンツを勉強しています。 良い女はストローなしでは食事を作れないと言われています。 テキスト分析を行うには、まずテキストが必要です。テキストを取得するには、インターネットから既製のテキスト文書をダウンロードしたり、サードパーティが提供する API を介してデータを取得したりするなど、さまざまな方法があります。しかし、データを取得するための直接ダウンロード チャネルや API がないため、必要なデータを直接取得できない場合があります。では、このとき何をすべきでしょうか?より良い方法は、Web クローラーを使用することです。これは、ユーザーになりすまして必要なデータを取得するコンピューター プログラムを作成することです。 コンピュータの効率を利用して、データを簡単かつ迅速に取得できます。
クローラーについて
では、クローラーはどうやって書くのでしょうか? Java、php、Python など、クローラーの作成に使用できる言語は多数ありますが、私は個人的には Python を使用することを好みます。 Python には強力なネットワーク ライブラリが組み込まれているだけでなく、多くの優れたサードパーティ ライブラリがホイールを直接構築しているため、それを使用するだけでクローラーを作成できます。実際には 10 行未満の Python コードで小さなクローラーを作成できると言っても過言ではありませんが、他の言語を使用するとさらに多くのコードを作成する必要がある可能性があります シンプルで理解しやすいという点です。 Pythonの大きな利点。
(念のため!!! これはソフトな記事ではありません。宣伝です!あくまで私の個人的な意見ですので、批判しないでください!)。多くの「いいね!」を獲得した曲の下には、いくつかのコメントが表示されることがあります。さらに、NetEase Cloud Musicは数日前に厳選したユーザーレビューを地下鉄に掲載し、NetEase Cloud Musicのレビューが再び人気になりました。したがって、NetEase Cloud のコメントを分析し、パターン、特にいくつかのホットなコメントの共通の特徴を発見したいと考えています。この目的で、NetEase Cloud のコメントをクロールし始めました。
Pythonには、urllibとurllib2という2つの組み込みネットワークライブラリがありますが、これら2つのライブラリは特に使いやすいわけではないので、ここでは広い人気のあるサードパーティ ライブラリのリクエスト。リクエストを使用すると、エージェントのセットアップやログインのシミュレーションなど、より複雑なクローラーの作業をわずか数行のコードで実現できます。 pipをインストールしている場合は、pip install requestを使用してインストールしてください。 中国語のドキュメントアドレスこちら http://docs.python-requests.org/zh_CN/latest/user/quickstart.html 何を持っていますか? 質問がある場合は、非常に詳細な説明が記載されている公式ドキュメントを参照してください。 urllib と urllib2 という 2 つのライブラリについても、今後機会があれば紹介します。 動作原理 クローラーを正式に紹介し始める前に、まずクローラーの基本的な動作原理について話しましょう。ブラウザを開いて特定の URL にアクセスすると、基本的に、リクエスト に一定量の情報を送信すると、サーバーはリクエストを受信した後、リクエストに従ってデータを返し、ブラウザを通じてデータを解析して目の前に表示します。 コードを使用する場合、ブラウザのこのステップをスキップし、特定のデータをサーバーに直接送信し、サーバーから返されたデータを取得して必要な情報を抽出する必要があります。 必要がある場合があります。
もサービスに送信されます。したがって、サーバーは、要求された ID 証明書を確認すると、通常のブラウザーを介してアクセスしていることを認識し、データを素直に返します。 模擬ログイン したがって、私たちのプログラムはブラウザのようになり、リクエストを送信するときに私たちの身元を示すこの情報をもたらし、データをスムーズに取得できるようにする必要があります。場合によっては、データを取得するためにログインする必要があるため、ログインをシミュレートする必要があります。 基本的に、ブラウザ経由でログインするということは、何らかのフォーム情報 (ユーザー名、パスワード、その他の情報を含む) をサーバーに送信することを意味し、サーバーがそれを検証した後、同じことがスムーズにログインできます。アプリケーションプログラム ブラウザ どのようなデータを投稿しても、そのまま送信することができます。 模擬ログインについては、後ほど具体的にご紹介します。もちろん、一部の Web サイトではクロール防止対策 が設定されているため、物事がそれほどスムーズにいかないこともあります。たとえば、アクセスが速すぎると、IP アドレスがブロックされることがあります (通常は Douban)。この時点でも、プロキシ サーバーを設定する必要があります。つまり、1 つの IP がブロックされている場合は、別の IP に変更します。これを行う方法については、後で説明します。 Tips 最後に、クローラーを作成するプロセスで非常に役立つと思われるちょっとしたトリックを紹介します。 Firefox または Chrome を使用している場合は、開発者ツール (chrome) または Web コンソール (firefox) という場所に気づいたかもしれません。このツールを使用すると、Web サイトにアクセスしたときにブラウザーがどのような情報を送信し、サーバーがどのような情報を返すかが明確にわかるため、この情報がクローラーを作成するための鍵となります。以下で、それがどれほど役立つかを見ていきます。 コメントをクロールする方法 まず、NetEase Cloud MusicのWebバージョンを開き、曲を選択してWebページを開きます。ここではジェイ・チョウの「Sunny Day」を例に挙げます。以下に示すように:
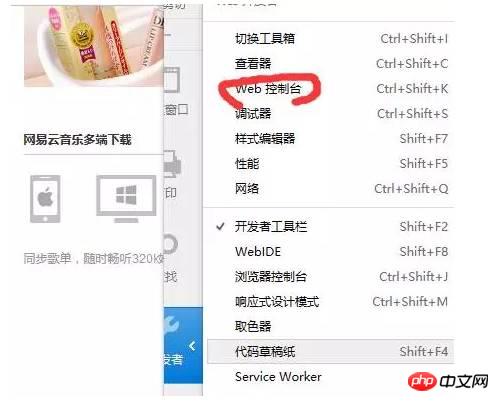
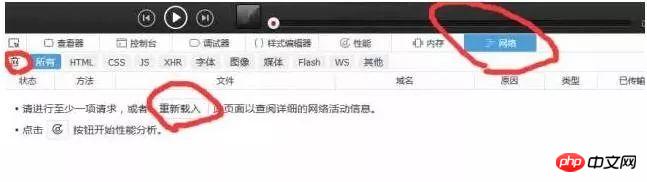
次に、以下に示すように、Web コンソールを開きます (Chrome の開発者ツールを開きます。他のブラウザでも同様であるはずです)。 次に、この時点でネットワークをクリックし、すべての情報をクリアしてから、[再送信] (ブラウザを更新するのと同じ) をクリックする必要があります。これにより、ブラウザが送信する情報を直感的に確認でき、サーバーの応答 どのような情報。以下に示すように:
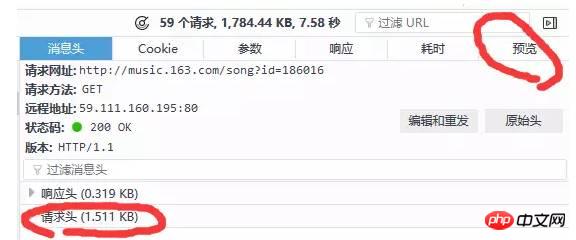
更新後に取得されたデータは次のとおりです ブラウザが多くの情報を送信していることがわかります。それでどれが私たちは何を望んでいますか?ここで、ステータス コード によって予備的な判断を行うことができます。ステータス コード (ステータス コード) は、サーバー リクエストのステータスを示します。ここで、ステータス コード 200 はリクエストが正常であることを意味し、304 はリクエストが正常であることを意味します。異常 (ステータスコードの種類はたくさんあります。詳しく知りたい場合は自分で検索してください。ここでは 304 の具体的な意味には触れません)。したがって、通常はステータス コード 200 のリクエストのみを確認する必要があります。また、右側の列のプレビューを通じて、サーバーがどのような情報を返すかを大まかに観察する (または応答を表示する) ことができます。以下に示すように:
という 2 つのリクエスト メソッドがあります。もう 1 つ注目する必要があるのは、user-Agent (顧客端末) を含むリクエスト ヘッダーです。一般に、get メソッドでも post メソッドでも、ヘッダー情報を持ってきます。ヘッダー情報は次のとおりです: さらに、get リクエストの場合、通常、リクエストパラメータは直接 ? に変更されることに注意してください。パラメータ1=値1&パラメータ2=値2などはこのフォームで送信されるため、追加のリクエストパラメータを取得する必要はありません。通常、投稿リクエストではパラメータをURLに直接配置するのではなく、追加のパラメータを取得する必要があります。パラメータ列に注目してください。注意深く検索した結果、以下に示すように、リクエスト http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 内で、最終的に元のコメント関連のリクエストが見つかりました。
この時点で、方向性は決まりました。つまり、params と encSecKey の 2 つのパラメーター値を決定するだけで済みます。この問題は、午後ずっと私を悩ませてきました。時間はかかりましたが、これら 2 つのパラメータの暗号化方法はまだわかりません。しかし、パターンを発見しました。http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= の後の数字。 R_SO_4_ はこの曲の ID 値であり、別の曲の Param と encSecKey の値は、A などの曲のこれら 2 つのパラメータ値が曲 B に渡される場合、ページ数が同じ場合、このパラメータはユニバーサルです。つまり、A の最初のページです。2 つのパラメータ値を他の曲の 2 つのパラメータに渡すと、対応する曲の最初のページのコメントを取得できます。 2ページ目、3ページ目なども同様です。 しかし、残念ながら、ページ番号パラメータが異なると、限られた数のページしかクロールできません(もちろん、必要に応じて、コメントの合計数と人気のあるコメントをクロールするだけでも十分です)。すべてのデータをキャプチャしたい場合は、これら 2 つのパラメータ値の暗号化方法を理解する必要があります。 友人 が書いた方法に従って、いくつかの変更を加えました。すべてのコメントを正常に取得しました。 Zhihu@平胸の小さな妖精に感謝の意を表したいと思います。
スペースで区切られていることに注意してください。各行には、 自分でキャプチャするコードを実行するときは、スレッドを開きすぎて NetEase Cloud サーバーに過度の負荷をかけないよう注意してください 付録: 心温まるコメント
しかし、問題は、サーバーが送信したリクエストを検証する必要がある場合があり、リクエストが不正であると判断した場合、データが返されなかったり、間違ったデータが返されたりすることです。したがって、この状況を回避するには、サーバーからの応答を正常に取得するために、
どうやって変装するの?
これは、ユーザーがブラウザーを介して Web ページにアクセスする場合と、私たちがプログラムを介して Web ページにアクセスする場合の違いによって異なります。
一般に、ブラウザを通じてウェブページにアクセスすると、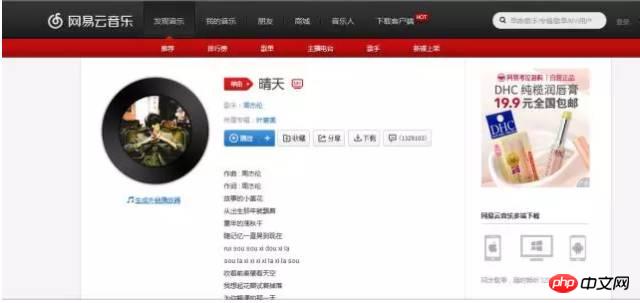

これら 2 つのメソッドを組み合わせることで、分析したいリクエストを素早く見つけることができます。図 5 のリクエスト URL 列がリクエストする URL であることに注意してください。 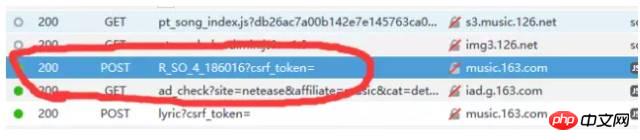
このリクエストをクリックすると、リクエストに 2 つのパラメータがあることがわかります。1 つは params で、もう 1 つは encSecKey です。非常に長いので、暗号化されているように感じられるはずです。以下に示すように: 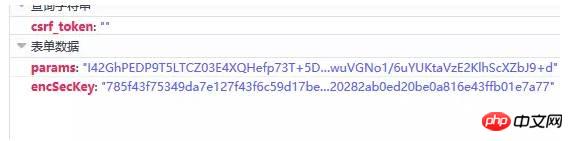
サーバーから返されたコメントに関連するデータは、非常に豊富な情報 (コメント投稿者に関する情報、コメント日付など) を含む json 形式です。 、いいねの数、コメントの内容など)、以下の図 9 に示すように: (実際、hotComments は人気のあるコメントであり、comments はコメントの配列です)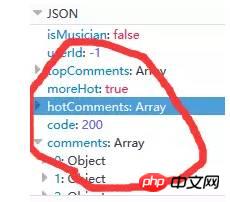
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py '''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章
来源:知乎
''' from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/' }
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:
(评论页数-1)*20,total第一页为true,其余页为false # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第一个参数 second_param = "010001"
# 第二个参数
# 第三个参数 third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数 forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数 def get_params(page):
# page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u""
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u""
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))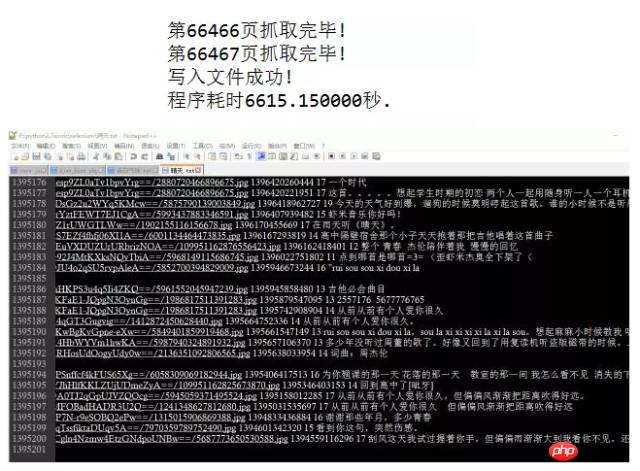 が含まれています。学生
が含まれています。学生
(サーバーがデータを返すのが非常に遅い期間がありました。アクセスが制限されていたかどうかはわかりますが、後で回復しました。後ほど、私自身がコメントデータを視覚的に分析するかもしれませんので、お楽しみに! 

以上がPython を使用して NetEase Cloud Music で人気のあるコメントをクロールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。